早些时还在装7970X TR机器的时候我就在物色各种大显存显卡想拿来本地跑70B LLM,奈何一直没有合适又便宜的解决方案:正经的A/N计算卡或者48G VRAM的NVIDIA GPU太贵,闲鱼上便宜的数据中心拆机卡(L20等)需要折腾散热,原版W7900又是三槽卡,跟我机箱主板合不来。
相比之下新发布的W7900DS不仅可以完美适应我的需求,甚至官方标价比原版W7900还便宜500刀。因此发布后不久我就找AMD的熟人问了一些门路,在国内到货的第一时间买到了这两张售价相对比较便宜的黑色高级显卡。


LLM方案选择
对AMD GPU/ROCm支持比较好的流行开源LLM方案大体上分为两类:
- 基于GGML (如llama.cpp)
llama.cpp应该是目前所有consumer平台上最成熟的开源LLM解决方案了。套壳软件无数,从Apple Silicon到AMD APU再到各种独显都能跑,还支持多GPU。虽然它对GPU的性能优化相对比较一般,但好在基本能用。
示例:./llama-server -t 16 -c 32768 -m ~/models/llama3/llama3-70B/llama3-70B-q8.gguf -ngl 128 -np 16 -cb -fa –host 127.0.0.1 –port 8000 -sm row -mg 1 - 基于PyTorch (如vLLM)
vLLM+GPTQ虽然是AMD PPT上的御用方案,但是AMD的开发重心在Instinct,其Radeon支持还远未成熟。目前只有AMD的一个fork版本可以在Radeon上较好地工作,而主线vLLM在Radeon上的功能支持暂时还不全(例如GPTQ支持等),所以它当前属于战未来方案。
示例:docker run -it –name=vllm –network=host –group-add=video –ipc=host –cap-add=SYS_PTRACE –security-opt seccomp=unconfined –device /dev/kfd –device /dev/dri/card0 –device /dev/dri/card1 –device /dev/dri/renderD128 –device /dev/dri/renderD129 -v /mnt/models/vllm:/models vllm python -O -u -m vllm.entrypoints.openai.api_server –host=127.0.0.1 –port=8000 –model /models/Meta-Llama-3-70B-Instruct-GPTQ/ –max-model-len 8192
其他的框架大部分理论上也可以支持,例如llama有好几个onnx移植。不过显卡刚拿到手不到一周时间,因此只能在几个比较熟悉的方案里选择。
前端的选择就相对简单,使用ollama项目的open-webui对接llama.cpp/vLLM的OpenAI-compatible server即可。例如使用Docker: docker run -d –network=host -v open-webui:/app/backend/data –name open-webui –restart always ghcr.io/open-webui/open-webui:main
一些遇到的坑
- Debian内核没有打开PCIe P2P支持,使得llama.cpp -sm row的多GPU不工作,表现为crash在cudaMemcpy2DAsync(cudaMemcpyDeviceToDevice)。
在没有PCIe P2P的情况下,llama.cpp 多GPU只能使用layer partition模式,无法发挥出多GPU的性能优势,只能发挥显存容量优势。解决方法是换Ubuntu内核,或者自己编译内核打开CONFIG_PCI_P2PDMA和CONFIG_HSA_AMD_P2P。 - 运行ROCm程序容易触发GPU MES报错
解决方法是升级到最新的Linux内核以及linux-firmware/amdgpu固件,或使用官方支持的内核版本以及dkms内核模块;尽量不要使用跑计算的卡来输出桌面图形或者运行游戏,可以使用核显或者单独的亮机卡。 - vLLM在没有请求时也会持续占用GPU,产生每张卡约150w的功耗
- vLLM使用Linux upstream amdgpu内核模块并不总是能可靠工作,使用dkms内核模块可以解决很多问题。
尽管vLLM的Radeon支持目前依然比较初级,但是它在Radeon GPU上的单卡性能确实比llama.cpp要强不少(尤其是在后文中提到的prompt processing这一薄弱环节),因此可以留有一些小小的期待。
性能测试
使用llama.cpp项目的llama-bench对llama-3 70B q8_0量化模型进行性能测试,模型大小约69GB。实测3张24G显存的GPU刚好不够用,因此最少需要4张4090/7900XTX或者两张RTX 6000 Ada/W7900。
其中多卡分别使用layer split与row split两种模式进行测试。
- 使用layer split模式时,LLM的不同层分散在不同GPU上。单个用户运行LLM推理时,只能轮流使用多GPU而不能并行使用。layer split模式可以充分利用多卡的显存,但多卡性能完全无法叠加。
- 使用row split模式时,LLM的矩阵计算被直接分布在不同GPU上。单个用户即可充分发挥多卡的性能优势。但这种模式对多卡互联有一定的要求,本代无论是Navi31还是AD102都砍掉了XGMI/NVLINK因此PCIe带宽会成为一个主要的制约因素。
两种模式的测试命令分别如下
- ./llama-bench -m ~/models/llama3/llama3-70B/llama3-70B-q8.gguf -ngl 999 -fa 1 -n 1024 -t 8 -sm row -t 8 -sm layer
- ./llama-bench -m ~/models/llama3/llama3-70B/llama3-70B-q8.gguf -ngl 999 -fa 1 -n 1024 -t 8 -sm row -t 8 -sm row
每一组测试分为两个结果
- prompt processing 即LLM对用户输入的文本进行处理的步骤,测试长度为512个token
反映了用户日常使用LLM的响应延迟(尤其是当对话次数达到一定长度后),以及处理大量文本工作的吞吐(例如全文翻译、总结等用途)。prompt processing的性能瓶颈一般偏向于CU吞吐能力,尤其是matrix单元。 - text generation 1024 token 也就是生成文本,测试长度为1024个token
反映了LLM输出文本的速度。一般运行较大的模型时,主要性能瓶颈在显存带宽。
测试结果
声明:W7900DS以外的测试均为非可控的云端环境采集,CPU平台和运行环境都没有严格控制变量,因此发出来纯粹图一乐。
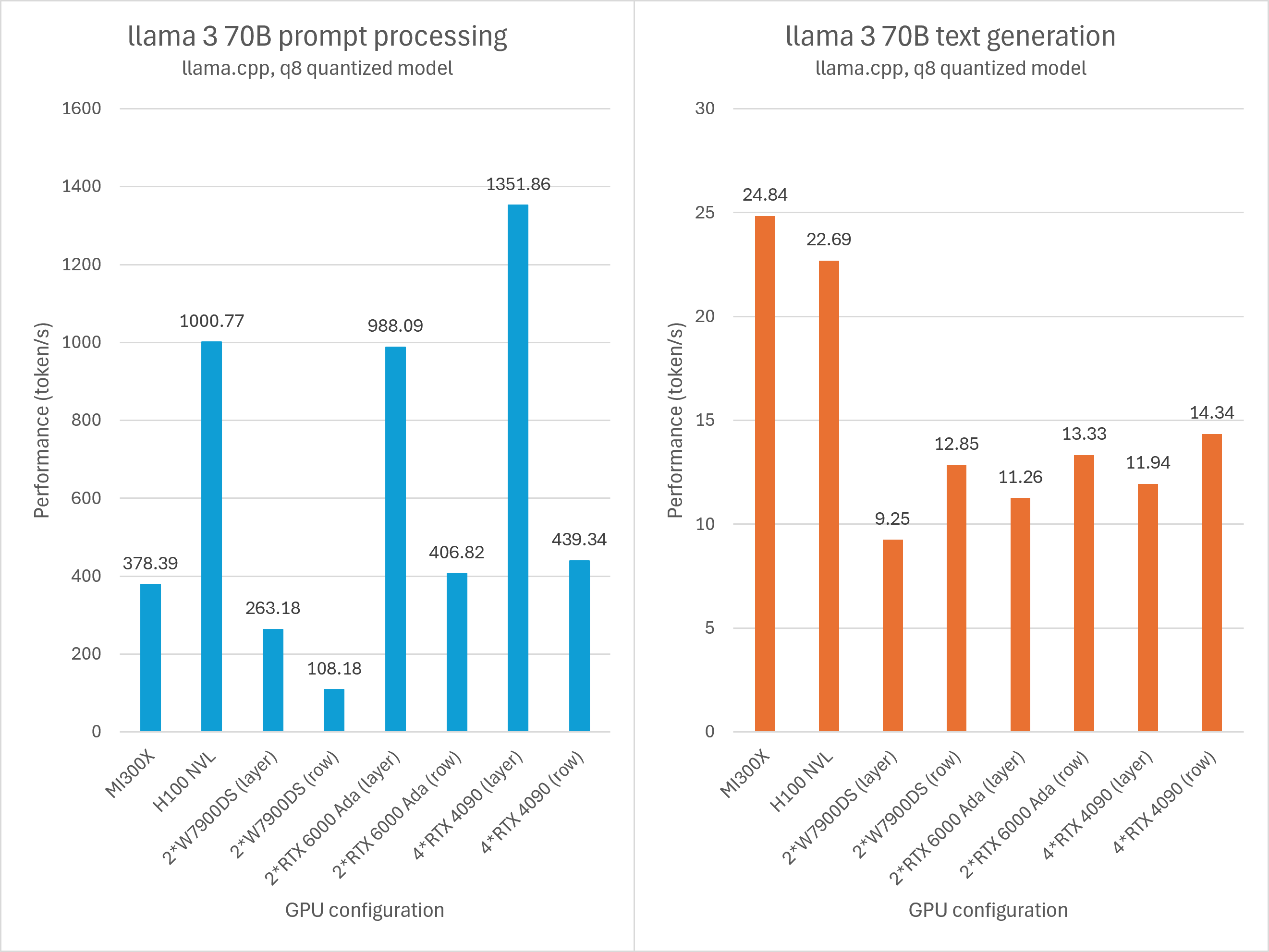
可以发现AMD GPU在prompt processing阶段的表现不佳。无论是MI300X/H100这种名贵计算卡神仙打架,还是W7900/RTX6000Ada/RTX4090这种廉价图形卡互殴,AMD GPU均被同级别NVIDIA GPU以3-5倍的性能碾压。
粗略分析,一方面prompt processing比较吃matrix单元的吞吐,Radeon图形卡的劣势巨大;另一方面软件优化也可能存在差距。后者对Instinct的影响可能更明显,例如可能没有充分利用matrix core。这是因为MI300X这方面的理论性能比H100更强,不像Radeon连理论性能都有数倍的巨大差距。日后软件更新如果有明显的性能改善,我会更新这个图表和结论。
不过在text generation方面,无论是Instinct还是Radeon都毫不逊色,尤其是W7900DS在row split模式下与双卡RTX 6000 Ada性能差距非常小。
需要注意的是,在数百到数千token/s的prompt processing速度的前提下,实际使用中就算是非常长的对话上下文,prompt processing性能差异对用户带来的感知也相对有限。因此综合来看Radeon方案也有它的特色。
当然,llama.cpp对两家GPU都不是最优的解决方案。例如W7900使用vLLM+GPTQ量化运行llama 3 70B时单卡text generation就可以跑到17 token/s左右,prompt processing也明显更快;NVIDIA也有更快的TensorRT-LLM方案。对于计算卡来说更甚:llama.cpp从来没有针对计算卡专门优化,测试单用户吞吐也不是计算卡唯一的性能指标。计算卡运行单用户llama.cpp的性价比甚至远不如GDDR图形卡。
不过各家使用不同LLM量化框架运行LLM,本质上也是在跑不同的东西。这部分性能就比较灵活多变了,测试起来相当麻烦,不如多参考各家第一方PPT。
总结
双槽涡轮工作站卡是目前运行70B LLM成本最低的方案之一。尽管Radeon软件还有优化空间,从实际测试的性能来看也是一个可以考虑的方案。接下来我会将这套LLM系统集成到日常工作流中,更深入的体验这个方案,同时也会尝试继续对性能进行一些优化。今天就暂时水到这里了。
AMD的熟人(×)
可爱农宝(√)
打卡轮子妈
一年过去了,等一个更新
两张图形卡跑LLM(还有搭配cpu/apu核显)的玩法还是太多太杂,平时twitter上零散的更新过一些,不过整理成一篇文章还是比较困难。。