前些时我提前玩到搭载Strix Point (Zen 5)的工程机,不过当时由于时间仓促导致微架构测试不够全面,外加早期微码并不能完全发挥处理器的性能,所以整个测试偏娱乐。本文会针对前一次测试进行补充。
指令吞吐更新
在指令吞吐方面,需要更新的内容不多,但发生变化的却都在非常关键的位置。
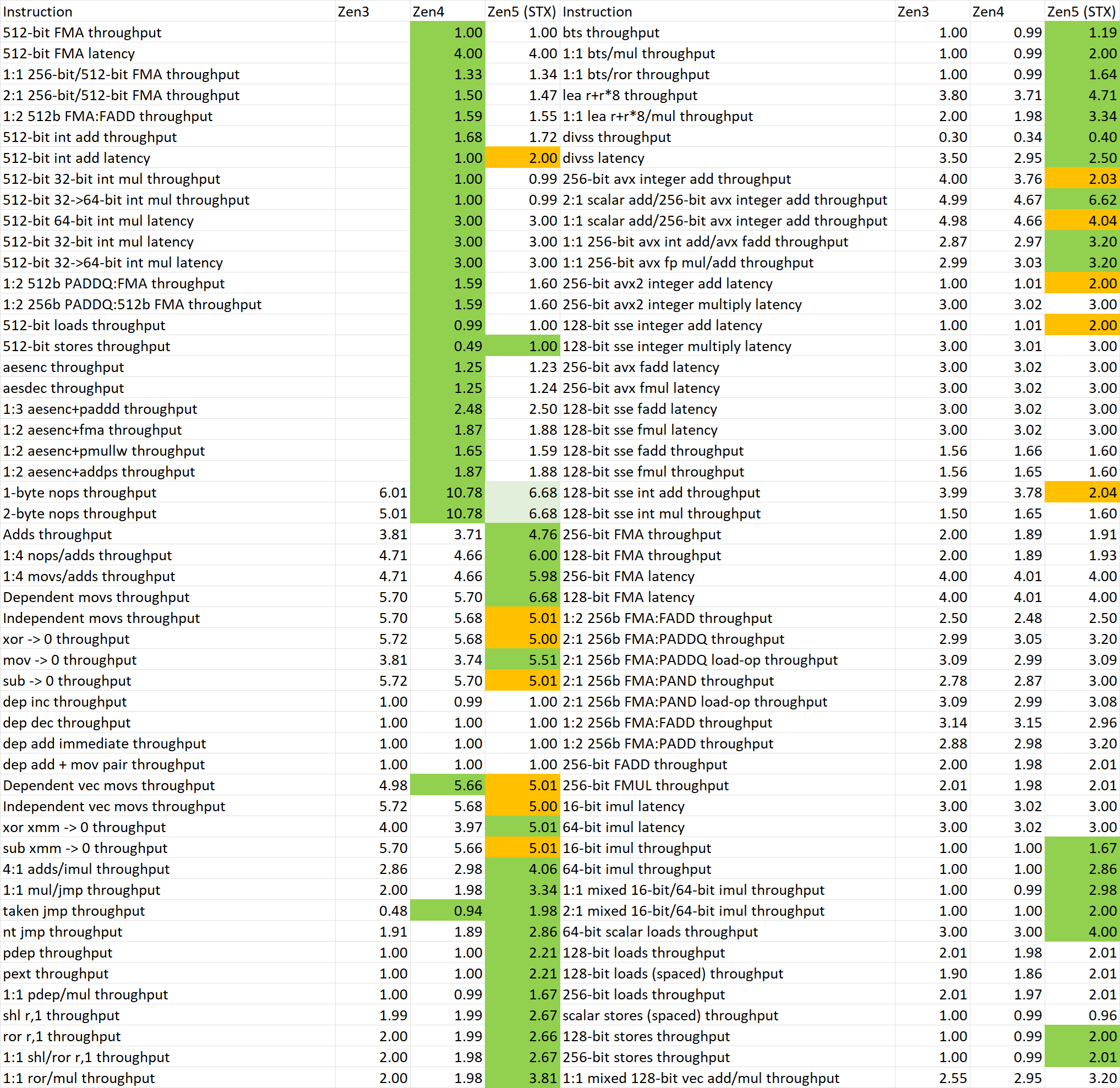
主要更新内容:
- 2-byte NOP吞吐现在与1-byte NOP相同,均为6.7附近,而上次测试时2-byte NOP吞吐显著低于1-byte,甚至不如Zen 4水平。这代表着特定场景下前端解码能力发生了一些变化;
- taken jump的吞吐略有提升,从1.77提升到2附近。这代表特定场景下前端分支处理能力获得了一定提升;
- 2:1 256bit FMA:PADDQ/PAND + memory operand混合操作的吞吐从2.7提升到3。这说明之前的固件在有混合指令的情况下针对性能进行了限制,可能与指令融合等功能有关。
此前进行指令吞吐测试时,我在大核和小核上分别运行测试,并确认输出没有大的差异,因此可以排除测试误差。可以看出AMD在此前的微码里有意限制了处理器前端以及部分指令组合的性能。这也是为什么我们通常不能轻易相信ES乃至QS处理器的测试成绩。
微架构内部结构
处理器微架构升级的常规操作之一是调整各个内部结构的容量和性能,并且高性能的核心一般以增加为主。对比Zen 5与其前一代,我们很容易看出许多结构得到了大幅度的容量扩充。
由于官方已经给出了非常详细的微架构内部结构信息,这一部分直接以官方为准,我就不放自己测试的结果了。需要注意的是,由于高性能微架构内部是一个黑盒,我们常用的micro benchmark测得的数据并不能完全反映这些实际数值,或多或少会有一些差异。
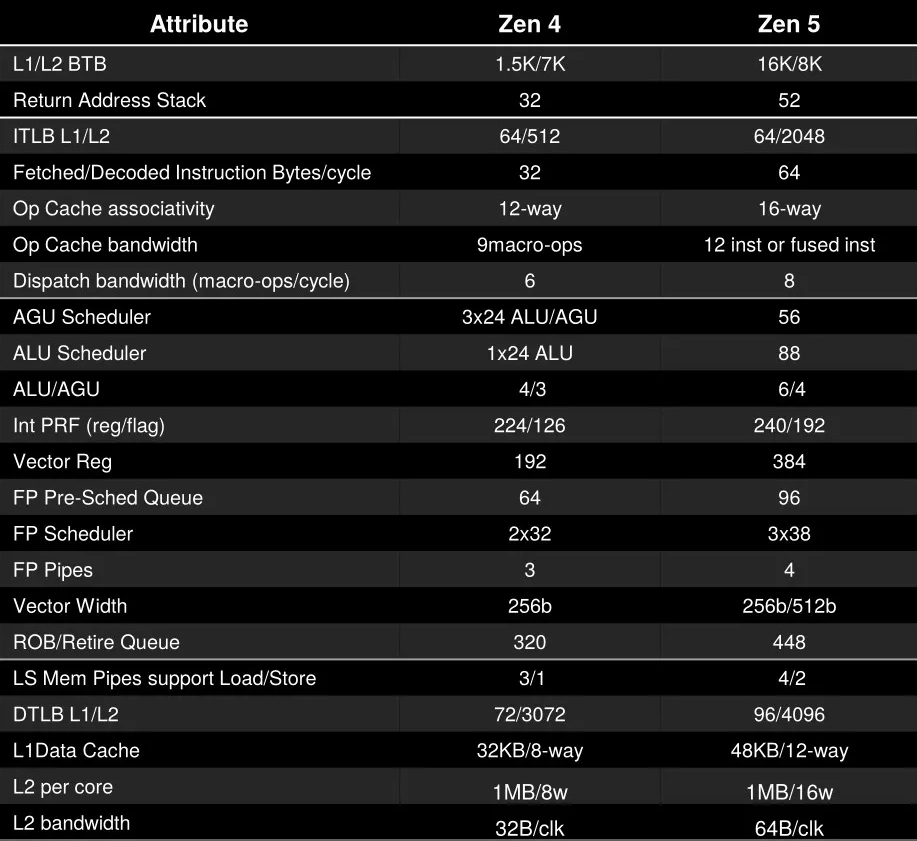 Strix Point的向量寄存器
Strix Point的向量寄存器
上述AMD官方给出的向量寄存器容量描述的是具有完整512bit向量数据通路的桌面处理器,但Zen 5其它版本基本上都将向量单元的吞吐减半。在Intel处理器上我们通常能观测到与之相对应的寄存器容量缩减,而AMD处理器也能观测到这个现象。
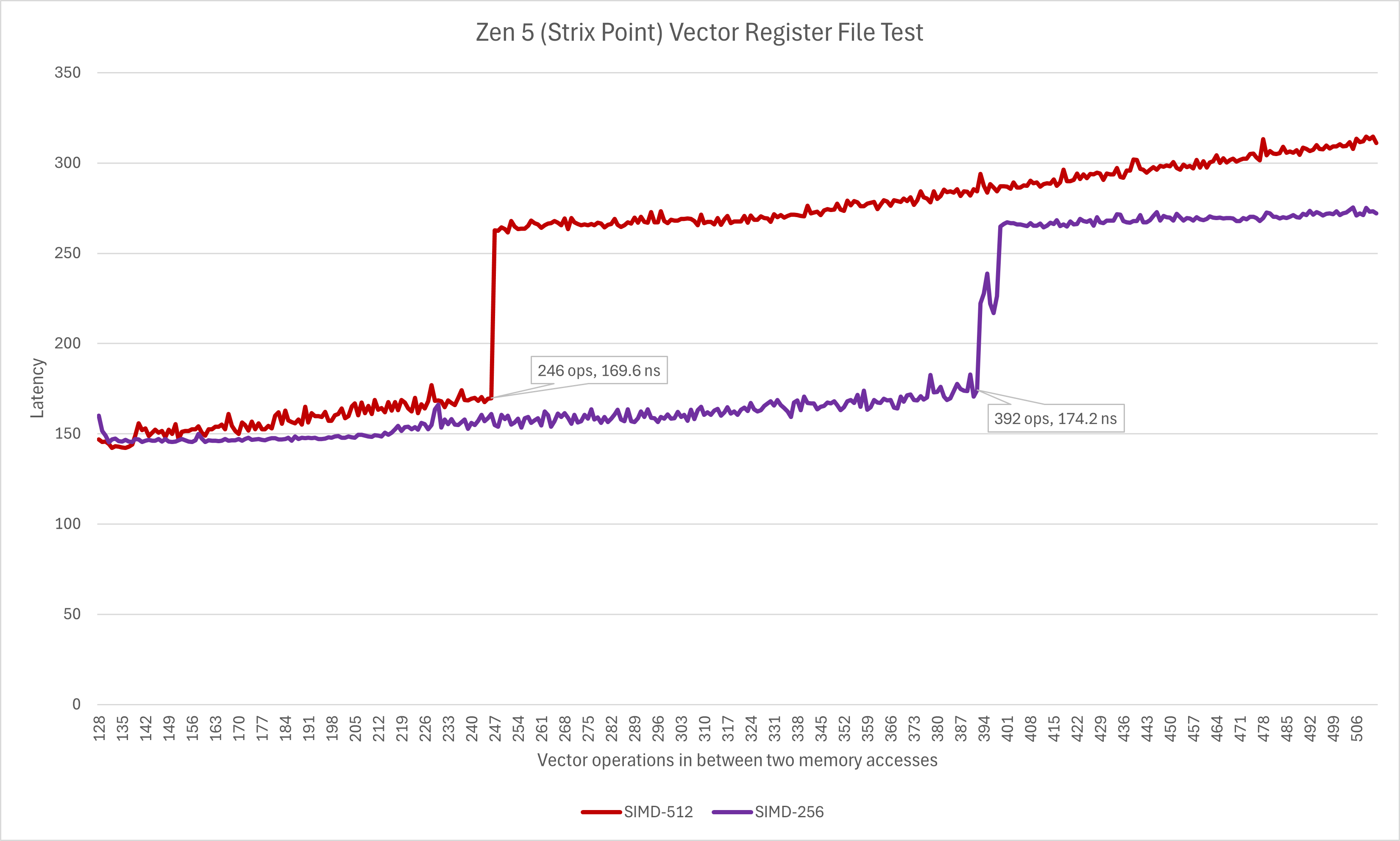
如图所示,通过测试两次访存之间插入不同浮点操作次数的延迟差异,我们可以观察到512-bit向量操作可探测到的寄存器的容量大约是256-bit向量操作的二分之一再加50-60左右。
分支预测
分支预测是现代处理器的重中之重,也是本次Zen 5微架构最让人感到惊艳的部分。本文主要从BTB容量/延迟,分支历史追踪能力以及处理器分支预测性能实测三个方面来对比Zen 5与其它微架构。
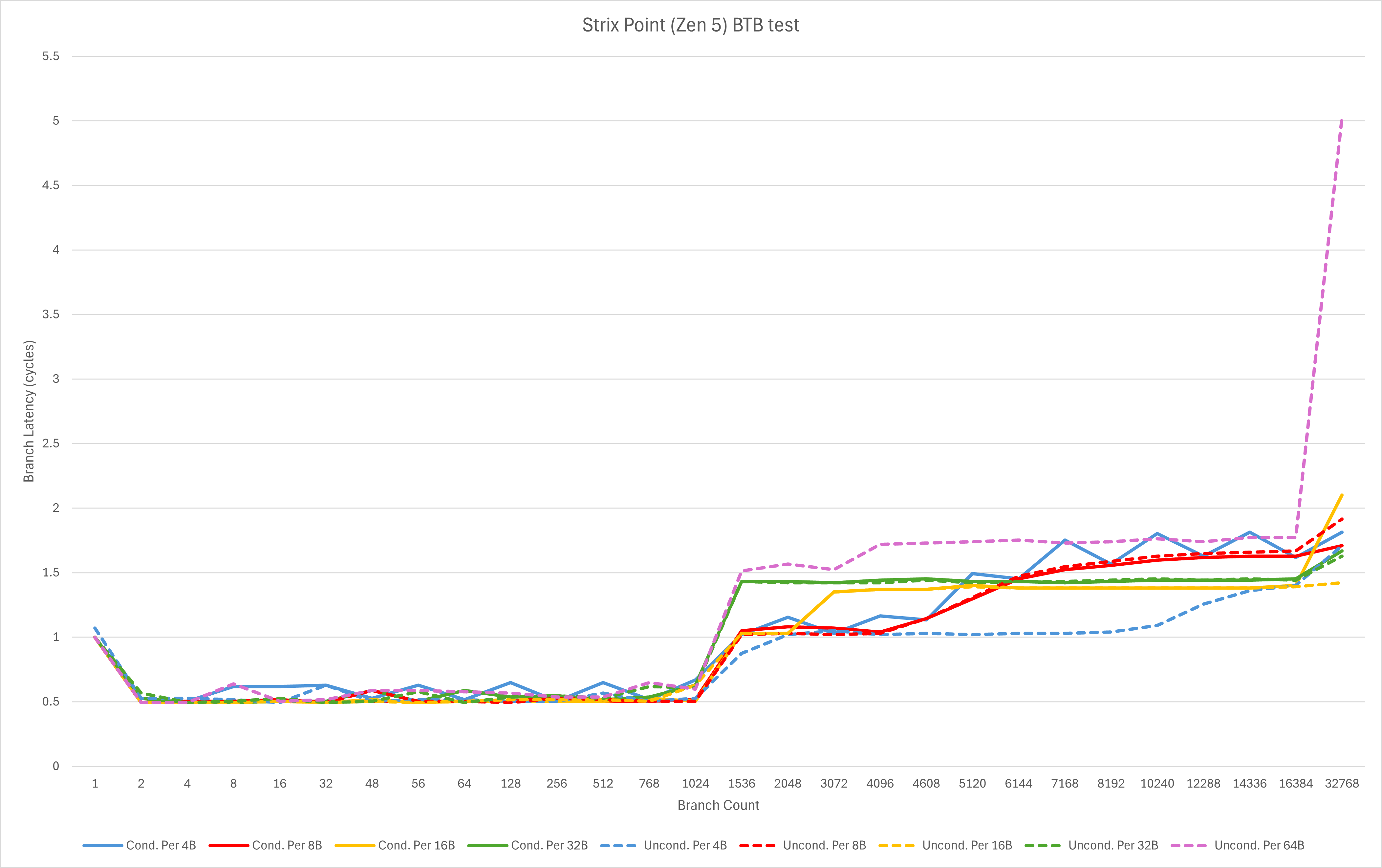
深不见底的超低延迟BTB
Zen 5
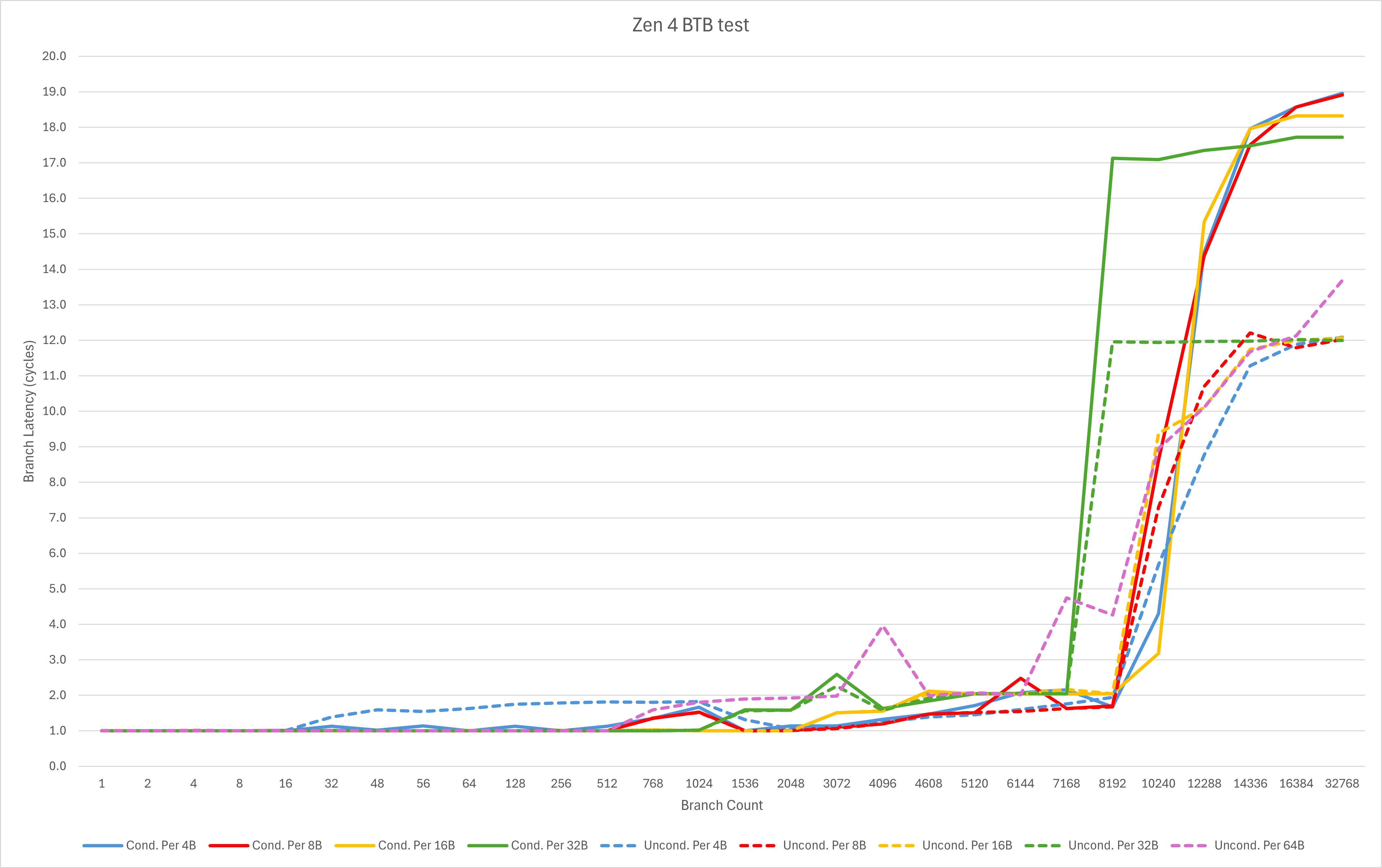
Zen 4
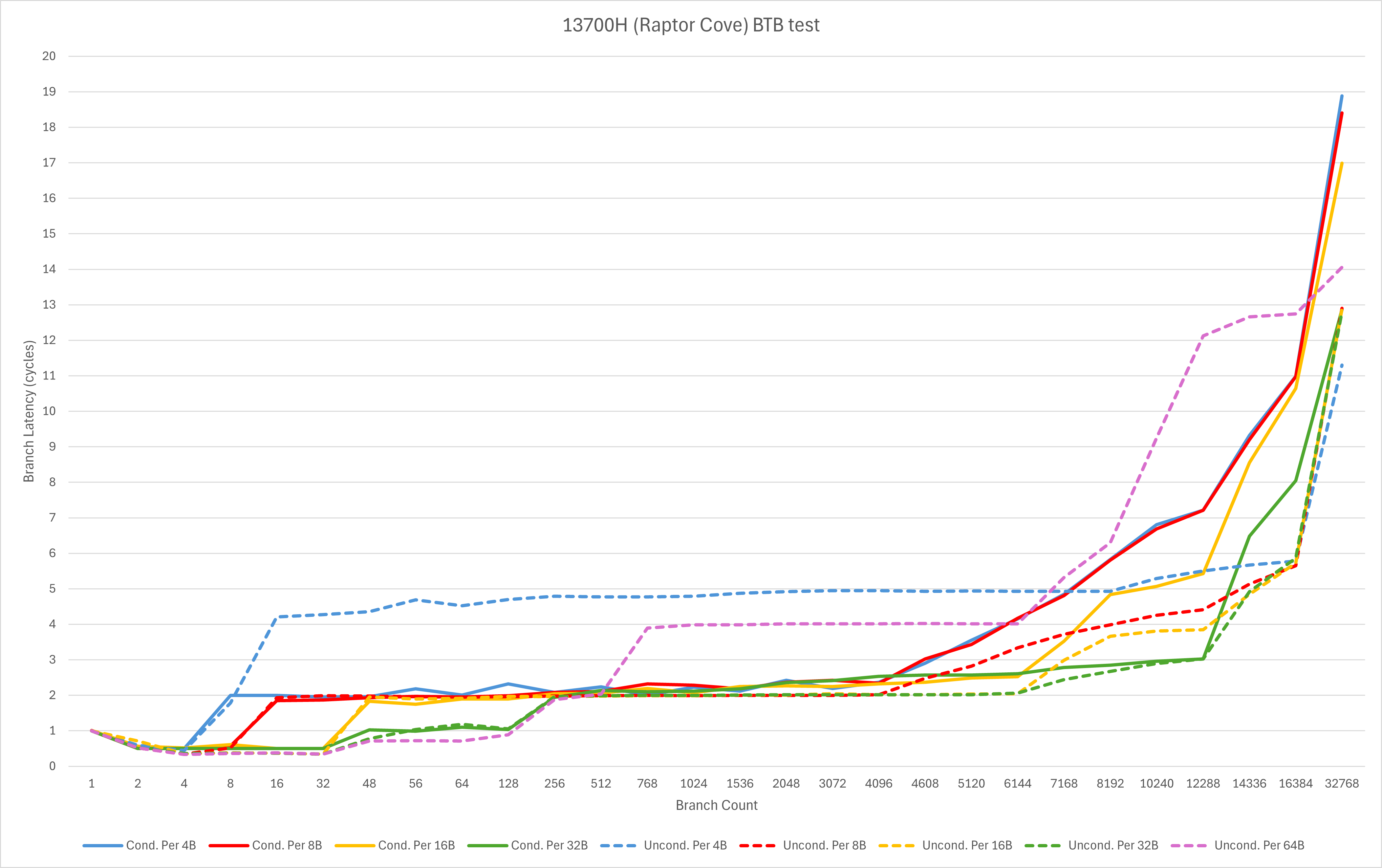
Raptor Cove
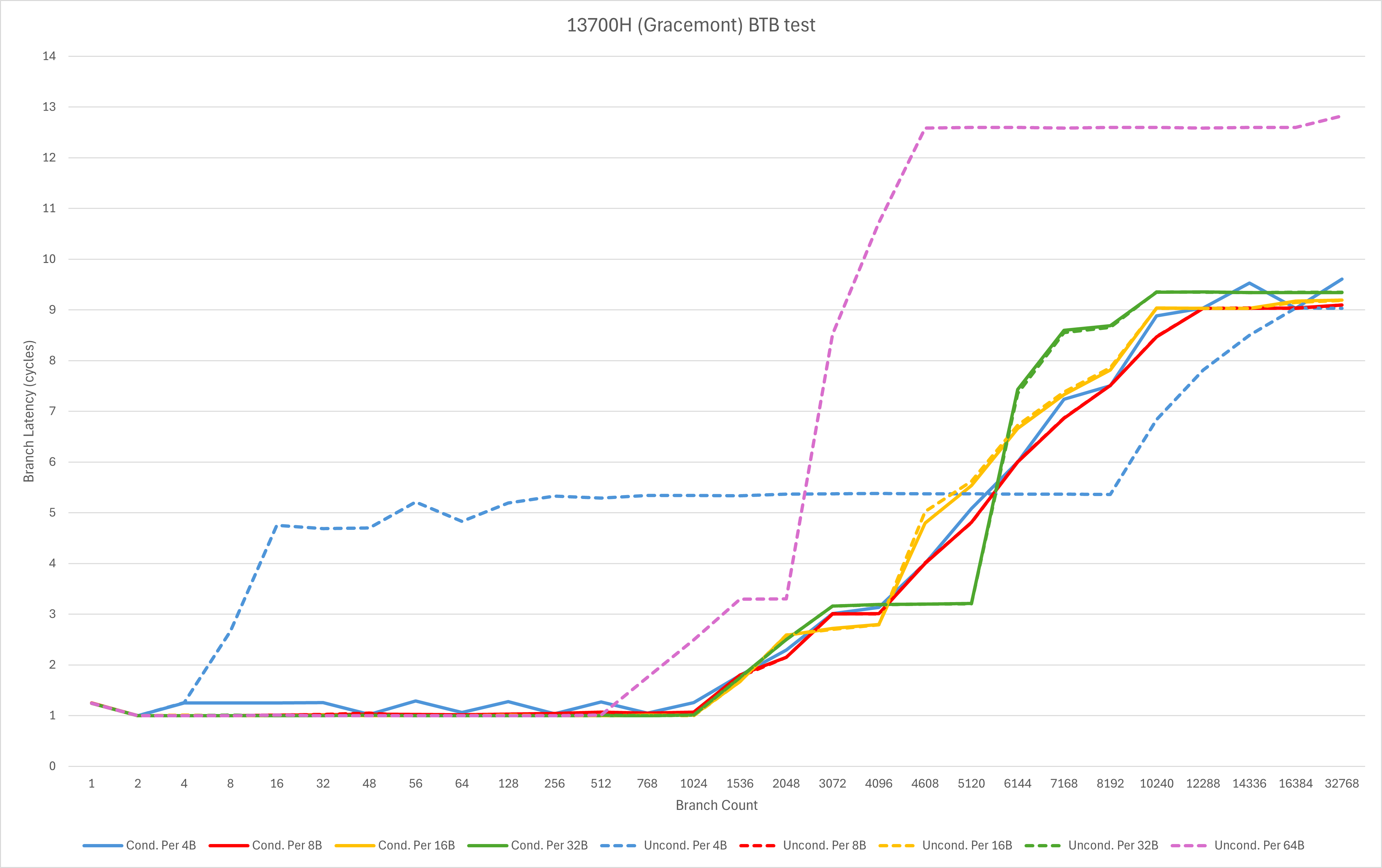
Gracemont
由于Zen 5具备每个周期处理两个taken branch的能力,其分支预测命中时的等效延迟会降低到传统微架构的一半。也就是使用传统的Microbenchmark测试工具需要以“0.5周期”为一个基本单位。
从下方的实测数据我们可以很容易看出Zen 5的前两级BTB:
L0 BTB: 1024 entry, 等效延迟0.5周期;- L1 BTB: 至少16384 entry, 等效延迟1周期;
2024/08/02 更新:Zen 5实际上并没有L0 BTB,其对应的是op cache的1024个entry。当我们手动关闭op cache后(wrmsr -a 0xc0011021 0x20000000000060),可以看到以下数据:
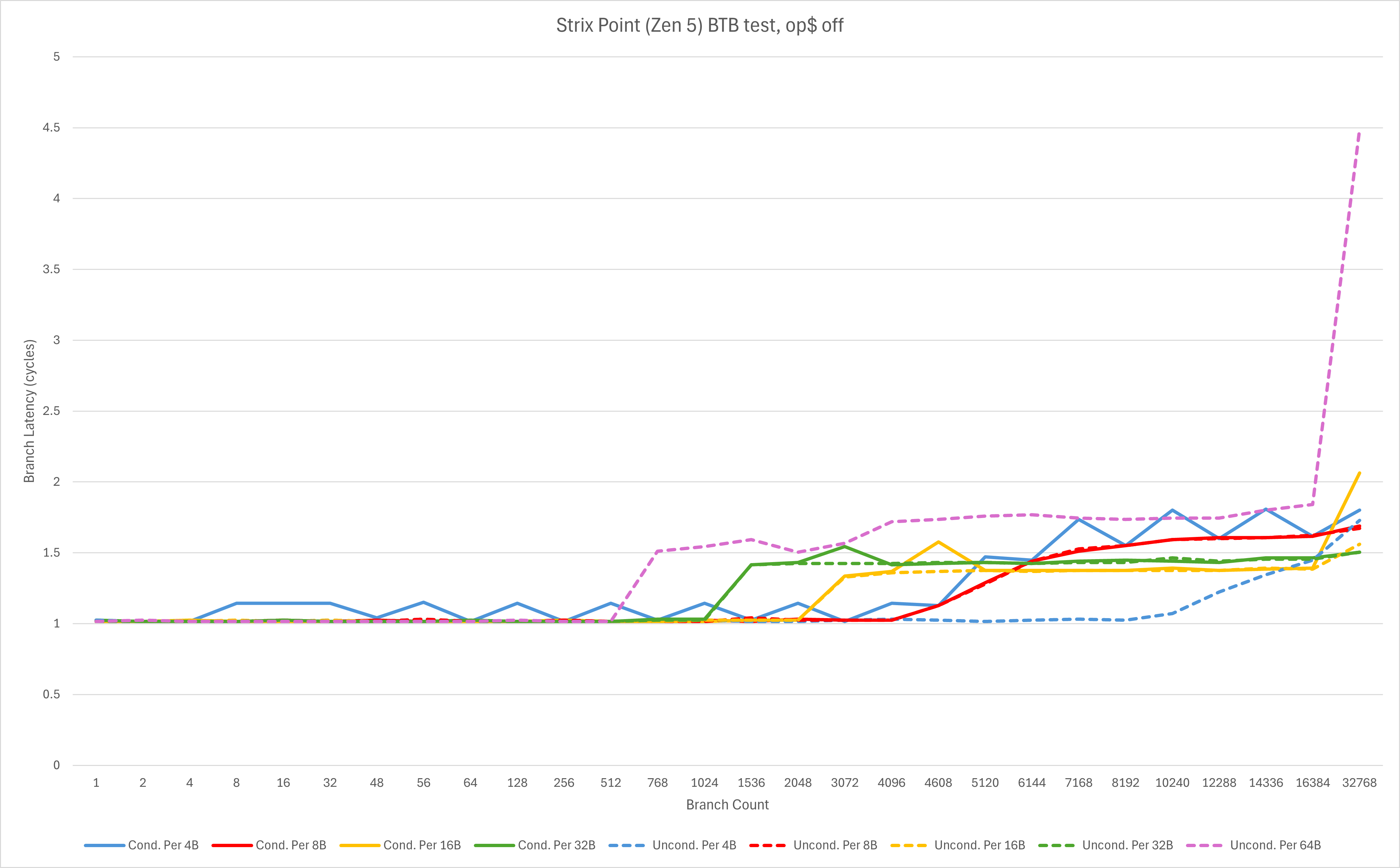
图中的延迟上升主要对应着L1缓存(32B*1024 = 16B*2048 = 8B*4096 = 32KB),也就是code footprint超出L1缓存,在L2缓存内会导致taken branch的等效延迟略微上升。另外,与AMD前期接受采访时的宣传不同的是,在当前微码版本的测试里我们并未观测到x86前端双解码的存在,只能在op cache里观测到这一点。这个问题还有待后续调查。
而AMD的PPT中提到还有一个8K entry的L2 BTB,由于测试数据没有精细到这个程度暂时无法观测到。但是可以看到的是,即便是32K个taken branch的场景,Zen 5核心依然在绝大多数场景维持了超低的等效延迟。
图表中可观察到唯一的例外是每64字节一个分支的测试,在超出16384个分支之后出现了延迟飙升的现象。经过计算很容易发现16384 * 64B = 1 MB,也就是延迟上升时的代码footprint已经超过了L2容量。再观察其它分支密度的测试在32768个分支时的延迟表现,结合一般x86代码的分支密度,我们可以判断Zen 5的分支预测在大部分L2区域内能以极低的延迟完成taken branch的跳转。这对于code footprint较大的程序来说是一个非常好的消息,前几代AMD在这方面与Intel相比都有不小的劣势,如今通过Zen 5一举实现逆袭。
与Zen 4相对比,我们不难看出Zen 5的BTB容量获得了巨大的提升,其超高容量L1 BTB使得几乎任何情况下可预测的taken branch都不再有什么额外的惩罚。
而与Raptor Lake的Raptor Cove相比,
- Intel有比AMD更健壮的loop buffer。Golden Cove之后在极小范围内可以实现单周期等效处理数个taken branch;
- Zen 5则是在整个巨大的L1 BTB覆盖范围内都能做到低延迟处理taken branch,在较大范围内容量和延迟方面均有明显优势。
Gracemont显然不是同一个级别的选手,但是Skymont在容量和分支预测准确率等方面则有显著的进步(剧透)。
值得注意的是,虽然Gracemont与Zen 5类似,有着理论上可以单周期处理多个taken branch的模块化前端,但是似乎并不能很好地被这些microbenchmark的测试场景所测试出。这可能是因为Atom的BTB做不到每个周期输出两个跳转目标,模块化前端只能发挥出缓解单次跳转打断当前解码指令流这类问题的作用。
此外,对于无条件跳转,Intel的微架构对目标地址有着更严格的要求。当跳转目标没有对齐到8字节时,会出现相当大的吞吐衰减和延迟上升。而这一点不仅能从上面的BTB测试中观察到,也在我们常用的microbenchmark里得到了体现:Gracemont在这个测试里的taken jump吞吐为0.5。而Zen 5的L1 BTB则相当宽松,对于所有的分支距离都能轻松处理,完全没有这个问题。
分支历史追踪能力
Zen 5
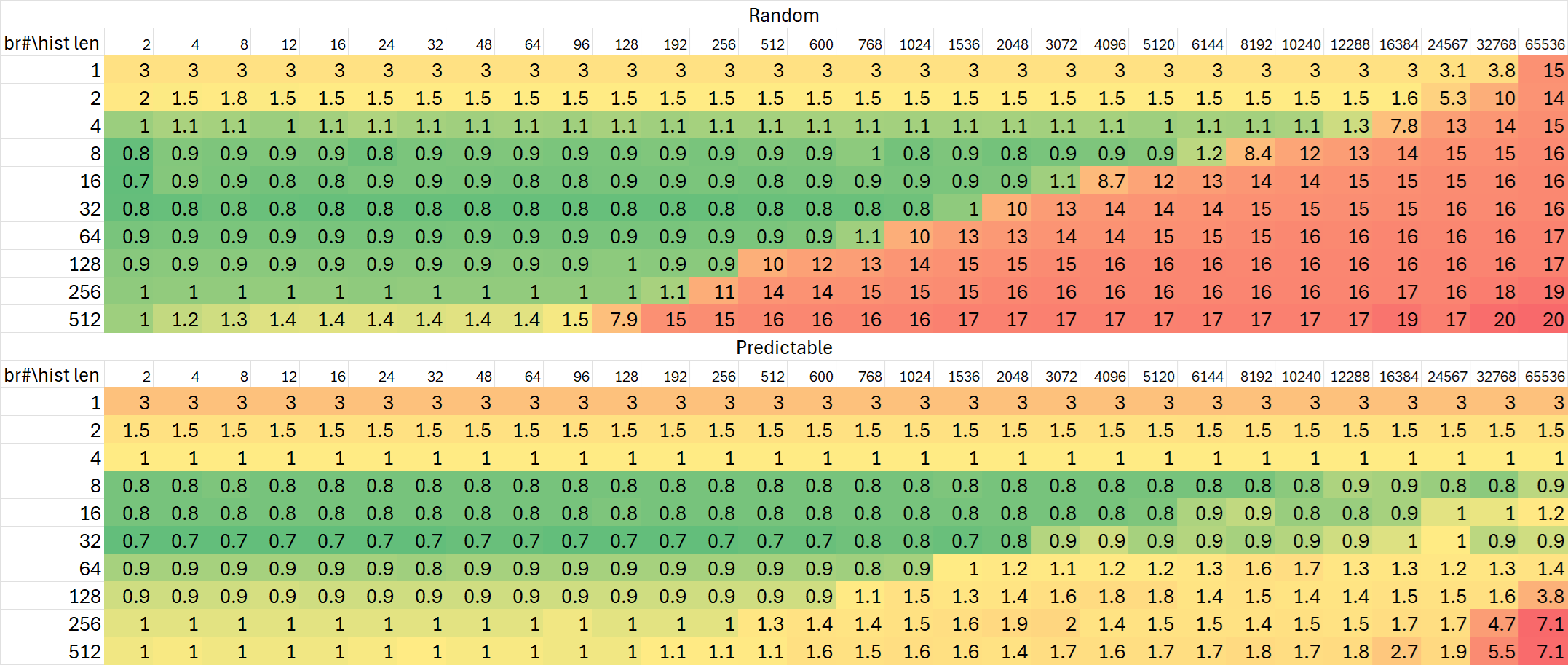
Zen 4
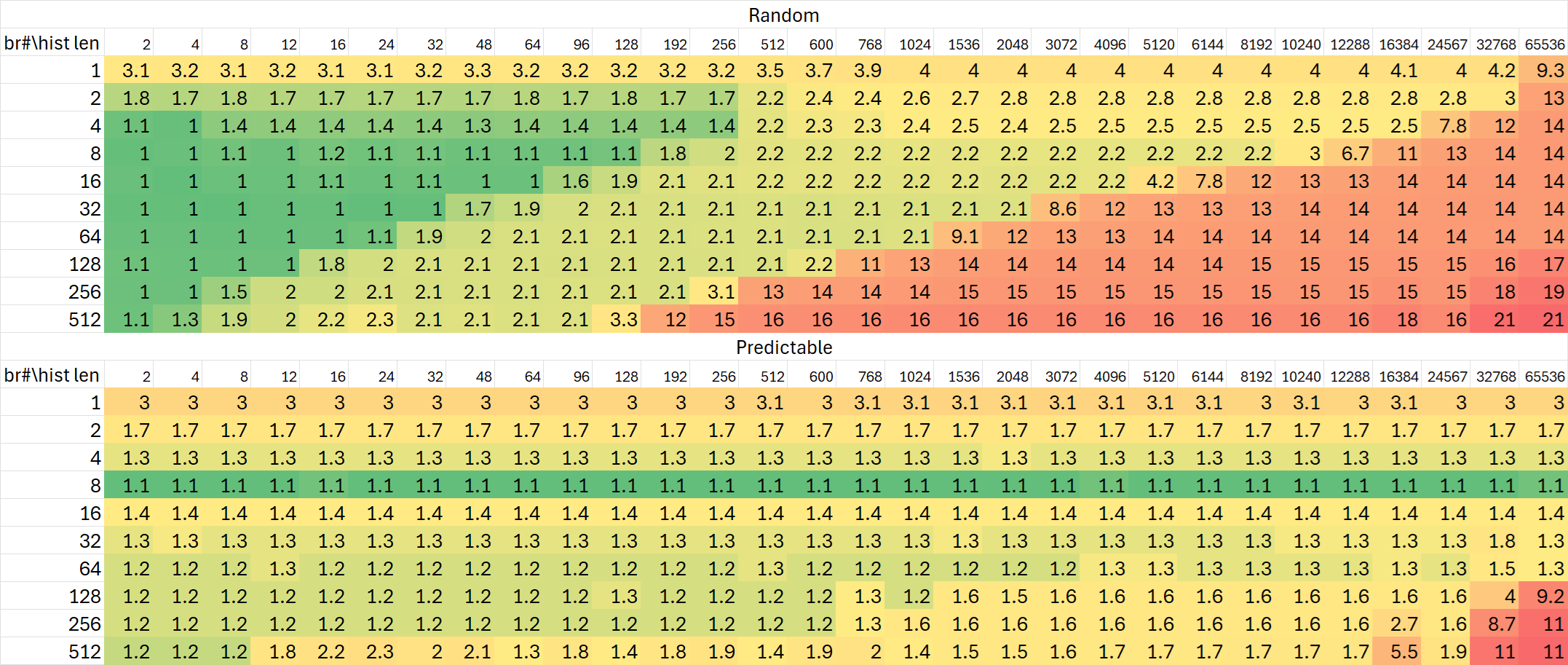
Raptor Cove
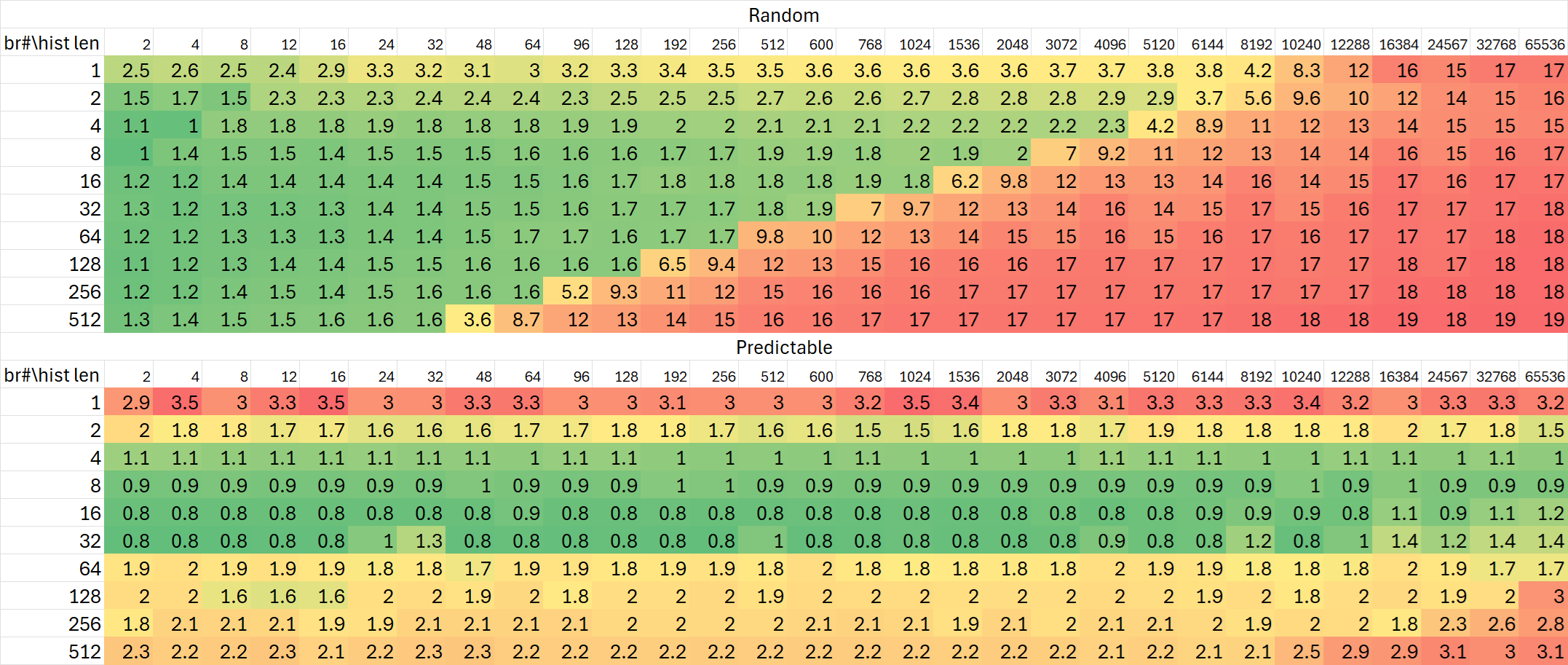
Gracemont
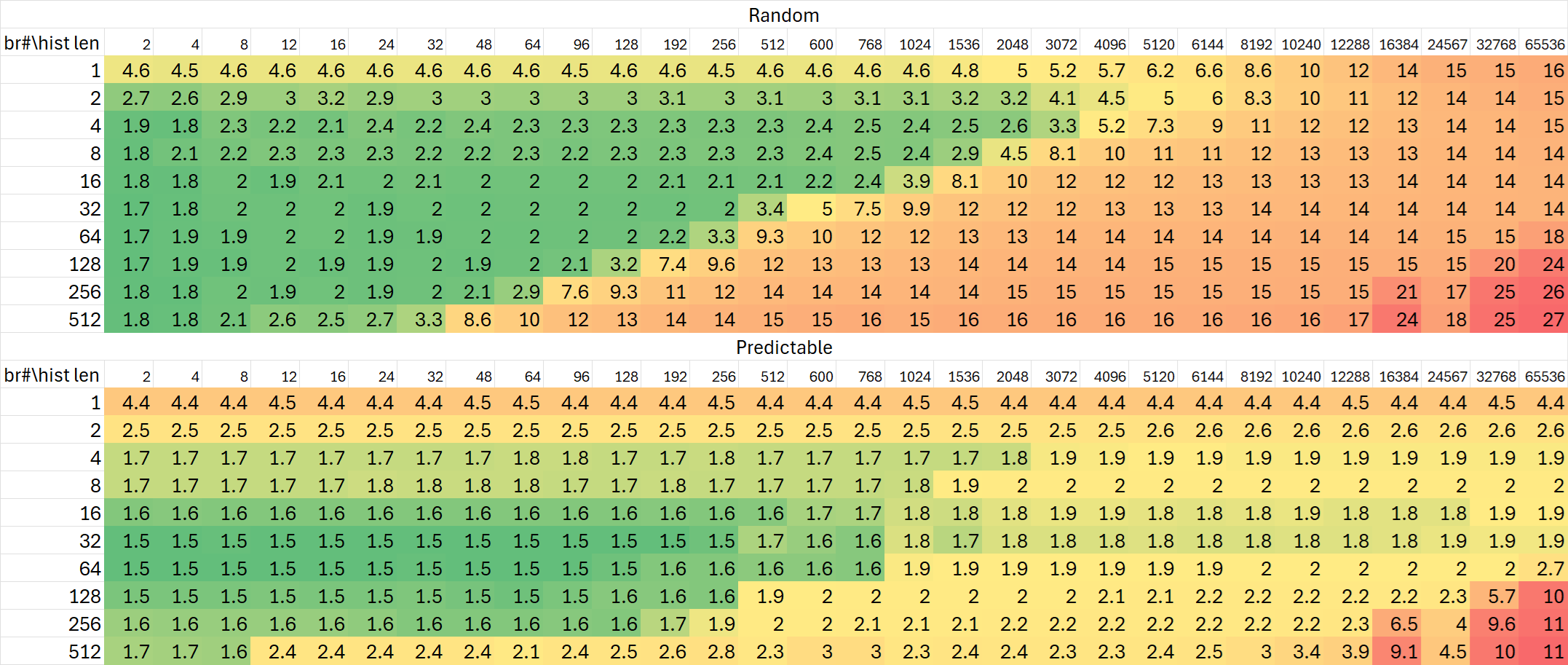
Zen 5的分支历史追踪相比Zen 4作出了不小改动。从Zen 4的测试图中我们可以看出非常明显的三个级别:
- 1K条目内延迟为1周期
- 64K条目内延迟为2周期
- 超过之后为14-16周期
而Zen 5则显得有些简化:
- 48K条目内延迟为1周期
- 超过之后为16-17周期,相比Zen 4延长了1-2个周期。
显然Zen 5将Zen 4的两个不同延迟的层级合并为一个低延迟的层级,但是容量略有缩减。
作为对比,Intel的Raptor Cove与Gracemont均可以追踪16K条目。Zen 5在这方面依然延续了AMD一贯的优势。
分支预测准确度
通过收集linux-perf的数据,我们可以对分支预测的实际性能进行验证。
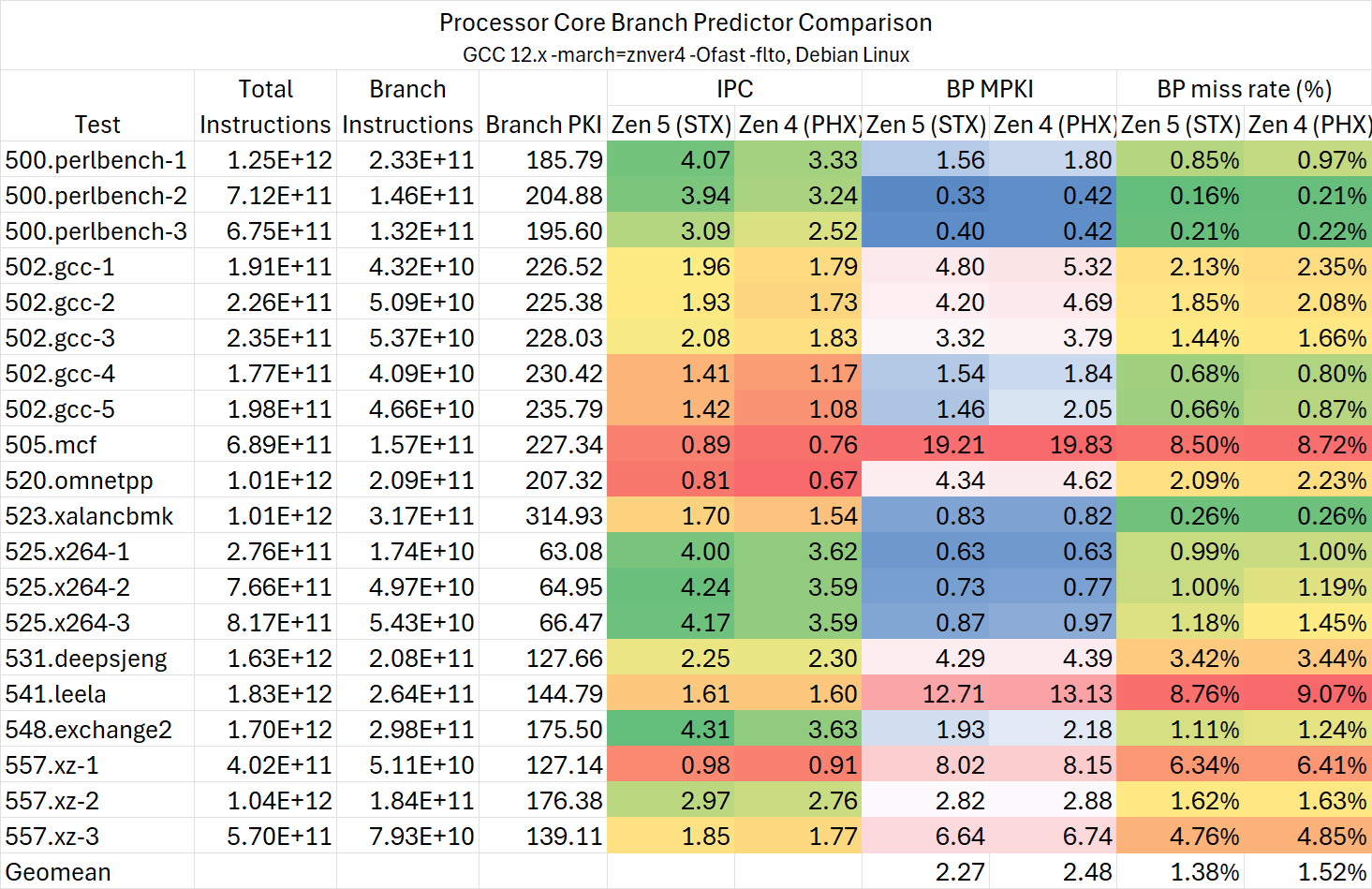
注意:处理器运行频率不同,IPC仅供参考,请勿直接对比。
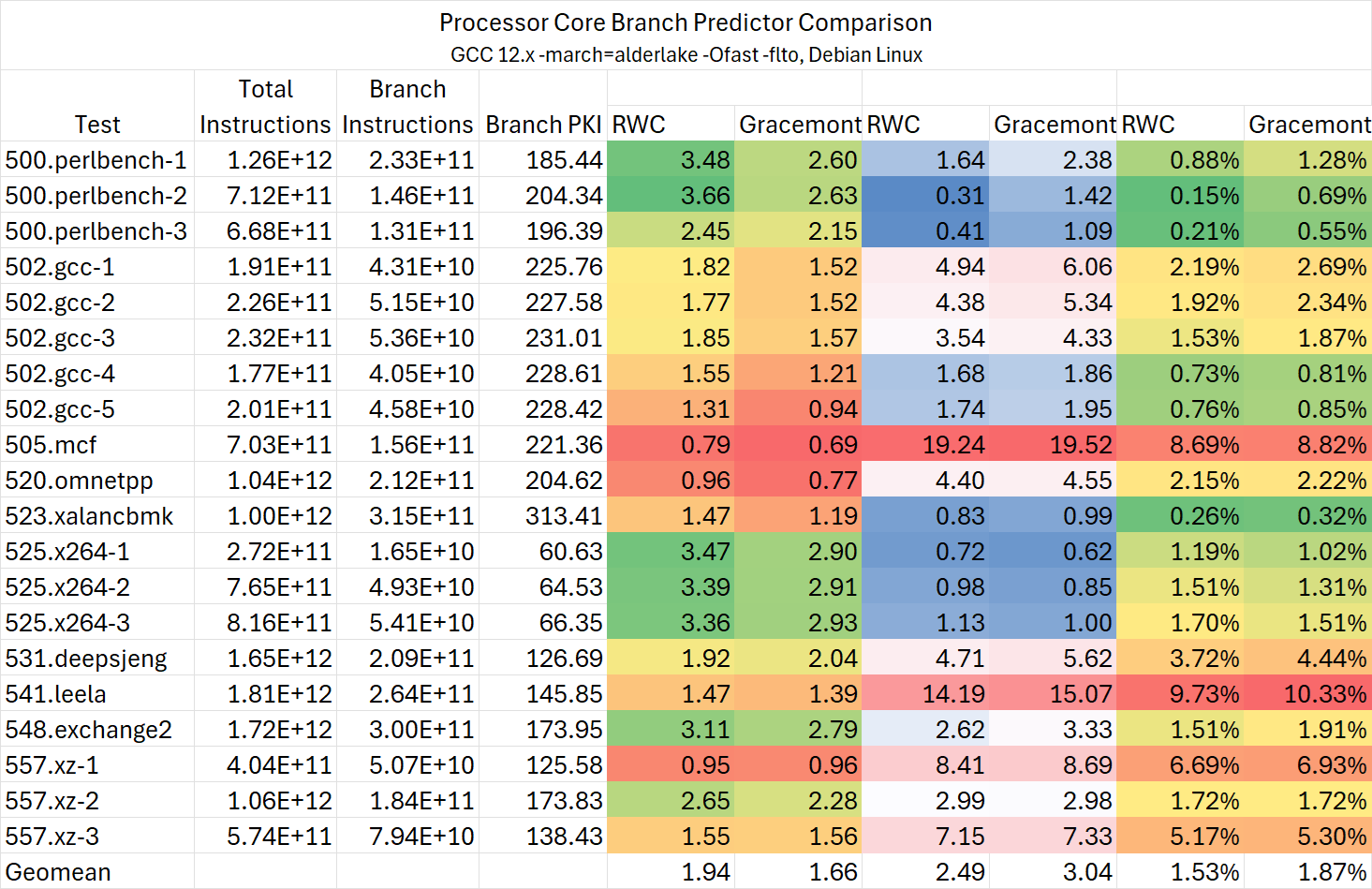
RWC取自155H,Gracemont取自13700H
可以看到,Zen 5的分支预测性能在本就已经很优秀的基础上再次带来了较为显著的提升,相比Intel则进一步扩大优势。
总结
从上述测试中我们可以看出,Zen 5的微架构确实做出了相当大的改动,尤其是最重要的前端部分。其中不乏一些相当令人惊叹的新设计,可以说是奠定了未来AMD64的发展基础。同时,在工艺和缓存/内存结构没有重大升级且处理器CCD面积几乎不变的背景下(N5P升级N4P,单CCX维持16MB L3),Zen 5做到了峰值性能的提升。
在下一篇文章中,我将会更新处理器的实测SPEC CPU 2017性能与能效,以及Geekbench 5/6的性能。
Fantastic technical testing and explanation. Thank you!
博主赶紧更新 更新 实测SPEC CPU 2017性能与能效,以及Geekbench 5/6的性能。
后续测试可能要等一段时间,因为现在的内核版本对Strix Point SoC的电源管理支持状况不太好,低功耗能效远不如Windows。另外分析performance counter也遇到一些小问题需要解决。
极限性能可能会先尝试暴力散热跑一个出来,不过这个也凑不齐一篇文章。
请问这种微构架级别的测试是什么工具测试的 ?
https://github.com/clamchowder/Microbenchmarks/tree/master/AsmGen
里面的测试项目很多
多谢~