Strix Halo这个产品距离正式发布已经过去一年左右。作为一款原本定位为工作站、轻薄游戏等场景的高端PC产品,AMD在消费级产品中的品牌形象、昂贵的定价以及需要OEM单独开案等问题导致其主线产品推进的并不算太成功,市面上的大部分存在感都阴差阳错地来自于一些偏门的“AI”相关的产品。
本站在去年上半年首发不久后已经粗略地做过一些Strix Halo平台的LLM测试,当时的结论是这样的LPDDR平台与前年的M4 Pro Mac Mini一样有不少尴尬的问题。
不过,两年以来在这期间整个LLM生态发生了天翻地覆的变化,有一个好消息和一个坏消息:
- 好消息:适合128GB LPDDR平台的开放权重MoE模型越来越多。例如GPT OSS,GLM Air/V,MiniMax M2.x,Qwen3 235B等
- 坏消息:reasoning与agent用途的比重越来越高,对超长上下文prefill/decode性能、显存容量要求都提升了一个等级
对于MoE模型,不仅是experts激活量较为稀疏的特性使其适合相对大容量、小带宽内存的设备进行推理,同样由于其对attention权重和k/v cache的密集访问也适合将attention与k/v cache放在高内存带宽的设备上(某种意义上是一种AF分离)。
本文借助GPT-OSS 120B模型的性能测试探讨Strix Halo结合小容量高带宽的独立显卡来改善上述场景的使用体验,尝试尽可能维持低门槛、低成本。除此之外,本文最后也会提供一些运行更大模型的性能参考。
让我看看是谁说Strix Halo搭配独显不合适的?
在 llama.cpp 中,我们主要可以通过 tensor override 功能来将一部分权重分派到特定设备上,使用的主要参数是 -dev ROCmX,ROCmY -ts 1,0 -ot exps=ROCmY ,其中X、Y分别是dGPU与iGPU的设备编号,可由 llama-server –list-devices 列出。
这样可以实现将稀疏的experts的计算指定到带宽更小、内存容量更大的iGPU设备;其余容量较小但对单位容量下的带宽要求更高的attention权重与k/v cache等依然在dGPU设备上运行。
当二者同属CUDA或同属ROCm后端时,这些tensor之间传递数据支持通过CUDA/HIP P2P拷贝完成,可以显著降低延迟与性能开销。因此需要使用amdgpu-dkms或者启用主线内核的CONFIG_HSA_AMD_P2P才能获得最佳的性能。实测如果使用没有打开AMD GPU P2P支持的主线内核驱动(如大部分发行版的官方内核),性能会降低将近一半。
测试环境
- AMD Ryzen AI Max+ 395, 128 GB LPDDR5X-8000
- AMD Radeon Pro W7900 48G @ PCIe 4.0 x4 oculink
仅使用少量显存,可以认为是低功耗版 7900 XTX 24G - UEFI菜单内为iGPU分配512M显存
- 使用amd_iommu=off amdgpu.gttsize=114688 amdttm.pages_limit=29360128 等内核参数实现无损耗的112G共享显存分配
- Debian 13.2, Linux 6.17.13 (Debian backports), ROCm 7.0.3, amdgpu-dkms 6.16.6.30200100-2255209.24.04
- llama.cpp base commit d2ff4e, GGML_HIP + GGML_HIP_ROCWMMA_FATTN
其中 llama.cpp 引入了以下显著影响测试性能的第三方修改
- 为RDNA3优化的flash attention patch提升长上下文性能
- 为 –override-tensor 场景强制启用async pipeline parallel,提升约5%左右(llama-context.cpp 中直接将bool pipeline_parallel设置为true)
所有的模型统一测试mxfp4_moe版本,即experts为mxfp4,其余部分为q8_0。同时使用 -ctk q8_0 -ctv q8_0 量化k/v cache降低上下文的显存开销。
测试数据
使用 llama-batched-bench 测试工具,通过变更 -dev/-ts/-ot 参数来调整不同的设备配置。
示例
- llama-batched-bench -dev ROCm0,ROCm1 -ot exps=ROCm1 -ts 1,0 -m ~/models/gpt-oss-120b.gguf -fa on -ub 2048 -npp 0,2048,4096,8192,16384,24576,32768,65536,98304 -ntg 128 -npl 1 -c 99000 -ctk q8_0 -ctv q8_0 –no-mmap
测试从0-96K的单请求prefill/decode性能 - llama-batched-bench -dev ROCm0,ROCm1 -ot exps=ROCm1 -ts 1,0 -m ~/models/gpt-oss-120b.gguf -fa on -ub 2048 -npl 1,2,4,8,16 -npp 0 -ntg 128 -c 68000 -ctk q8_0 -ctv q8_0 –no-mmap
测试0上下文,batch size = 1/2/4/8/16的decode性能 - llama-batched-bench -dev ROCm0,ROCm1 -ot exps=ROCm1 -ts 1,0 -m ~/models/gpt-oss-120b.gguf -fa on -ub 2048 -npl 1,2,4,8,16 -npp 32768 -ntg 128 -c 560000 -ctk q8_0 -ctv q8_0 –no-mmap
测试32K上下文,batch size = 1/2/4/8/16的decode性能
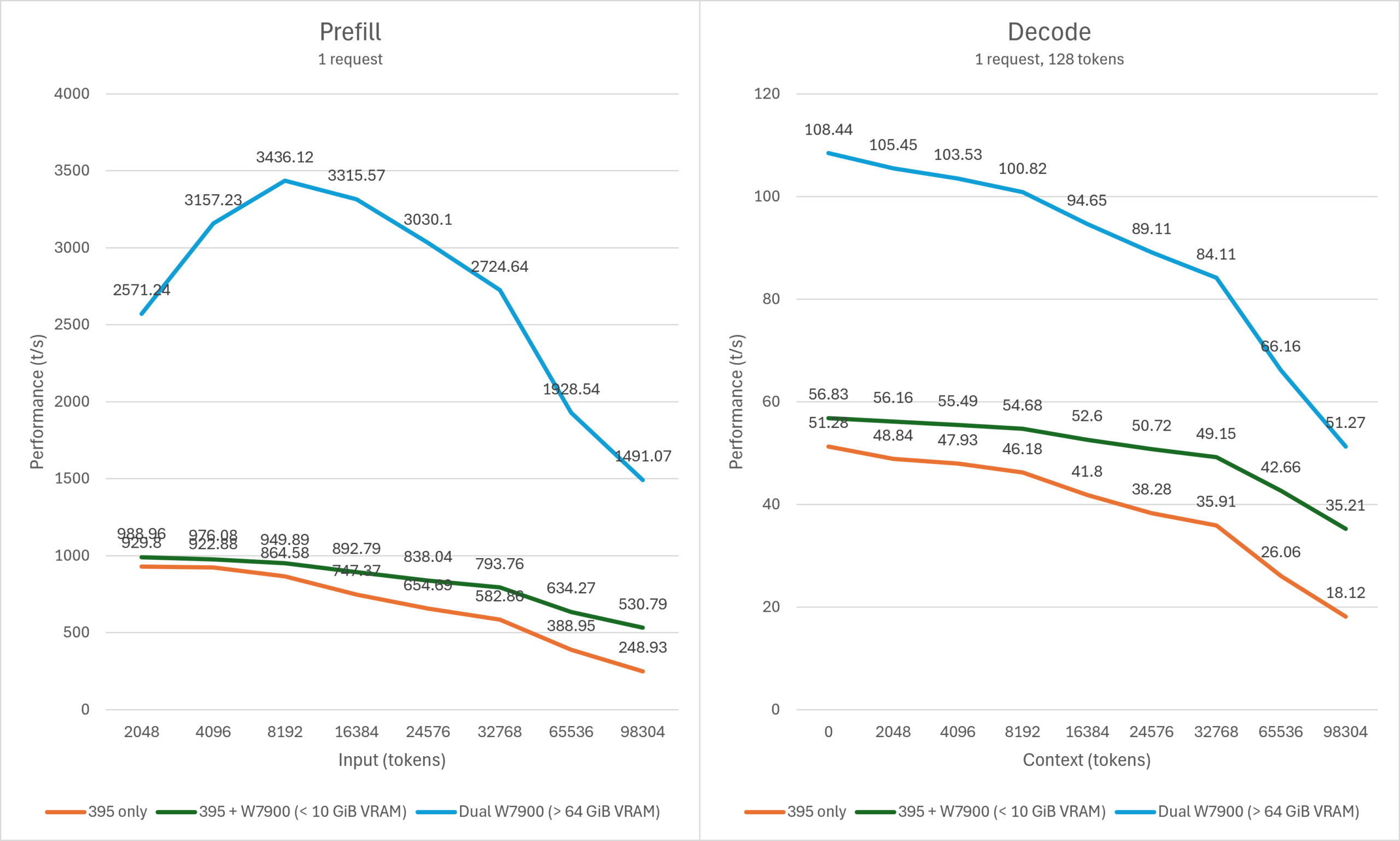
GPT OSS 120B
单用户
并发
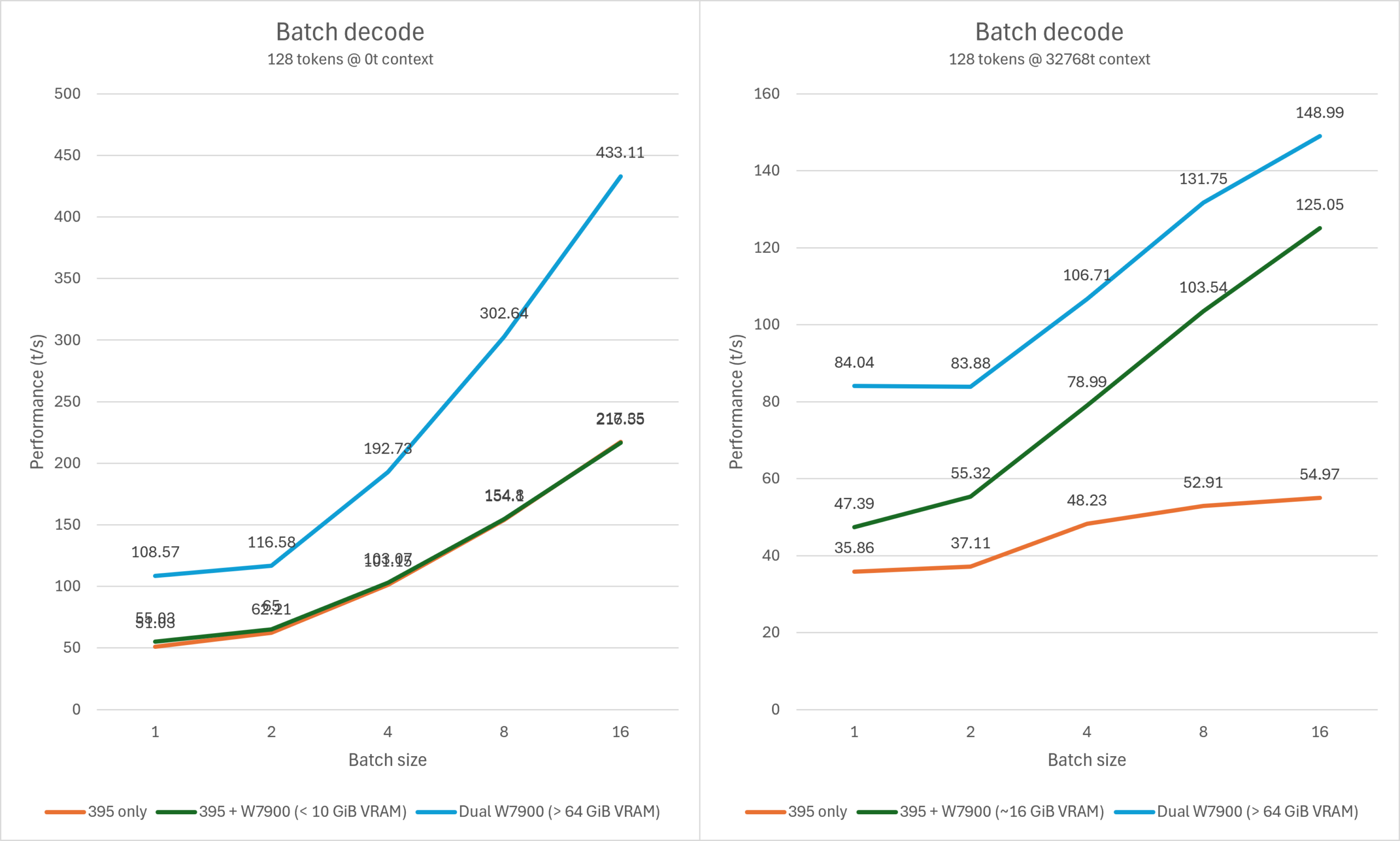
对于上下文较短的场景,使用Strix Halo+Navi31运行GPT OSS 120B混合推理的性能提升非常微小,并且依然远逊于纯独显推理。但在64K – 96K上下文的场景下,由于attention的开销持续上升,Strix Halo+Navi31的组合提升越发明显,仅需10G高速显存即可大幅度加速推理最高可达一倍以上。在32K上下文的并发输出场景下,Strix Halo+Navi31可以获得几乎媲美纯独显的推理性能,560K左右的上下文也仅需16G左右的dGPU显存。
虽然与完全使用显存运行同样的模型相比,混合推理的prefill性能差距依然可达数倍(此处的主要性能瓶颈是Strix Halo iGPU孱弱的vector/tensor吞吐而非内存/显存),但较长上下文的输出速度性能差距并没有非常大。并且相比>64G显存方案的价格来说,使用10-16G高速显存搭配64G左右的LPDDR设备的价格门槛依然是成倍的低。
其它模型
考虑到GLM 4.5 Air、Qwen3 235B这些模型的单请求性能的实用性已经非常勉强,因此本次不测试这些模型的并发性能。当输出速度低于10t/s时,我们认为后续更长上下文的实用价值非常有限,停止进一步测试。
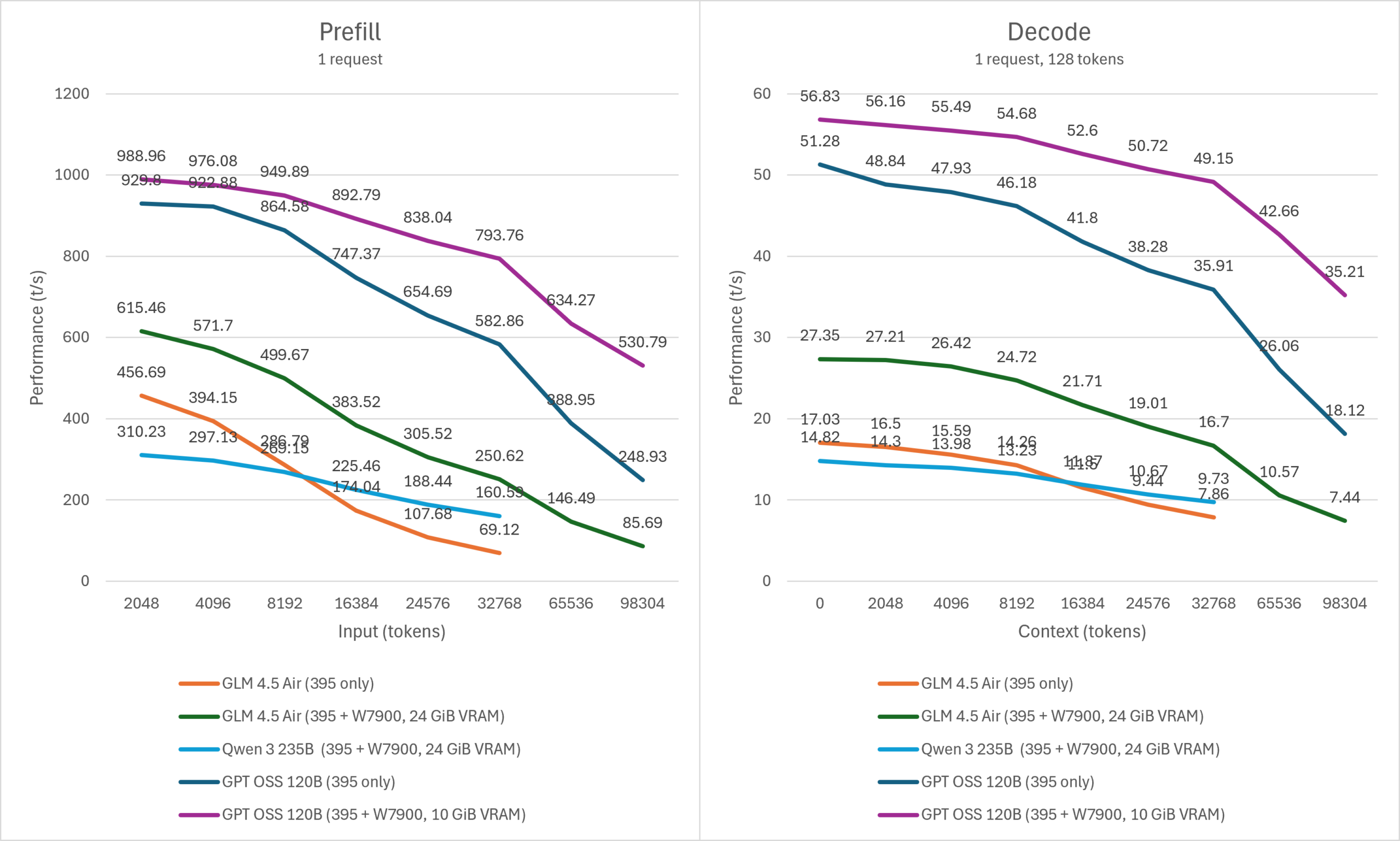
使用Strix Halo+Navi31组合运行GLM 4.5 Air可以全程看到相比GPT OSS更大的提升。128K上下文大约消耗21G的dGPU显存,这个容量刚好在普通游戏显卡的范围内,购买硬件不会有太多的溢价。
Qwen3 235B则是属于仅用Strix Halo恰好无法运行,但搭配24G显存的独显则可以勉强运行的情况。由于Strix Halo方案运行这个级别的模型非常勉强,这里仅提供性能参考而不作严肃的讨论。
总结
虽然为Strix Halo增加dGPU并不会显著改善此前提到的关于此类LPDDR设备运行LLM的那些尴尬问题(例如受到iGPU限制导致prefill性能依然较低,以及为什么不直接用同样的预算去购买多个独显等等),但这样的硬件组合在设备形态不发生大改变的情况下做到显著改善长上下文性能也算是目前一个不错的升级选项。如果是NVIDIA GB10搭配5090 GPU以相同的方式进行配置,实用性会显著更强。
理论上我们可以在长上下文prefill的场景将experts权重逐层拷贝到dGPU利用其更高的计算性能来缓解iGPU性能不足的问题(llama.cpp 仅需修改数行代码即可实现),但非常遗憾的是Strix Halo平台PCIe 4.0 x4的带宽限制使得实测这样做的收效甚微。如果有PCIe 5.0 x16的互联带宽,搭配2048 token或更高的microbatch运行本文提到的这些模型可以较为充分地利用dGPU相比iGPU的计算吞吐优势。
当前内存价格波动导致我们事实上不太好直接评价这种iGPU+dGPU组合推理的性价比,不过从原理上它需要两个GPU核心并且对各自的利用并不充分,所以单看芯片成本方面一定会有一些浪费。也许未来的硬件可以更好地应对这个场景,例如直接将大容量的LPDDR集成在高性能GPU上作为显存的扩展,甚至配合LPDDR-PIM等技术,这将会比用户自行组合多种GPU更加合理。
主播你终于更新了,好久没看你更新了
主包主包,你终于更新了。其实我觉得GB10的GPU也不太需要外接显卡就是了,走网的成本不算低
其实还可以考虑ai max 395那块没有使用的npu存在的潜力,如果能用来加速prefill的话,对运行llm模型带来的提升是巨大的
能不能试试把那块npu也一起塞进来
理論上 “孱弱的vector/tensor吞吐” 問題 可能是那個NPU最能幫到的