在上一篇关于Mac Mini (M4 Pro)的文章里,我从几个方面较为全面地测试了M4 Pro运行LLM的现状。虽然大容量高位宽LPDDR统一内存的组合确实可以满足一些LLM场景的需求,但Apple GPU的一些弱点导致其相比市面上相同价位的方案较为尴尬。
本文我们的探讨对象是AMD的Strix Halo平台。它的参数与M4 Pro相似,那么它是否能避免Apple GPU的那些问题呢?正文开始之前先剧透结论:比M4 Pro少尴尬一些,但依然有点尴尬。
测试环境
无论从规格、定位还是从实际性能与价格方面,Strix Halo最直接的对比对象均为M4 Pro,因此本次测试以这两个平台的性能对比为主。在此基础之上,我也会在合适的场景加入HX 370来代表主流双通道平台的表现,以及W7900代表相近价位廉价的大显存图形卡。
硬件参数
- M4 Pro
- 14-core CPU (10P + 4E)
- 20-core GPU @ 1.6 GHz
- 64 GB 256bit LPDDR5-8533
- Ryzen AI Max+ 395
- 实际运行在60W
- 16-core CPU (2 * 8P)
- 20-WGP GPU (40 CU) @ 2.2-2.6 GHz
- 64 GB 256bit LPDDR5-8000
- Ryzen AI 9 HX 370
- 实际运行在22W
- 12-core CPU (4P + 8E)
- 8-WGP GPU (16 CU) @ 1.8-2GHz
- 32 GB 128bit LPDDR5-7500
- Radeon Pro W7900
- 主板功耗295W,含显存的芯片总功耗240W
- 48-WGP GPU (96 CU) @ 2.2-2.6 GHz
- 48 GB 384bit GDDR6-18000
软件版本
- 操作系统与内核
- macOS 15.3.1
- Debian 12 + backports kernel (6.12.12)
- GPU runtime
- ROCm 6.4.0
- llama.cpp
- 主线版本 (commit 558a764713468f26f5a163d25a22100c9a04a48f, b5198)
- ROCm 编译参数 -DGGML_HIP=ON -DAMDGPU_TARGETS=”gfx1100″ -DGGML_HIP_ROCWMMA_FATTN=ON -DGGML_CUDA_FA_ALL_QUANTS=ON
- Metal 编译参数 -DBUILD_SHARED_LIBS=OFF -DGGML_METAL_USE_BF16=ON
参数调优
为了使各个平台可以顺利完成测试,需要进行如下参数调整
- Apple平台使用 sysctl iogpu.wired_limit_mb=62464 提高显存分配上限以正常运行一部分显存需求较高的测试。
- AMD APU平台
- 在BIOS设定512MB显存分配
- 使用内核启动参数amdgpu.gttsize=61440 ttm.pages_limit=15728640提高GTT分配显存的上限
- 设置内核启动参数 amd_iommu=off 参数关闭IOMMU
- 考虑到Apple平台也为GPU关闭IOMMU使用GPU自己的页表,在这一配置下测试的结果具备可比性
- 替代方案是直接在BIOS内分配较大显存并当作独显使用,实测二者性能基本一致
- 设置环境变量GGML_CUDA_ENABLE_UNIFIED_MEMORY=1为llama.cpp启用UMA内存分配
- 设置环境变量HSA_OVERRIDE_GFX_VERSION=11.0.0以顺利运行测试
- AMD独显平台设置内核启动参数amdgpu.runpm=0 amdgpu.aspm=0 iommu=pt
性能对比
本次测试依然按照惯例选取不同大小的Qwen 2.5开源模型,对于14B模型涵盖q4_k_m、q4_0、iq4_xs、q8_0等常见的量化算法,32B、72B模型则测试4bit量化为主。虽然在本文撰写期间Qwen发布了Qwen 3,但同尺寸dense模型的性能高度相似,因此可以基于现有数据合理推测未来版本相近尺寸的模型性能。除此之外,最近发布的Llama 4作为一个MoE模型,对LPDDR这种大容量低带宽设备较为友好,本次也加入了一些简单的测试。
由于Metal与ROCm平台的flash attention支持较为完善,实测对缓解较长上下文的性能下降有较为明显的帮助,因此在测试中均会开启。
测试命令参考
llama-bench -r 3 -m ./qwen2.5-14b-q4_k_m.gguf,./qwen2.5-14b-q4_0.gguf,./qwen2.5-14b-iq4xs.gguf,./qwen2.5-14b-q8_0.gguf,./qwen2.5-32b-iq4xs.gguf,./qwen2.5-32b-q4_0.gguf,./qwen2.5-72b-iq4xs.gguf -n 64,128,256,512,1024,2048,4096 -p 64,128,256,512,1024,2048,4096 -fa 1
Prefill
首先依旧是测试Prefill (prompt processing)性能,代表LLM每秒可以处理多少个token的用户输入。这一阶段GPU可以充分并行处理每个token,因此其性能主要与GPU matrix计算吞吐正相关。对于AMD与Apple来说,Prefill一直都是其弱项,在这样的低功耗平台上则更甚。
为了更全面地反映性能,本文测试从64到4096 token的输入处理速度并绘制成图表。
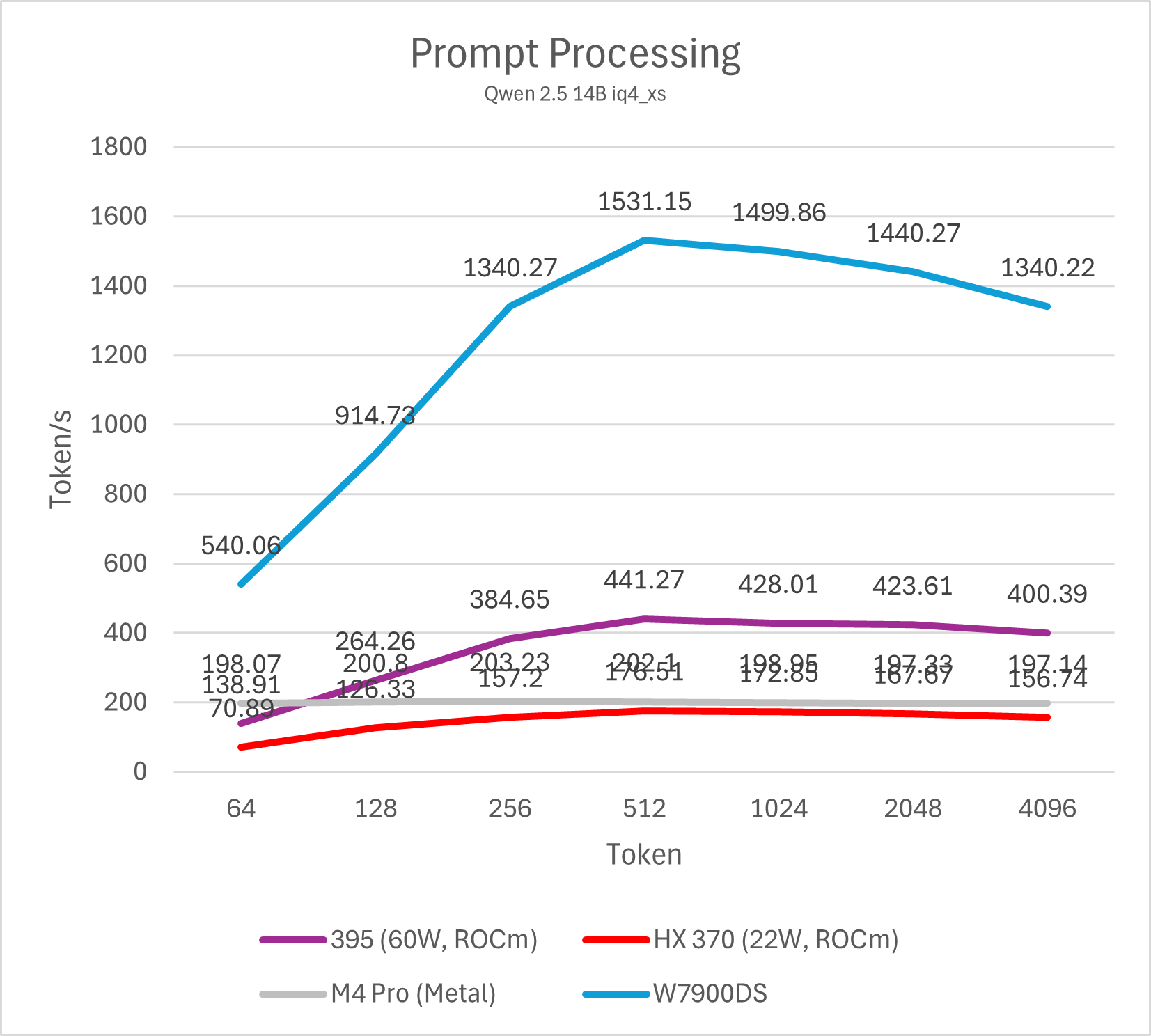
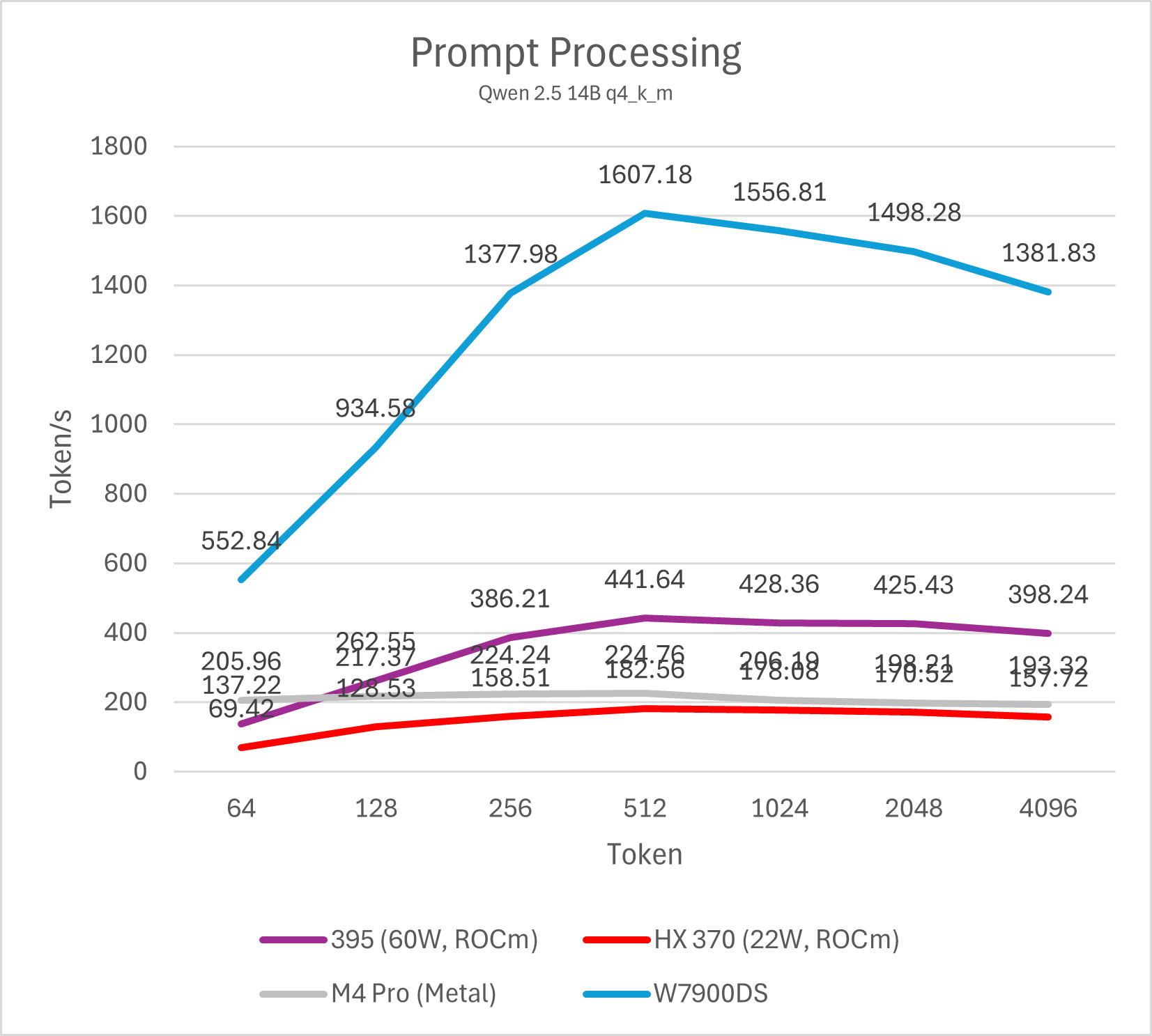
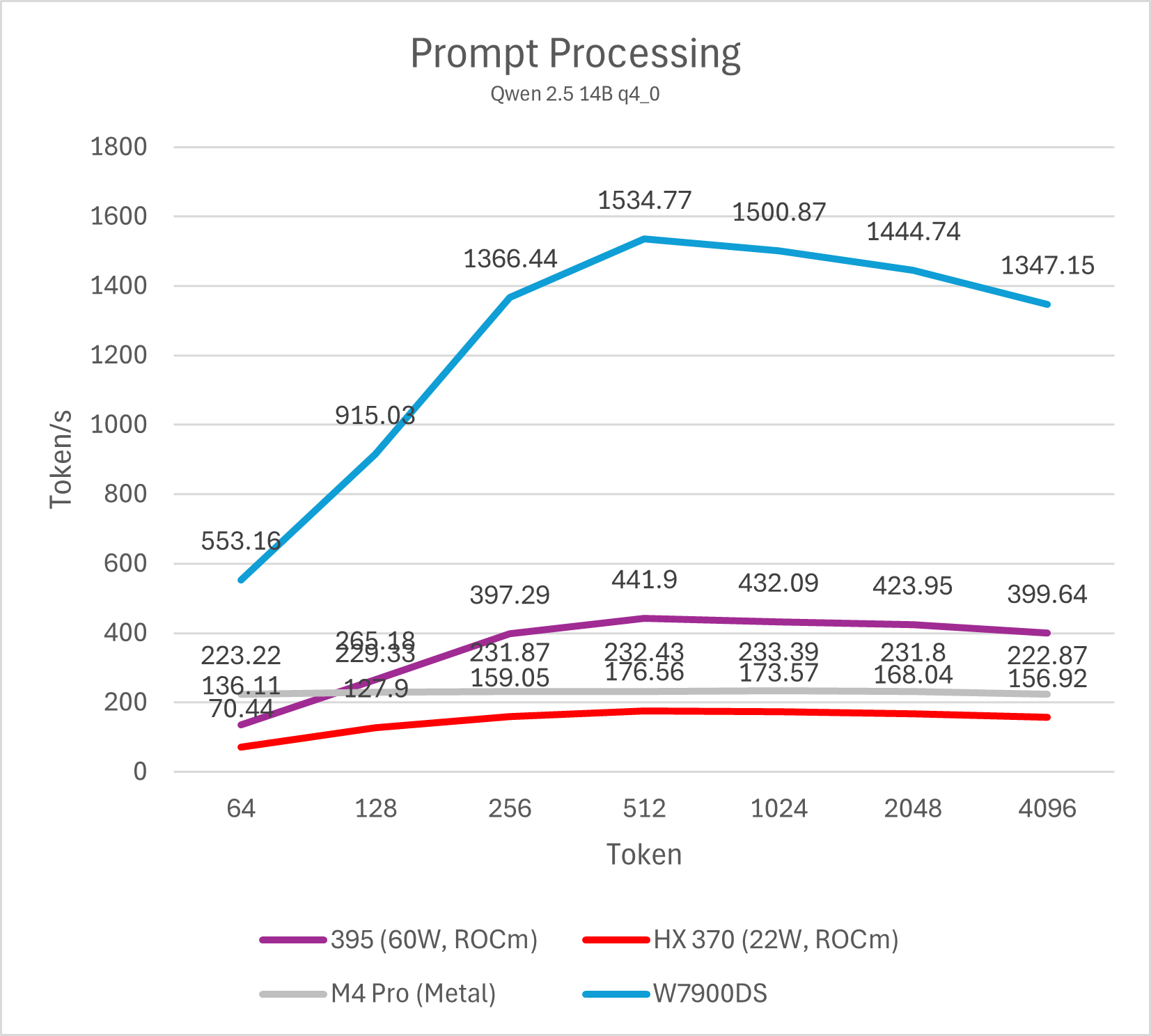
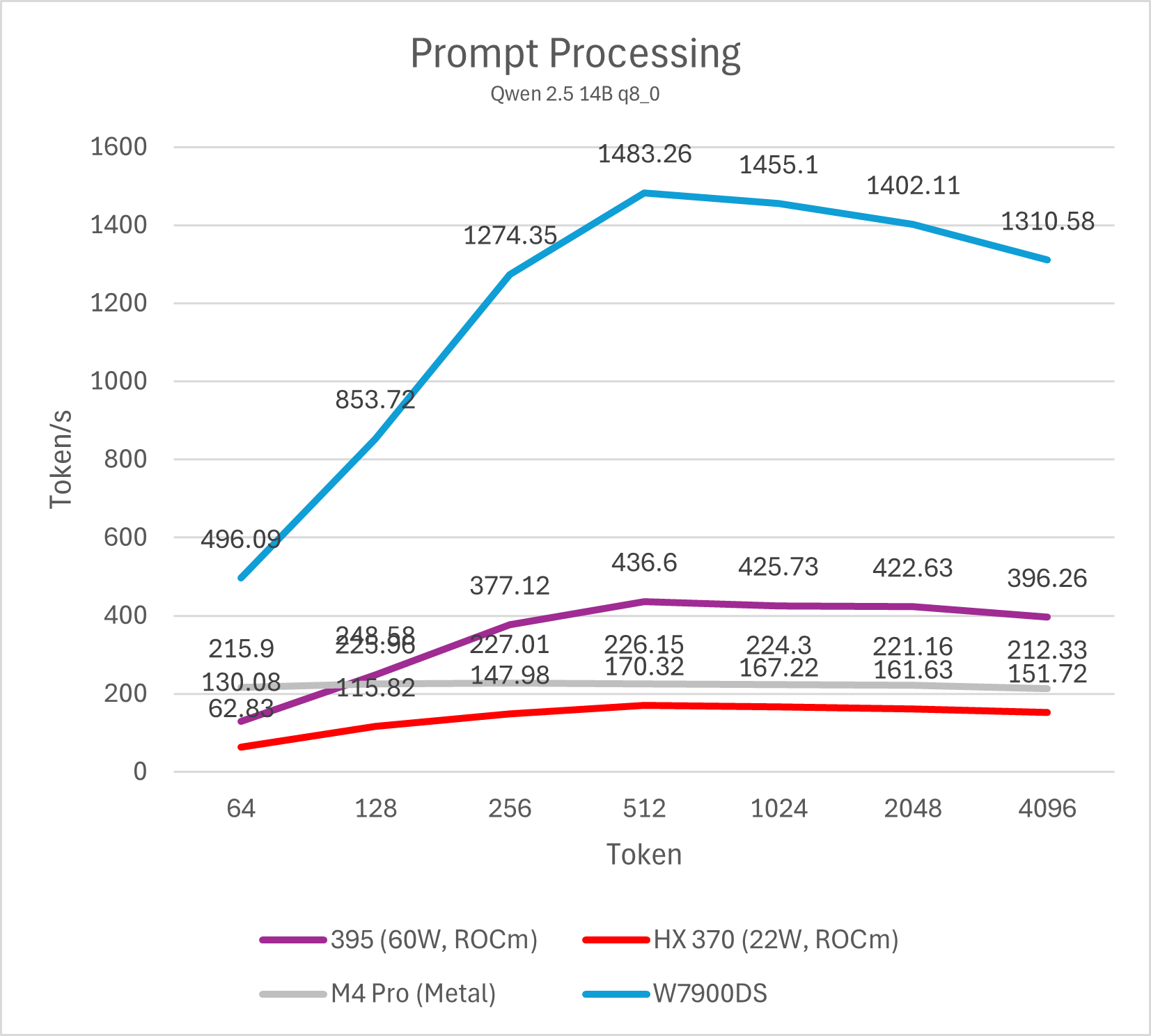
14B模型
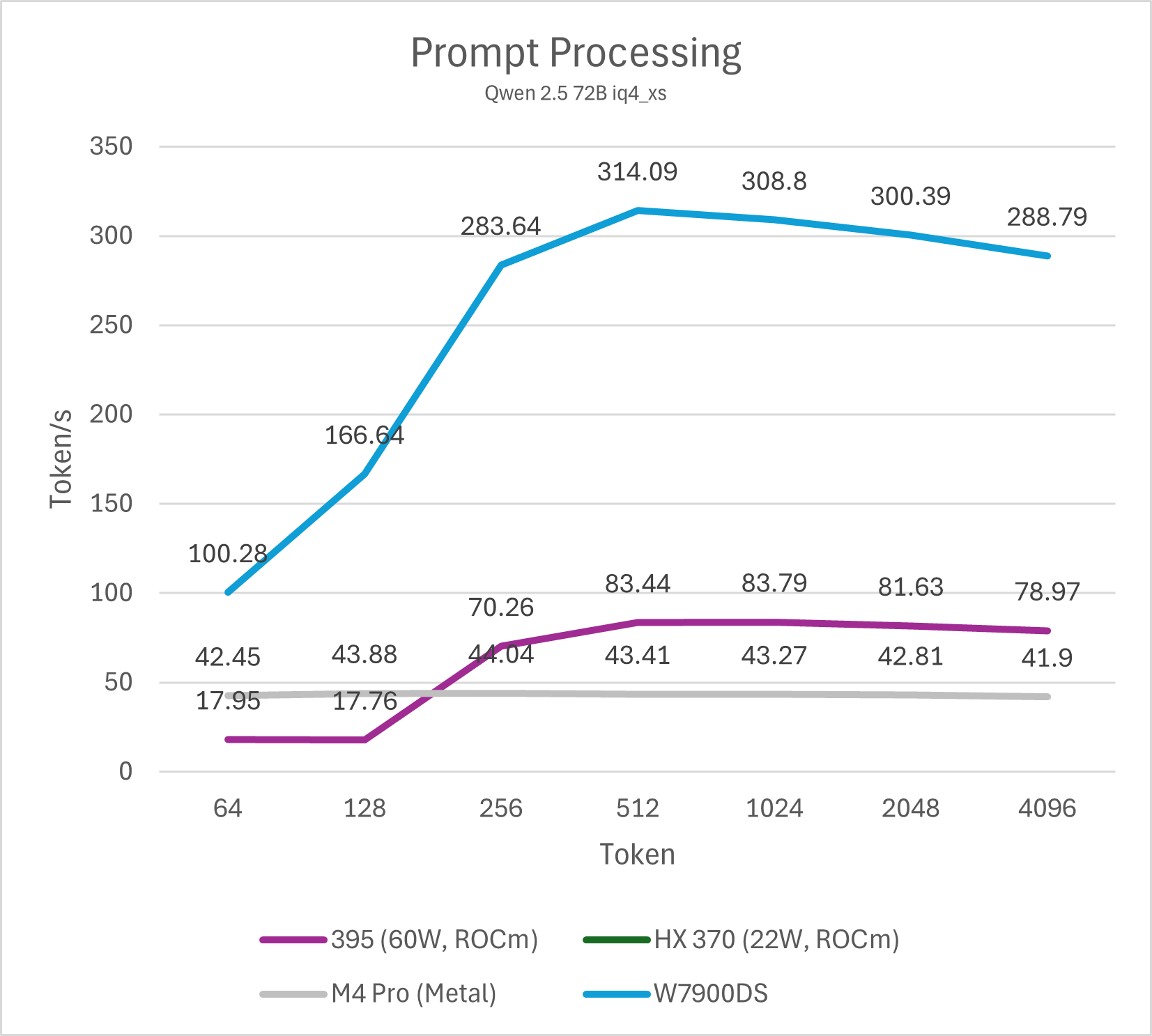
32B / 72B模型
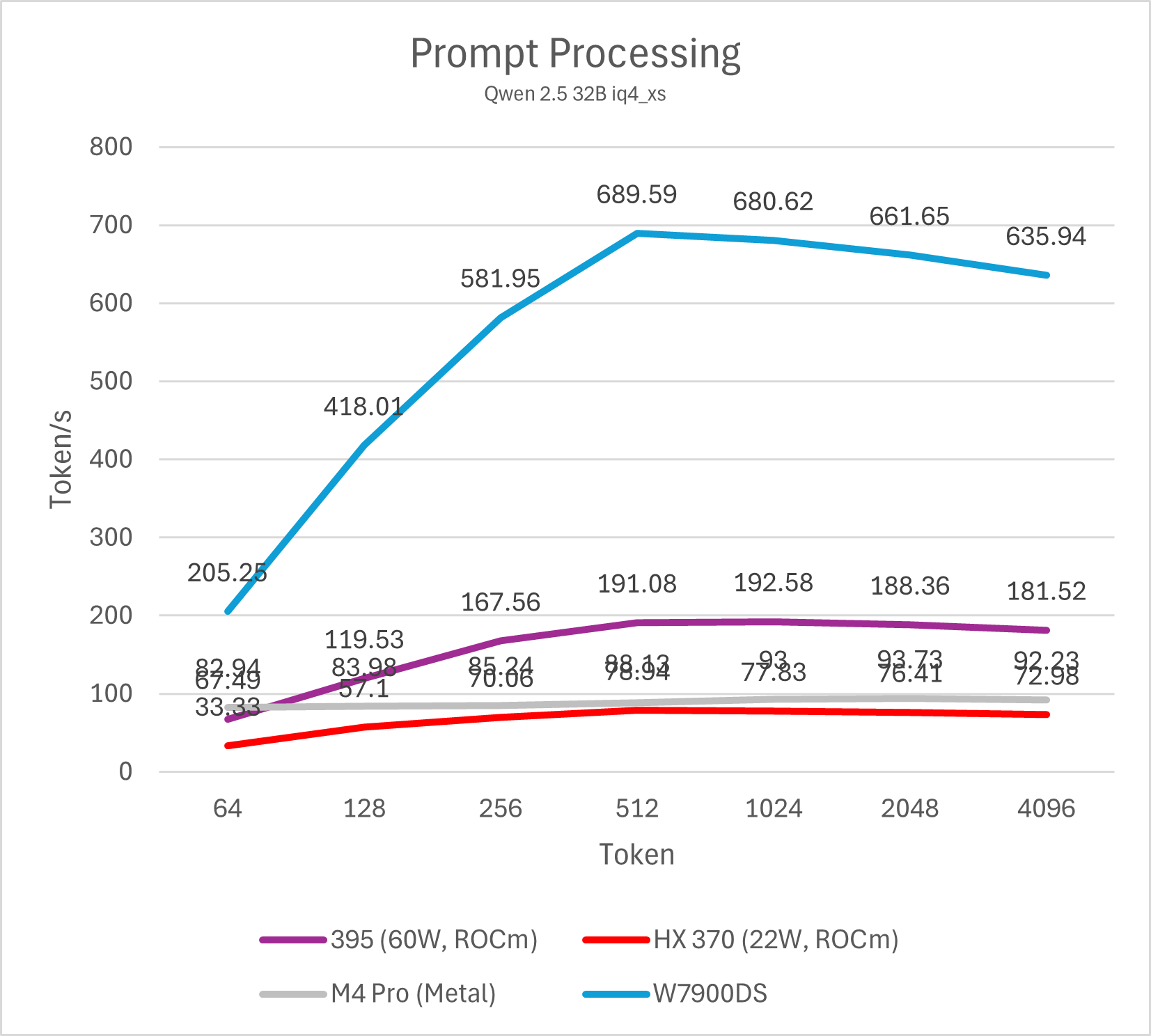
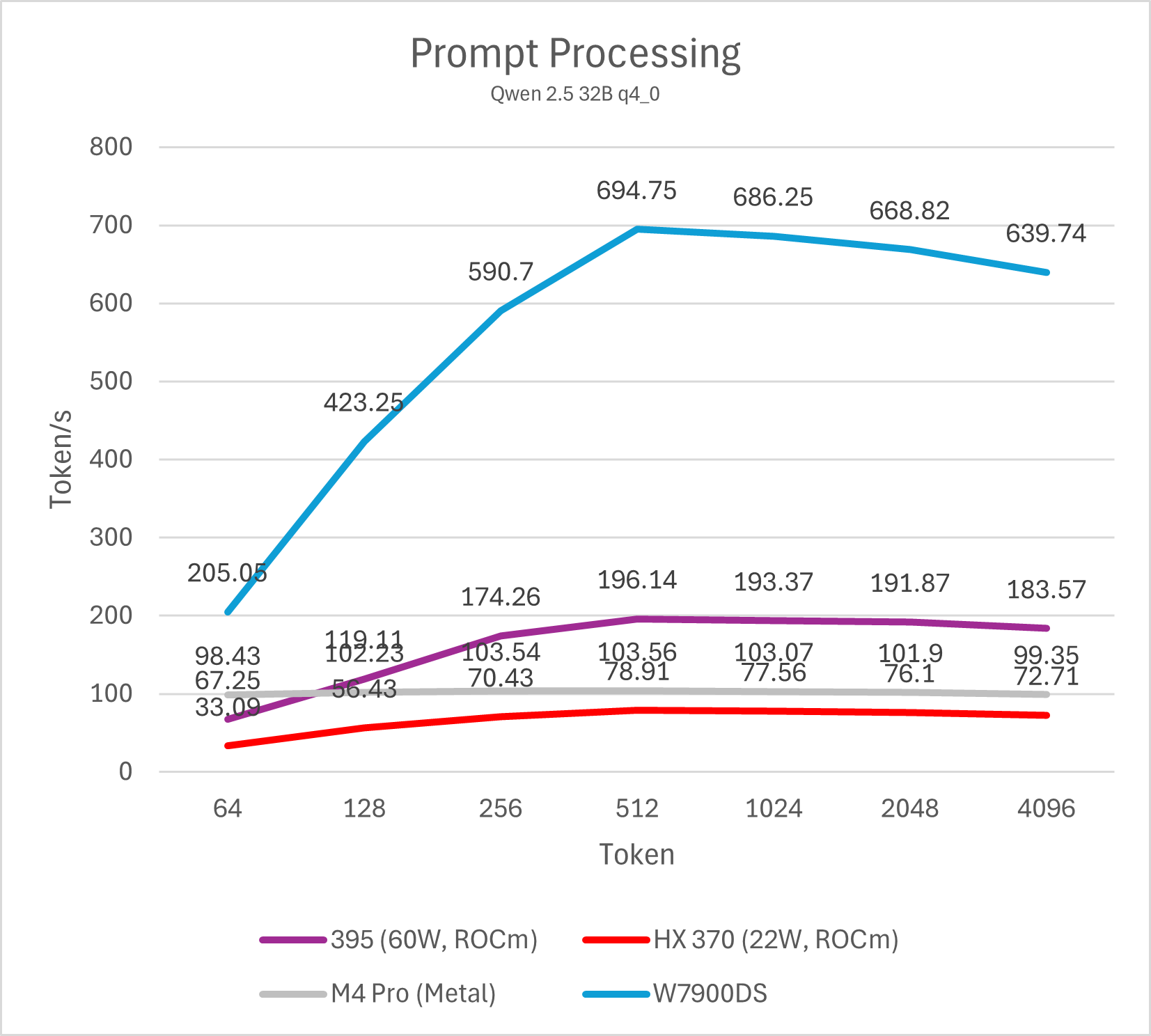
M4 Pro与Strix Halo运行不同量化算法的14B模型prefill均有不错的表现,属于高度可用的性能。M4 Pro整体表现接近HX 370,Strix Halo大约是M4 Pro的两倍。移动平台与桌面图形卡的差距依然明显,即便是表现最好的Strix Halo与相对一般的W7900也有大约3-4倍的差距,而同代的NVIDIA GPU则要比W7900进一步强出数倍。事实上,仅仅只有16SM的NVIDIA Orin平台就可以做到与Strix Halo (395)相似甚至略强一些的prefill性能。
参与测试的这些平台运行32B、72B模型的结论与14B差异不大,不过M4 Pro、Strix Halo运行72B模型会略显乏力,prefill降低到100 token/s以下会严重影响部分场景的使用体验。HX 370平台仅有32G内存因此无法运行72B模型测试,其在32B模型测试里已经表现较差,因此运行72B模型也缺乏实际意义。除此之外,M4 Pro运行iq4_xs模型的prefill会有额外的性能损失(大约10%左右),其余gguf量化的性能差异不大。
需要注意的是,ROCm平台在输入token数低于512的情况下性能较低,这并非平台硬件原因导致,而是llama.cpp CUDA版本的一个性能特性,在NVIDIA GPU上也可以观察到。通过调整micro-batch大小(例如-ub 32,默认为512)可以显著改善短输入的prefill跑分成绩,不过同时也会影响长输入的性能,因此并不实用。
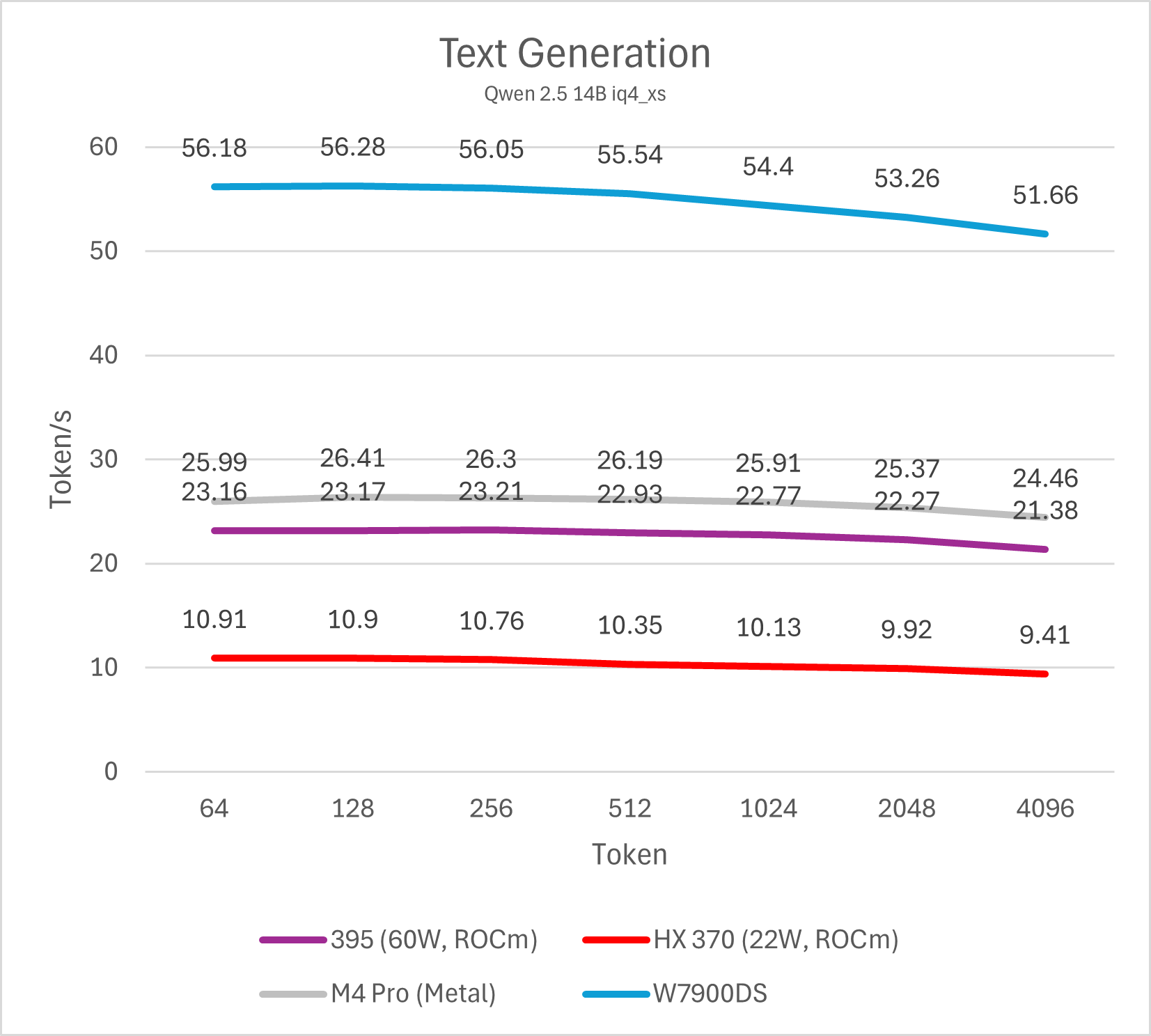
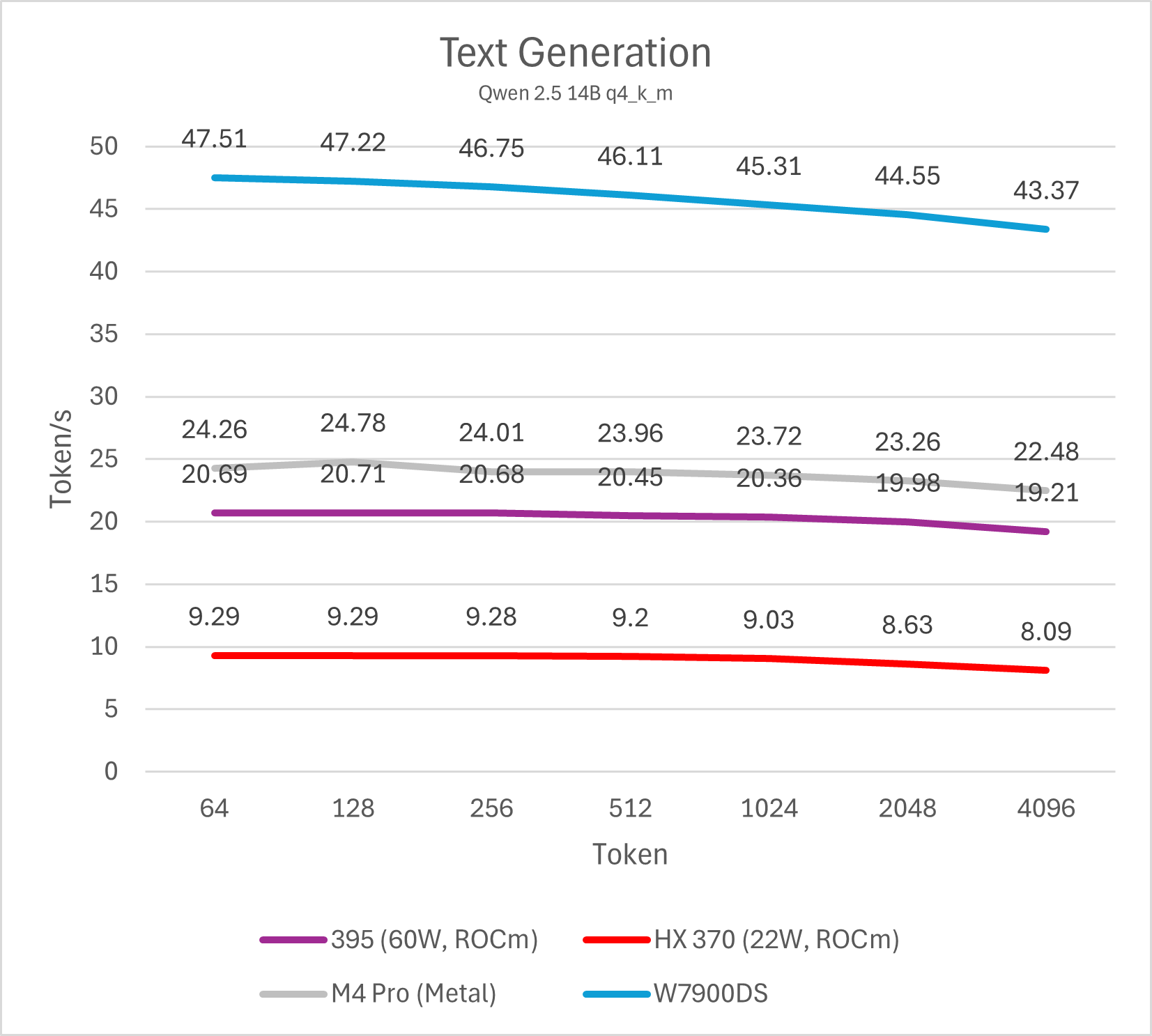
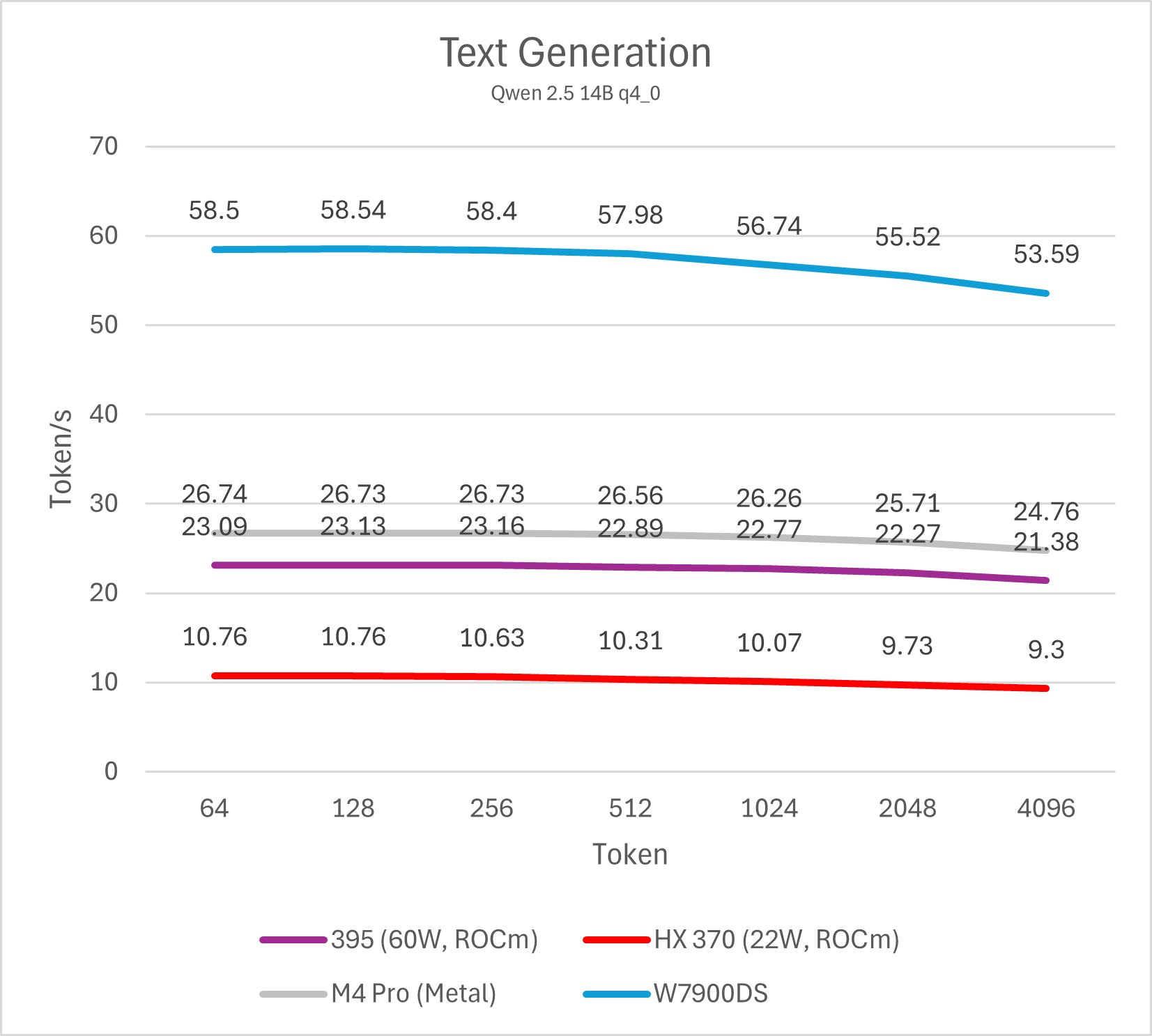
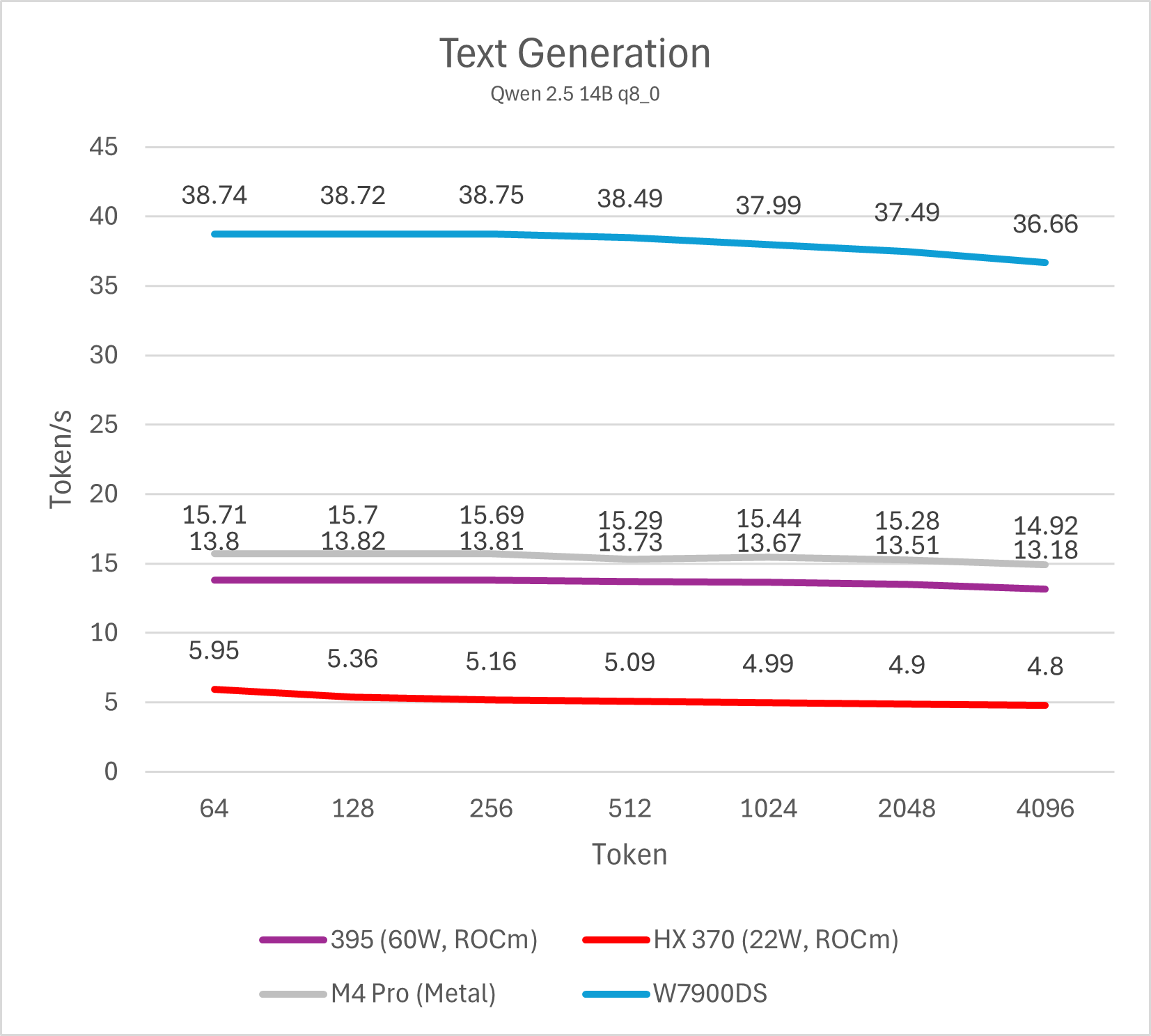
Decode (单用户)
通过测试单线程decode性能我们可以了解单用户使用LLM文本生成的速度,这也是LLM软件给用户最直观的性能体现。个人认为,10 token/s是及格线,而>20 token/s则可以带来值得推荐的优秀使用体验。这一项性能与内存/显存带宽直接相关。
14B模型
32B / 72B模型
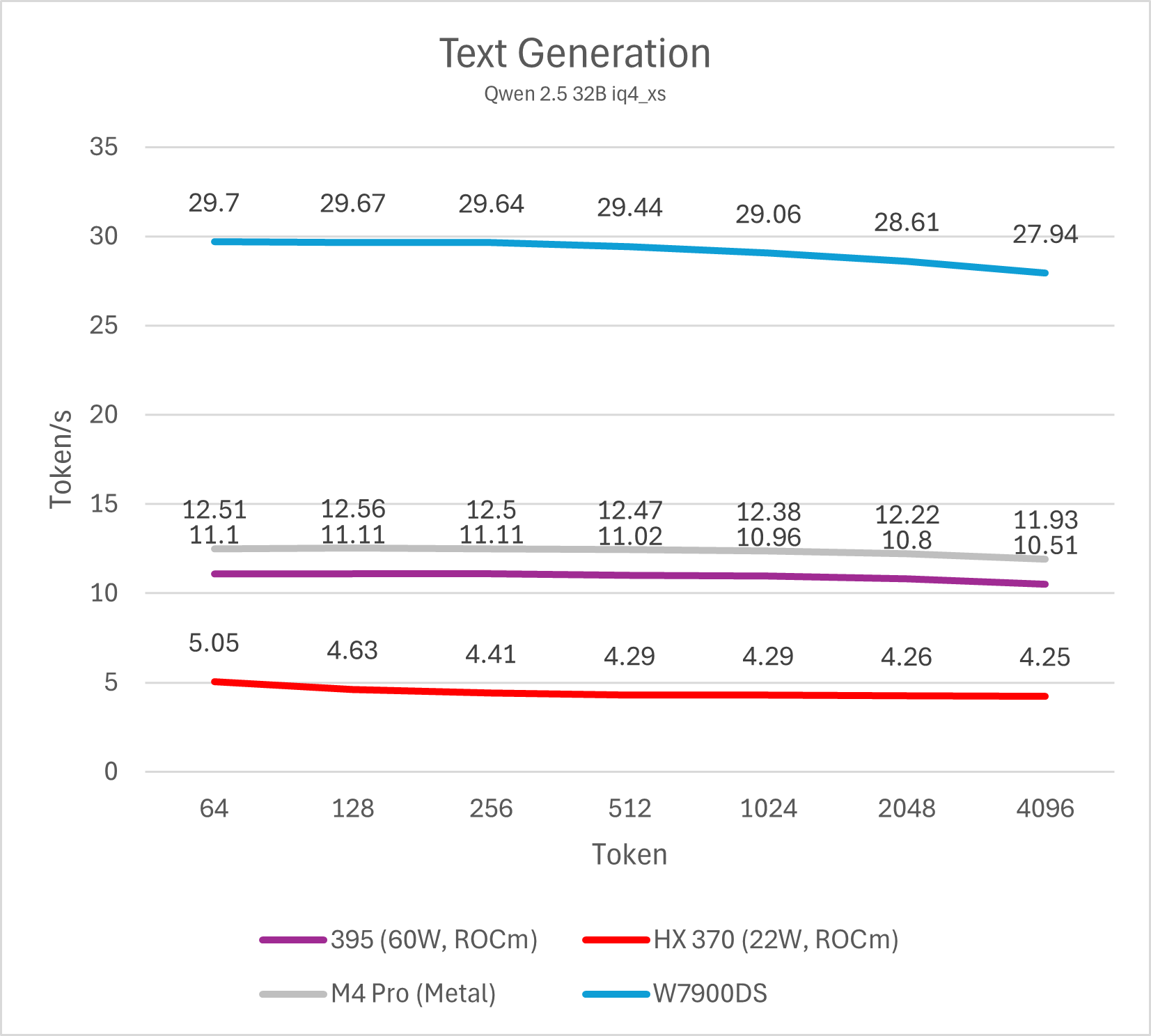
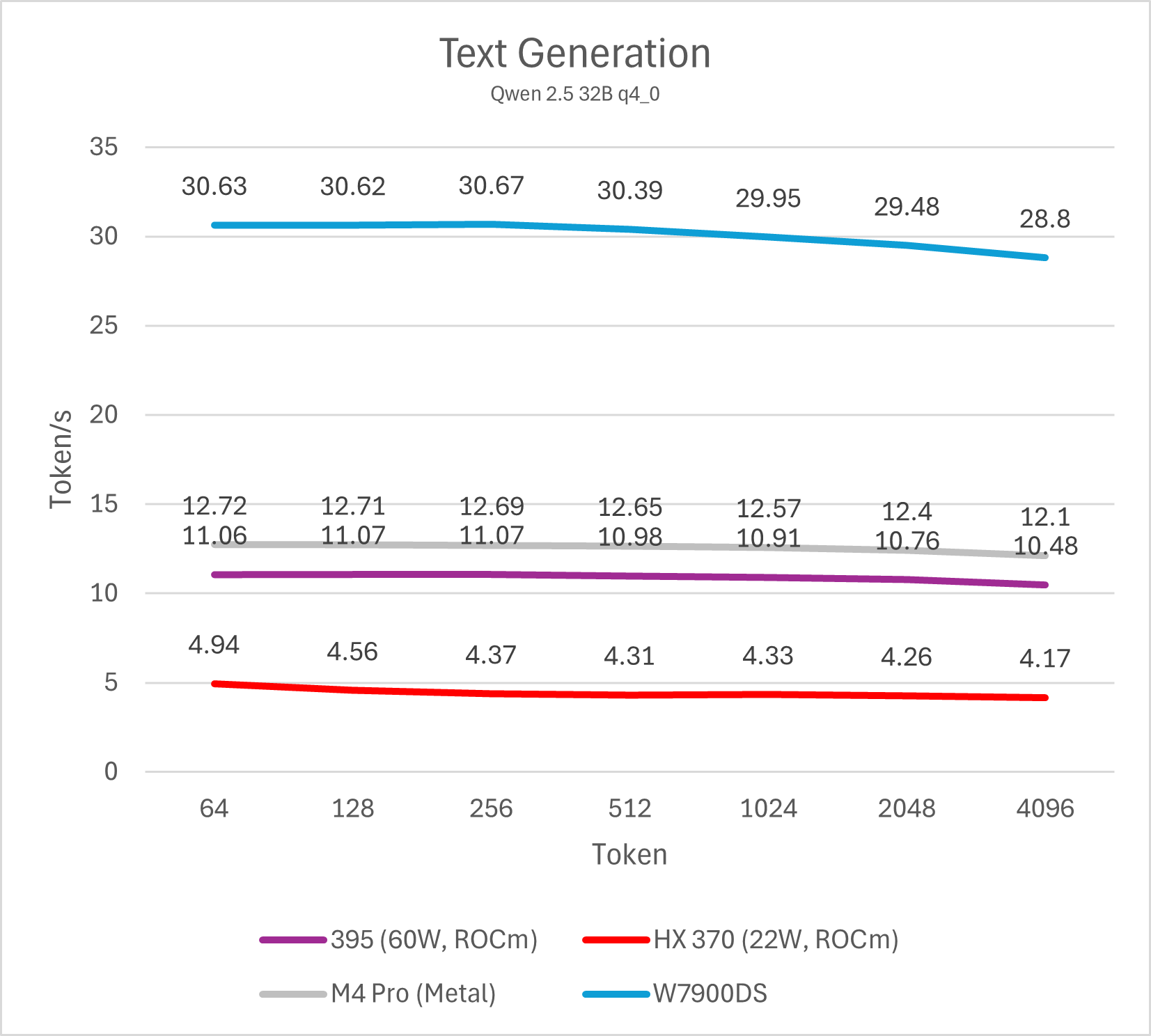
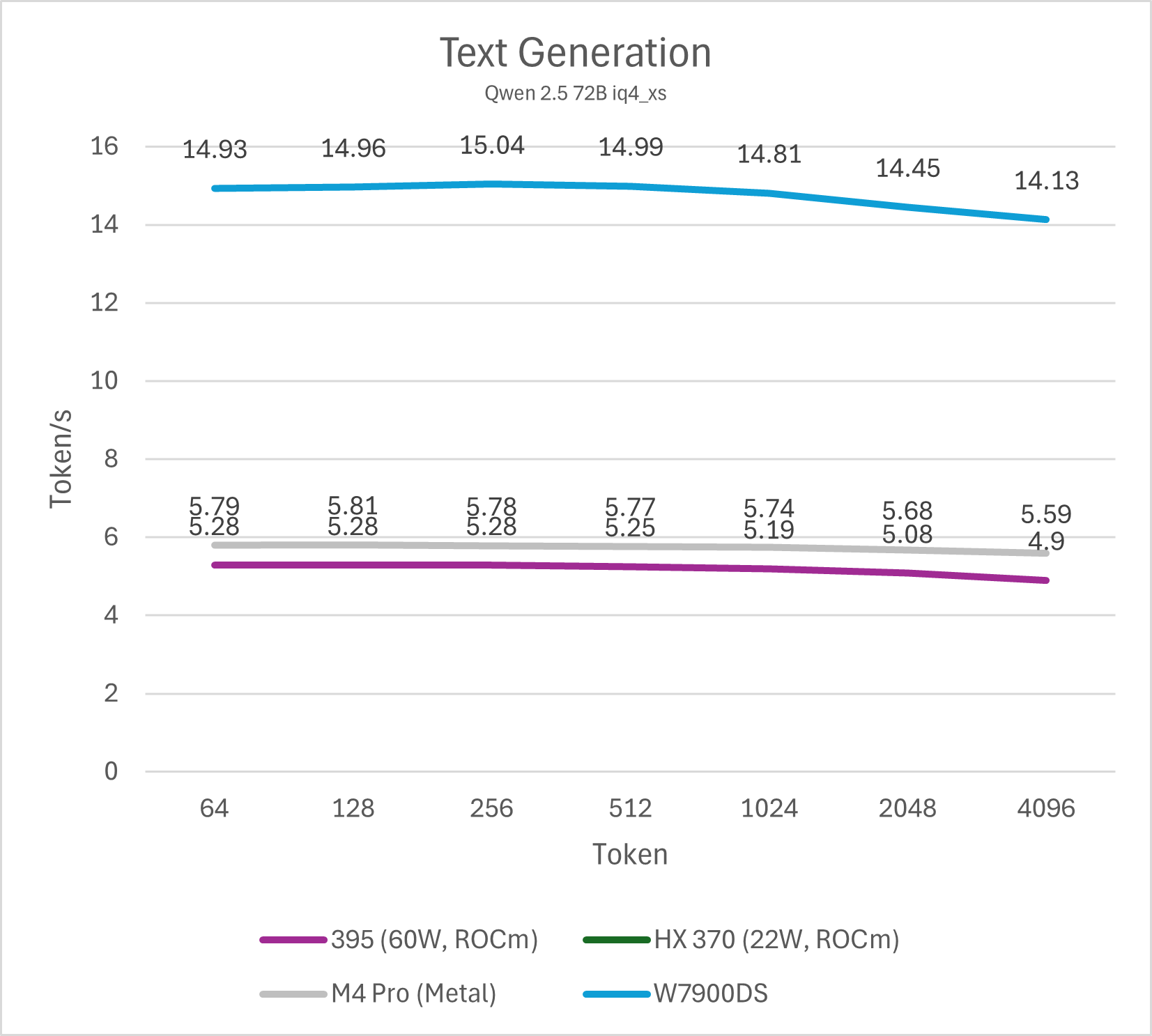
不同模型的测试最终可以反映出相同的结论,Strix Halo平台的单用户LLM decode性能大约是Strix Point (HX 370)的两倍,略低于M4 Pro (10-15%左右),整体处于相近水平,而与W7900则是3倍的性能差距。这一结论符合参测系统的内存/显存理论数值相对关系。
总的来说,在不开启投机解码的情况下,Strix Halo与M4 Pro运行32B以下的4bit LLM是较好的选择,也就是模型本身占用内存不会超过20 GB。运行72B模型会导致性能下降到5-6 token/s,使用体验较差。而W7900这类大显存图形卡则可以更轻松的驾驭72B模型。
并发Decode性能
并发的主要目标场景是单服务器多用户,以及一部分离线处理场景等(例如分段翻译大量文本)。在并发处理多个请求的过程中,LLM服务器每次读取模型参数后可以同时处理多个用户请求,从而将带宽瓶颈转换为计算瓶颈。如果希望使用Strix Halo / M4 Pro平台搭建多人共享LLM服务器,或者使用支持批处理的生产力软件,则需要重点关注并发测试性能。
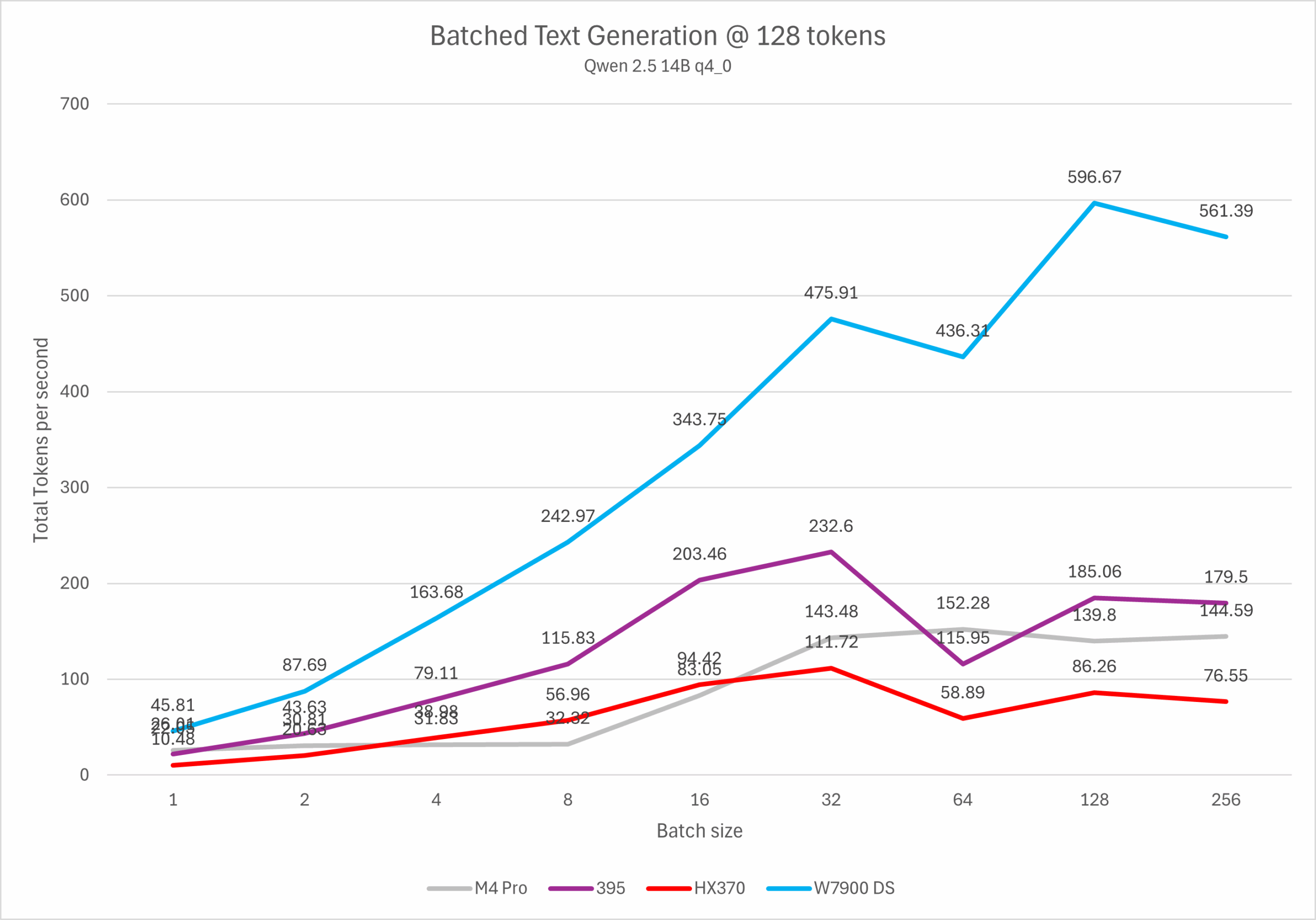
llama-batched-bench -c 32768 -m ./qwen2.5-14b-q4_0.gguf -ngl 999 -fa -ctk q8_0 -ctv q8_0 -npl 1,2,4,8,16,32,64,128,256 -ntg 128 -npp 0 –no-mmap
ROCm运行llama.cpp flash attention会采用legacy CUDA WMMA实现,由于64K LDS容量限制等因素,其batch size仅支持到32。因此在超过32并发后会因为fall back到hipBLAS产生一个非常明显的性能下降,实际使用中建议将batch size限制在32以内 (llama-server 参数 -np 32)。
而Apple GPU的实现则相反对低batch size支持不佳,运行4bit模型时在bs=8以内完全看不到任何性能提升,运行8bit模型则仅有bs=2时性能提升一倍,而bs=4-8时依然受限。当然,相比于去年我首次测试时低batch size会导致性能下降,现在的状况已经有一些改善了。不过matrix / tensor算力不足依然是硬件上的硬伤,后期进一步改进的空间也比较有限。
从测试结果来看,Strix Halo的批处理性能上限大约是M4 Pro / HX 370的两倍,W7900的三分之一左右。与其他RDNA3平台类似,在4并发以内可以实现几乎不损失每用户性能,超过4并发后单用户性能则会逐渐下降。这一性能要显著弱于Ampere/Ada/Blackwell等NVIDIA GPU,也弱于RDNA4。
投机解码 (Speculative decoding)
对于纯粹的单用户应用场景而言,投机解码是优化使用体验的选项之一。其原理是使用一个较小的draft model快速生成多个token,再由较大的目标模型进行并发验证。这个过程可以将单用户LLM文本生成的带宽瓶颈部分转换为计算瓶颈,但对于服务器等高并发使用场景则没有意义,由于生成draft需要额外计算且draft并非100%命中,会导致计算吞吐被浪费一部分而降低整体性能。
为了更好地测试纯粹的投机解码性能,本文使用了改进的测试方法:使用一个投机解码100%命中率的prompt(Repeat this sentence indefinitely and don’t say anything else: This is a test.\n),通过调整投机解码的token数量来反映不同场景下的投机解码性能提升。根据实际使用经验,大部分场景下的实际性能会落在横坐标2-4 token范围内,因此这几个点的性能尤为重要。更高的数值仅供理论研究。
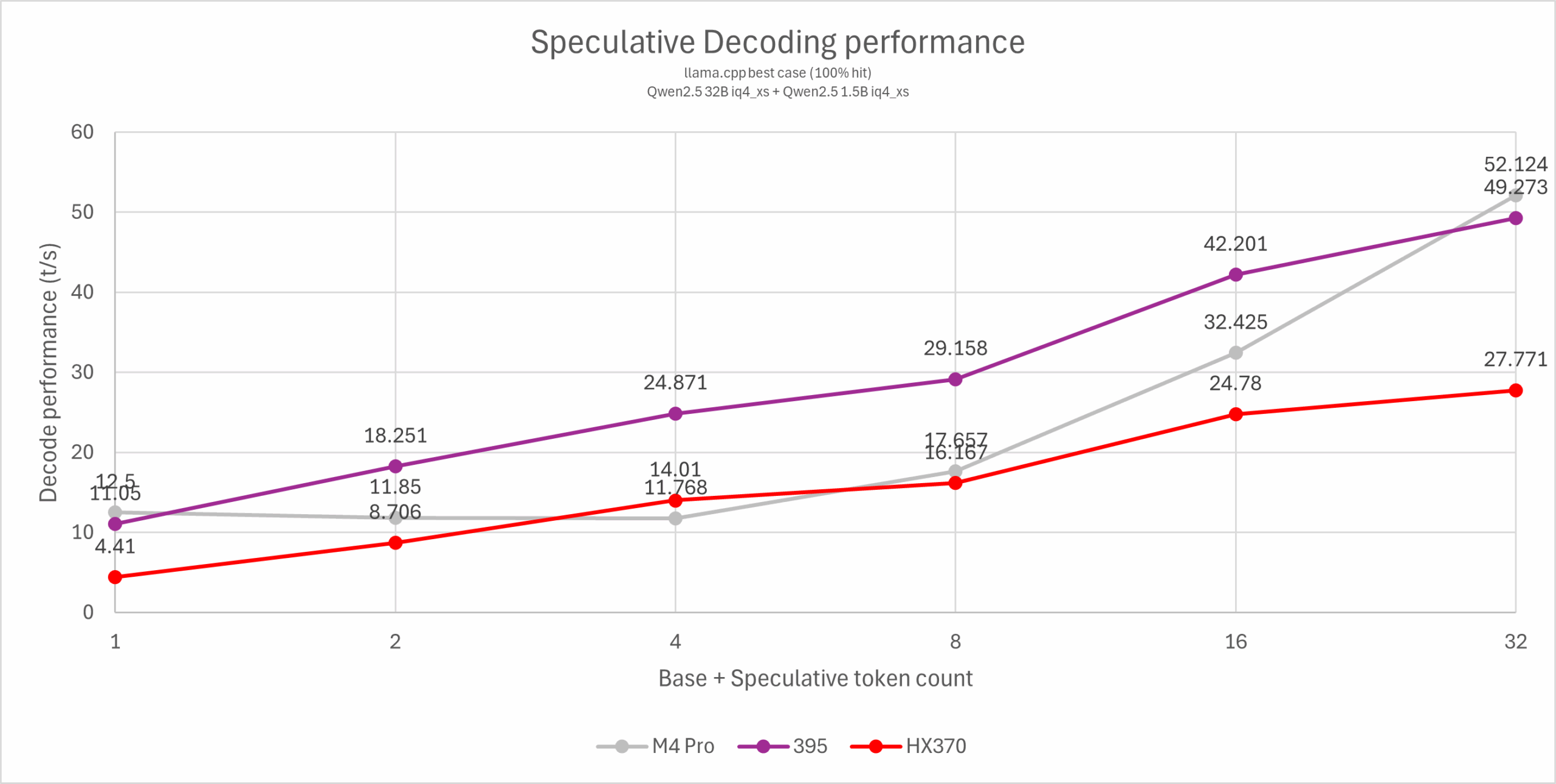
llama-speculative-simple -c 4096 -cd 4096 -m ./qwen2.5-32b-iq4xs.gguf -md ./qwen2.5-1.5b-iq4xs.gguf -ngld 999 -ngl 999 –draft-max <1/3/7/15/31> –draft-min <1/3/7/15/31> –draft-p-min 0 -p “Repeat this sentence indefinitely and don’t say anything else: This is a test.\n” -s 123 -n 200 -t 1 -fa -ctv q8_0 -ctk q8_0
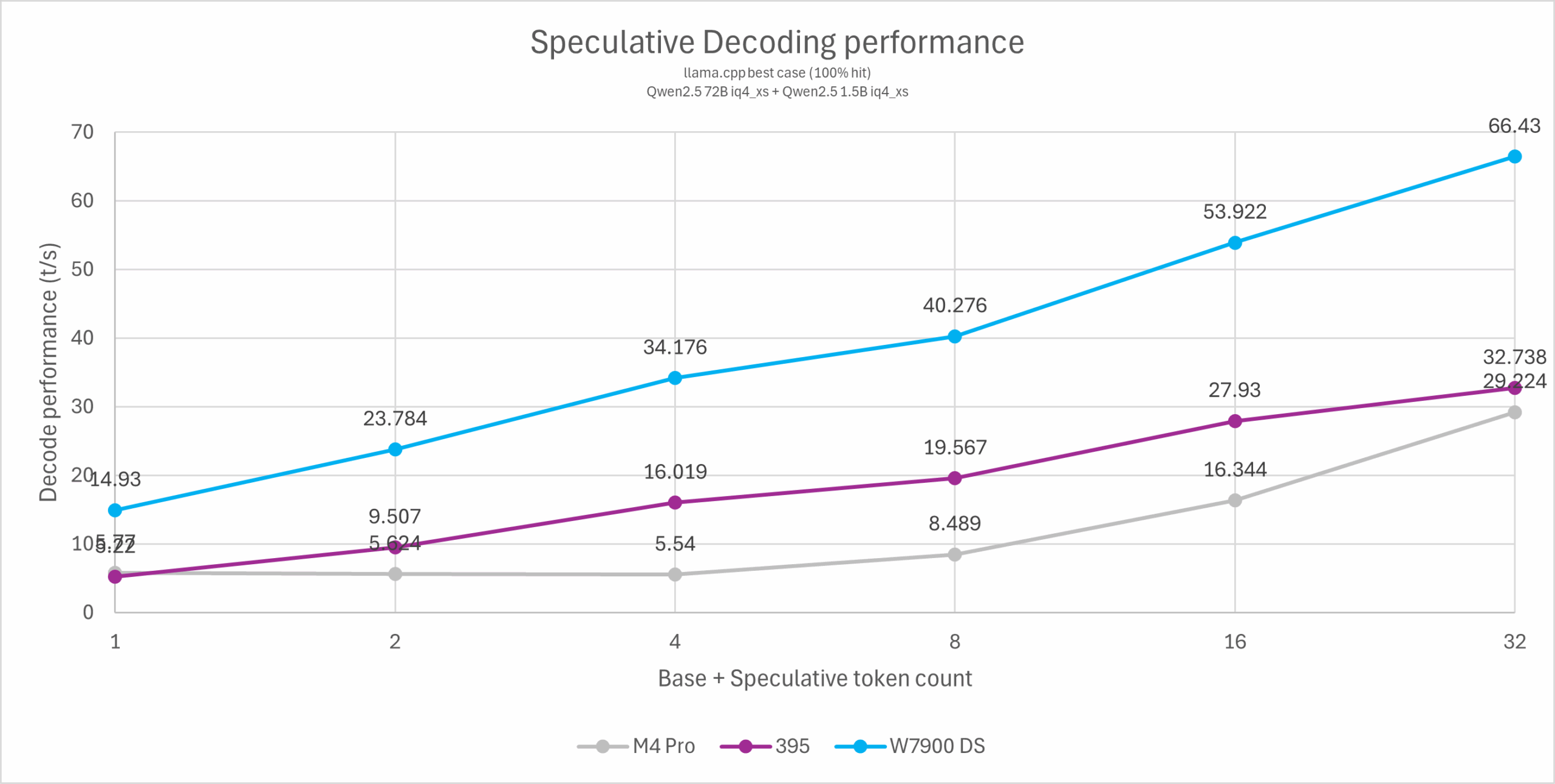
llama-speculative-simple -c 4096 -cd 4096 -m ./qwen2.5-72b-iq4xs.gguf -md ./qwen2.5-1.5b-iq4xs.gguf -ngld 999 -ngl 999 –draft-max <1/3/7/15/31> –draft-min <1/3/7/15/31> –draft-p-min 0 -p “Repeat this sentence indefinitely and don’t say anything else: This is a test.\n” -s 123 -n 200 -t 1 -fa -ctv q8_0 -ctk q8_0
从测试结果可以看出Strix Halo在投机解码场景基本是一个常规RDNA3的表现,在预测2-4 token的范围内可以轻松驾驭72B模型达到超过10 token/s的可用水平。这相比M4 Pro有1-2倍的性能优势,与同价位独显方案的差距也略有缩小,不过依然高达一倍以上。
MoE模型
由于MoE模型激活参数相对其总参数较低,它对容量-带宽比例的要求远高于常规模型,天然适合LPDDR平台。
正好最近Meta Llama 4发布了两个开源的MoE模型,激活参数均为17B。需要注意的是,64GB机型运行Llama 4非常勉强,跑分仅能代表理论性能。而Strix Halo支持更大的内存,这对于实用性来说是一个明显的优势。
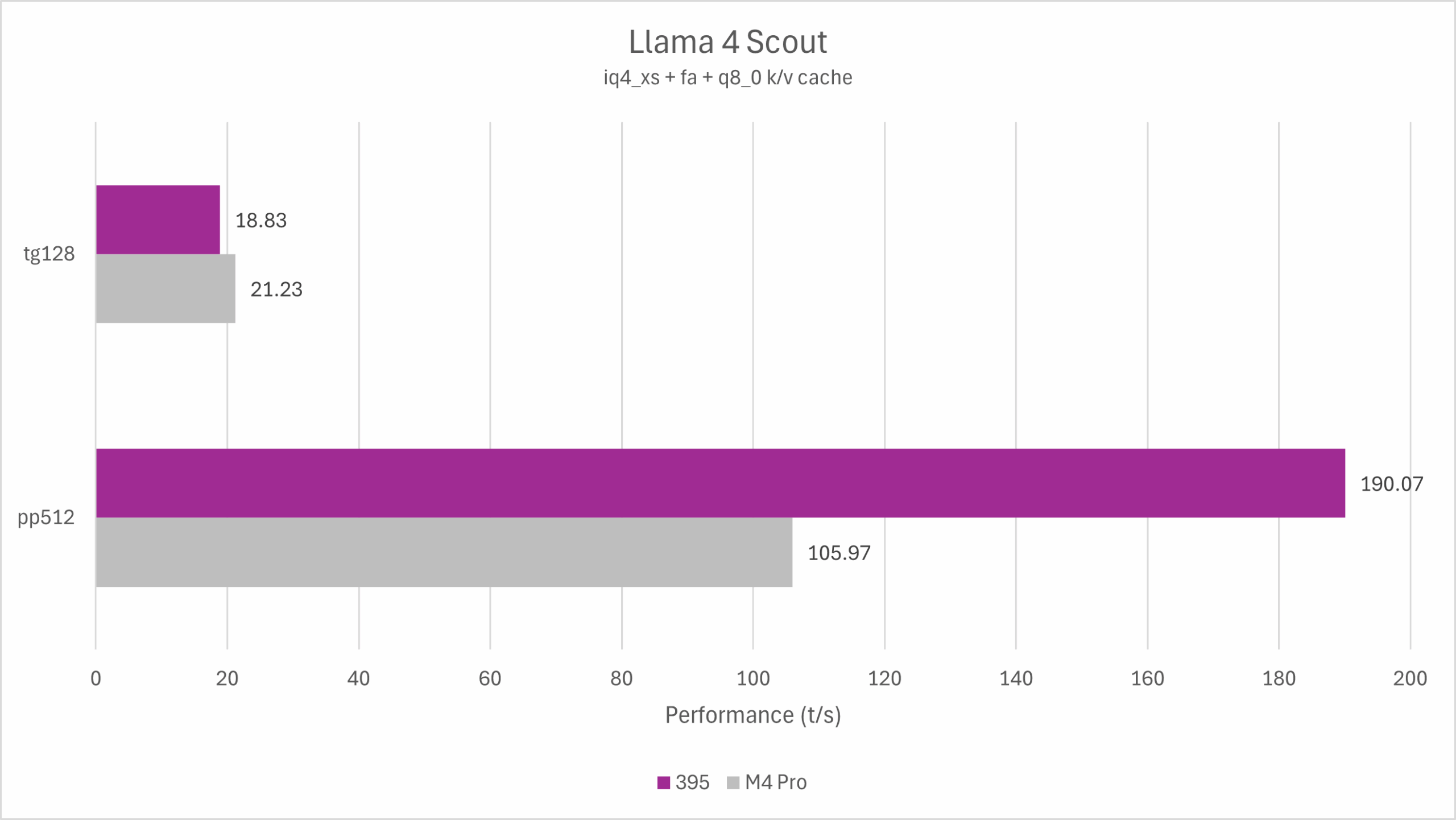
llama-bench -r 3 -m ./llama4-109b-iq4xs.gguf -fa 1 -ctk q8_0 -ctv q8_0 -mmp 0
从测试结果可以看出,Strix Halo与M4 Pro运行Llama 4均可获得较好的性能,其中Strix Halo的prefill性能接近M4 Pro的两倍,而M4 Pro则在decode性能里更胜一筹,比Strix Halo高13%。
不幸的是,Llama 4并不是一个非常优秀的模型,尤其是考虑到它对内存容量的要求。如果Meta未来可以继续改进Llama 4模型架构的表现,或者Qwen等发布了类似的开源模型,那么对于LPDDR平台将会是一个重大利好。当前的表现只能算是未来可期。
待解决的问题
与许多新平台类似,Strix Halo当前并非完美无缺,依然有很多待解决的问题。这里列出一些我在近一个月的日常使用中所遇到的例子。
Windows支持
AMD APU在Windows上存在一个较大的瑕疵:动态分配的共享显存性能较差,以至于大部分LLM场景只能使用BIOS固定分配的显存,不具备UMA设备所应该有的灵活性。这个问题在Linux与macOS下并不存在。
笔者个人并未在Strix Halo设备上使用Windows,因此本文不讨论其它相关细节问题。
Linux支持
基于Strix Halo平台的HP Zbook Ultra笔记本获得了Ubuntu认证,对Linux的支持具备最基本的保证。但这是基于Ubuntu hwe内核,并不代表其在Fedora、Arch Linux、Debian等主线内核发行版上的表现完美无缺。
在主线内核中,Strix Halo与Strix Point具备相同的问题,例如Firefox开启硬件解码稳定性不佳,Strix新ISP的MIPI驱动暂未进入主线因此无法点亮摄像头等,仍需要一些时间解决。但平台本身日常使用已经足够完美。
ROCm
ROCm在Linux平台尚未官方支持Strix Halo (gfx1151),因此需要使用HSA_OVERRIDE_GFX_VERSION=11.0.0环境变量使用Navi31的代码路径。正式的支持可能还需要等待几个版本的更新。
部分场景下ROCm的稳定性比较一般(例如频繁加载不同的LLM模型容易出现MES queue remove fail、GPU hang等问题,固定使用单一llama-server则问题不大),且缺少性能调优文档,需要做出类似本文的一些内核参数调整才可以获得最佳的使用体验。
NPU
AMD官方正在为XDNA NPU编写基于MLIR的llama.cpp/ggml-hsa后端支持,且目前已经有一些公开可见的代码和进度。未来平台算力有机会得到进一步的充分利用,例如使用NPU辅助计算提升本文测试中表现较为薄弱的prefill性能。
IOMMU
目前Linux平台只有关闭IOMMU或静态分配显存才可以完全发挥显存性能,这不符合对iommu=pt表现的预期。经过初步测试发现启用IOMMU或iommu=pt均会导致GPU随机访问>16MB内存的延迟由220ns提升到>600ns,显然是与IOMMU的IOTLB有关,这一表现在其它主流APU上也可以复现。理想情况下APU的GPU不应该需要依赖IOMMU来实现UMA,因为其本身有GPUVM可以支持内存地址映射。
由于NPU对IOMMU具备强依赖,因此最终依然需要AMD解决iommu=pt配置下GPU访问UMA地址性能较差的问题,以便为未来同时使用GPU与NPU打下基础。
测试结论
如果与M4 Pro平台对比,那么Strix Halo毫无疑问是一个相当有竞争力的平台。尽管其在最纯粹的单用户文本生成场景的速度要略慢于M4 Pro,换来的却是其它场景的全面提升。甚至在投机解码的情况下可以使用比M4 Pro大一倍尺寸的模型。
但如果你只将Strix Halo与M4 Pro对比,那么则掉入了非常明显的陷阱:相近价位并不是只有Strix Halo这类LPDDR平台可以运行LLM。由于理论参数接近,Strix Halo运行LLM的舒适区与M4 Pro相同,依然是低于20 GB的4bit模型。它的内存带宽本身也导致其更多的是4060级别显卡的替代品,最高128GB的内存容量并没有特别大的用途,反而会因为价格太高而在更高阶的图形卡LLM方案面前失去性价比。
基于以上这些分析不难看出,正如我几个月前所述,类似Ryzen AI Max 385搭配32GB内存的ITX主板方案($799)才是Strix Halo的甜点。
更大内存的版本主要面向其他生产力(尤其是对带宽有需求的CPU计算场景)而非纯粹面向LLM。例如,我个人购买395 + 64GB内存的Strix Halo笔记本电脑就主要是看重其CPU可用的读写各120 GB/s带宽对大型C++软件项目构建速度的提升,本地日常后台运行一个32B参数的LLM作为辅助用途而非主要用途。相比之下,385 + 32GB组合无论是作为一个常规游戏、计算设备还是LLM设备,它都能在提供4060级别性能的情况下彻底解决4060显存不足的问题,本身的价格也具备相当高的性价比。在完成全套LLM测试后,这依然是我最推荐的组合。
笑死,最近还在寻思要不要把HX370 换ai max 395。按照目前的情况来看,其实HX370就够用了,更大规模的模型不如换V100得了。只是64G的HX370稳定性较差
请教一下大佬,Strix Halo理论上不是256bit的内存位宽吗,怎么cpu的读写才120GB/S(本来还期待着搞一台用来跑CFD的。。。)
因为CPU每个CCX只有32B/cycle的读取速度,2GHz FCLK下也就是接近60GB/s。纯读取确实比我之前的预期要差一些,不过实际Strix Halo在读写混合的应用里应该优势最大,表现如何可能需要实测。
听说是CPU CCX内互通的带宽要减半,如果是GPU内通信,就是满带宽
主包,PTL出了,主包打算什么时候测试呢,你是众多媒体里我唯一信任的人了