AMD Ryzen 9 7950X3D 是 AMD 推出的旗舰级 16 核心处理器。它采用了创新的 3D V-Cache 技术,将 64MB 的 L3 缓存叠加在其中一个8核心的 CCD 上,从而显著提高了缓存容量。从现有的评测不难看出,这种设计使得 7950X3D 在游戏性能方面超越了 Ryzen 9 7950X,也超越了竞争对手 13900KS,并且更加节能。
本文包含一些简单的 Micro-benchmark,实测采用 3D 堆叠缓存的延迟、带宽等表现,并与普通 CCD 进行对比。除此之外,我还会加入 SPEC CPU 2017 的单线程整数测试,并附加少量的游戏实测数据,介绍大缓存在真实应用中的效果。
本文为独立完成,处理器以及其它配件均为自行购买测试。
由于 Zen 4 桌面版处理器首发时已经有不少详细的性能评测与微架构解析,前些时 7950X3D 首发评测也有不少性能评测,因此本文将以测试缓存的特性为重心。
基本参数
| 7950X3D | 7950X | 5800X3D | 13900K | |
|---|---|---|---|---|
| CPU 核心/线程数 | CCD0: 8核心16线程 CCD1: 8核心16线程 |
CCD0: 8核心16线程 CCD1: 8核心16线程 |
CCD0: 8核心16线程 | 大核: 8核心16线程 小核: 4模块16线程 |
| 缓存 | Op cache: 768*9/c L1i: 32K/c L1d: 32K/c L2: 1M/c CCD0 L3: 96M CCD1 L3: 32M |
Op cache: 768*9/c L1i: 32K/c L1d: 32K/c L2: 1M/c L3: 32M/CCD |
Op cache: 512*8/c L1i: 32K/c L1d: 32K/c L2: 512K/c L3: 96M |
大核 DSB: 512*8/c L1i: 32K/c L1d: 48K/c L2: 2M/c小核 L1i: 64K/c L1d: 32K/c L2: 4M/m L3: 36M |
| 频率 | CCD0: 最大 5.2 GHz CCD1: 最大 5.7 GHz |
CCD0: 最大 5.7 GHz CCD1: 最大 5.5 GHz |
最大 4.4 GHz | 大核: 最大 5.8 GHz 小核: 最大 4.3 GHz |
| 功耗(默认值) | 162W | 230W | 142W | 253W |
| 制程 | CCD: TSMC N5 IOD: TSMC N6 L3D: TSMC N7 |
CCD: TSMC N5 IOD: TSMC N6 |
CCD: TSMC N7 L3D: TSMC N7 IOD: GF 12nm |
Intel 10nm+++ |
| 面积 | CCD: 66.3 mm² IOD: 117.8 mm² L3D: 36 mm² |
CCD: 66.3 mm² IOD: 117.8 mm² |
CCD: 80.7 mm² IOD: 125 mm² L3D: 41 mm² |
257 mm² |
| 晶体管数量 | CCD: 6.57B*2 IOD: 3.37B L3D: 4.7B |
CCD: 6.57B*2 IOD: 3.37B |
CCD: 4.15B IOD: 2.09B L3D: 4.7B |
未公开 |
| 晶体管密度 (MTr/mm²) | CCD: 99 IOD: 29 L3D: 131 |
CCD: 99 IOD: 29 |
CCD: 51 IOD: 17 L3D: 115 |
未知 |
性能测试
定频测试
通过 CPPC 配置处理器的频率为 4GHz (实际频率约为 3.975 GHz)进行不同大小的访存延迟与单线程带宽的测试,并且计算每周期带宽、延迟周期数等数据进行比较,结果如下
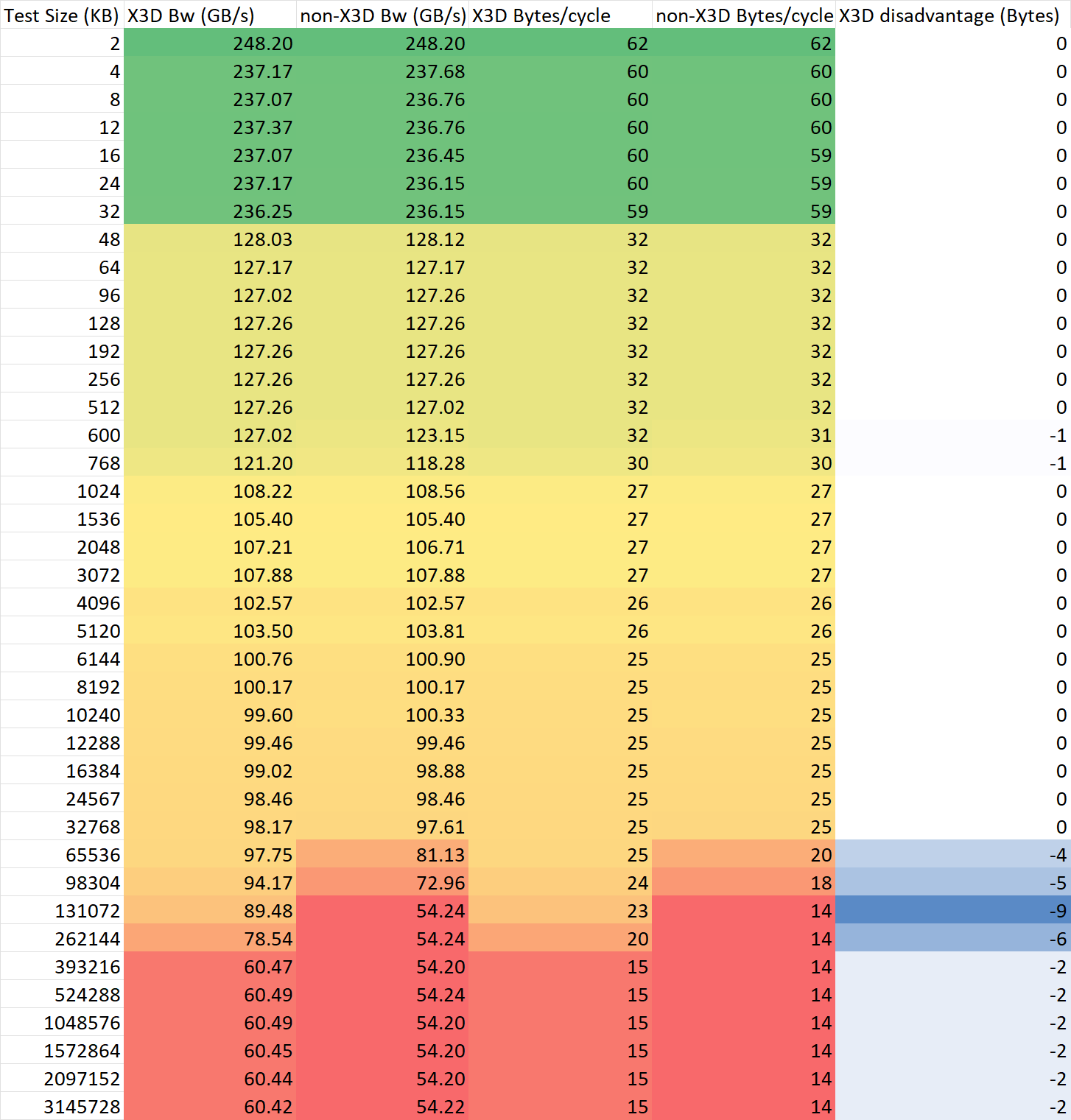
带宽测试
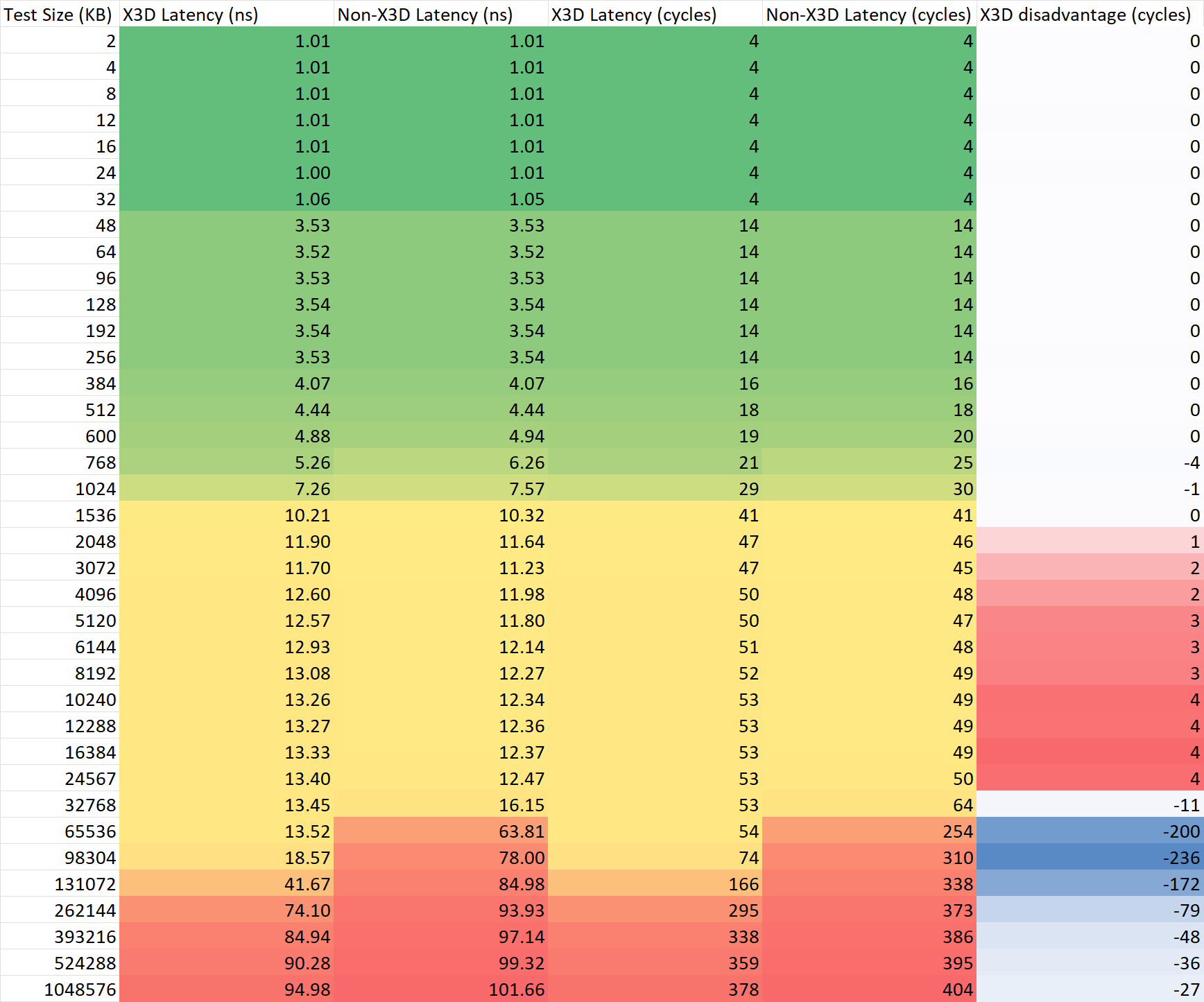
延迟测试
可以看出,在同样的频率下,Zen4 的 X3D CCD 相比普通 CCD 有以下这些特性:
- 保持了几乎相同的同频带宽,仅仅只是缓存加大;
- 延迟增加最大4个周期。
需要注意的是,Raphael 处理器的两个 CCD 读写内存的带宽和延迟有10%左右的差异,这个并非由 X3D 造成,而是由 cIOD 内部拓扑的差异导致。个人猜测是第二个 CCD 连接的 GMI 接口在逻辑拓扑上距离 IMC 更远,导致了这一现象。在普通的 7950X 上也可以复现这一测试结论。
默频测试
将处理器在默频下进行不同大小的访存带宽与延迟的测试,并直接比较最终成绩,结果如下
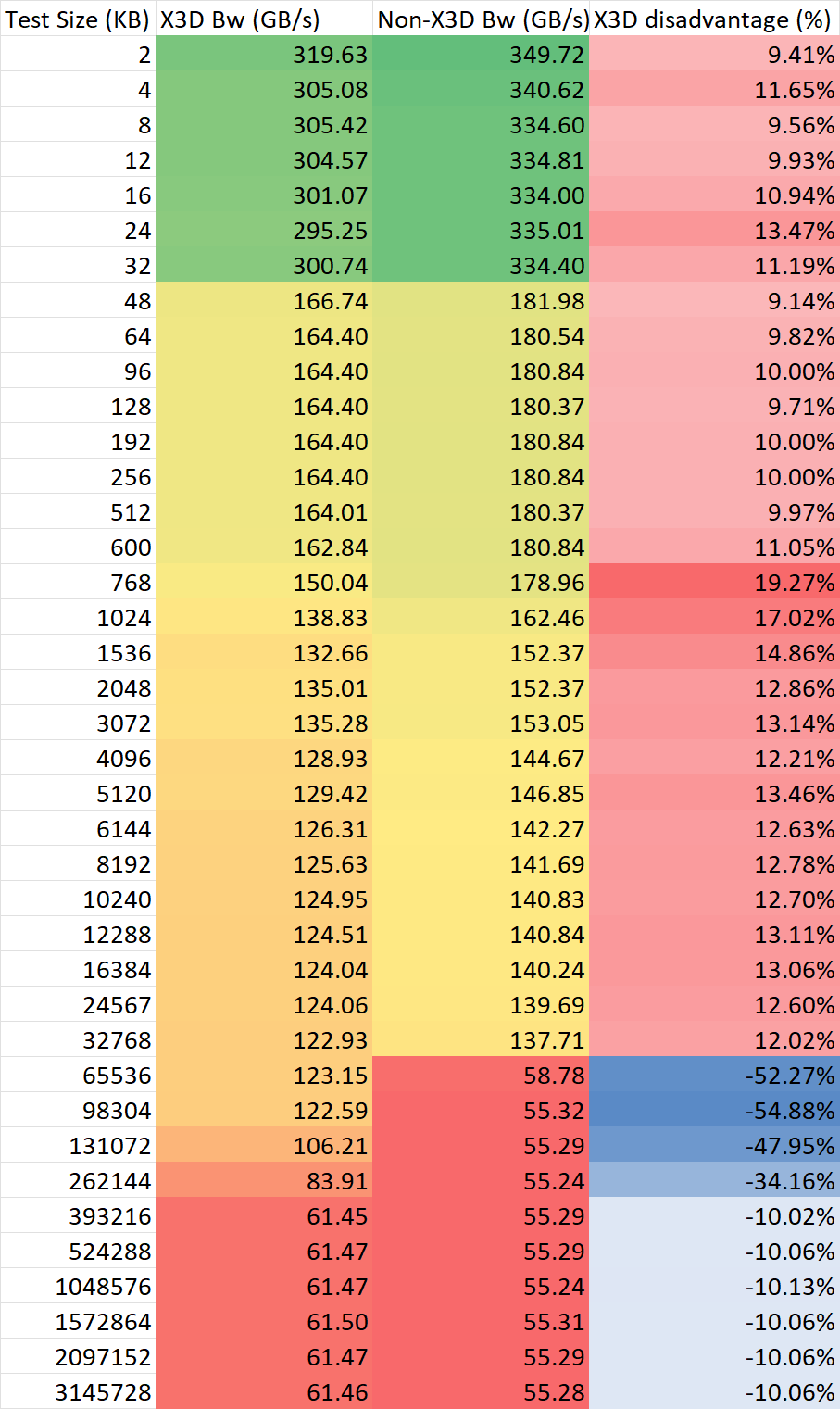
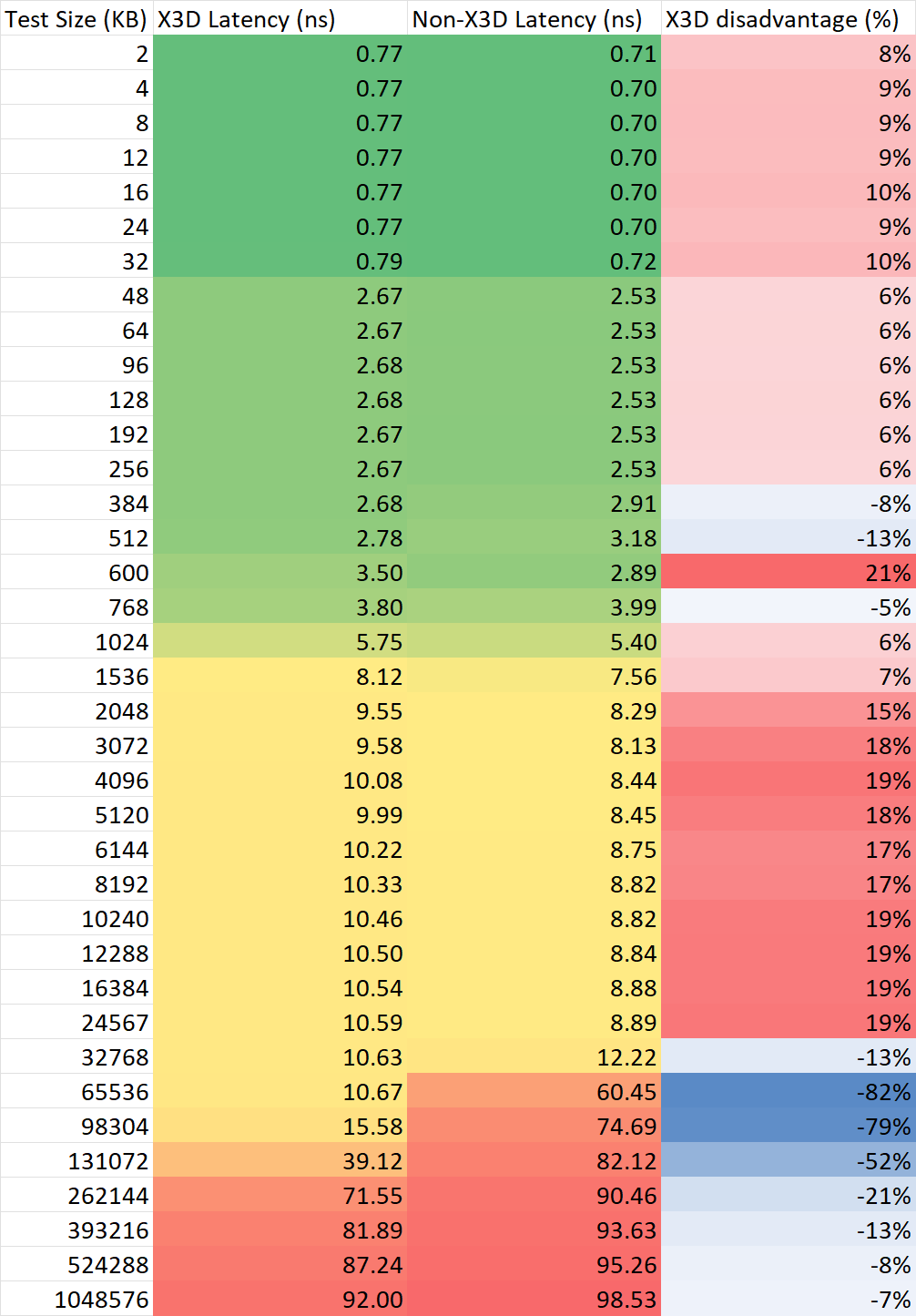
可以总结,运行于默频下的 Zen4 X3D CCD 相比普通 CCD 有以下这些特性:
- 由于频率劣势 (5.2 GHz vs 5.7 GHz),X3D CCD 在 32M 内的带宽相比普通 CCD 损失10%左右;
- 由于缓存延迟增加和频率劣势,X3D CCD 在 1-32M 内的延迟相比普通 CCD 的损失可达20%左右;
- 在 32-96M 内,X3D CCD 相比普通 CCD 无论是延迟还是带宽都有巨大的优势。
由此可见,在实际的应用里,X3D 缓存并非一定是最优解。在memory footprint较大的应用里以小幅度降低核心频率和小幅度增加缓存延迟的代价换取更高的命中率,才是使用 X3D 的目的。
应用性能
在 Debian sid 环境下使用 GCC 12.2 编译运行 SPECint2017 rate-1 测试,结果如下

不难看出,
- 测试结果与上代类似,X3D 对502/520/557子项的提升较大;
- 提升最为明显的520子项中,Zen3 X3D提升33%,Zen4 X3D 提升38%;
- 其它子项或多或少受到频率下降等因素的影响,X3D CCD 分数不敌高频 CCD 或者原版 7950X;
- 最终 7950X3D 的高频核心的总分相比大缓存核心高出大约3%。
更多相同环境下的 SPEC CPU 2017 int rate-1 测试结果可以参考SPEC CPU 2017测试的总结,已更新加入 7950X3D 的成绩。
游戏性能与分析
由于时间有限,本文仅就《原神》一款游戏在两种不同 CCD 上对两种不同画质选项进行测试。
《原神》是当前的一款热门游戏。由于城区场景复杂,对处理器访存性能的考验极高,非常适合作为 X3D 的性能测试场景。其画质选项“场景细节”决定了 draw distance / LOD 等参数,对 CPU 负载的影响最大,因此主要针对它进行调节测试。
测试环境
- 为方便数据采集与测试对比,使用 Linux 作为宿主机 OS,使用 QEMU/KVM 虚拟化运行游戏;
- 内存为 SK Hynix DDR5-5600B 2*32 GB 运行于 5200B JEDEC 频率,分配 16 GB 给测试用的 VM,使用 2M page;
- FCLK = 2000 MHz,UCLK = 1300 MHz;
- 将 6950 XT 显卡、USB控制器、NVMe 硬盘采用 PCIe 直通的方式穿透到 VM 内,以减少性能损失;
- 测试场景为上述视频(单独录制,非实际测试画面)内的跑图路线,每一组进行三次测试,取中位数;
- 分辨率为 1080p 并且开启 FSR2 0.6x,消除潜在的 GPU 瓶颈;
- 针对“场景细节:极高”和“场景细节:高”进行两组测试,其余所有画质选项全部手动调到最高;
- 使用 CapFrameX 工具抓取帧数数据进行分析。
测试结论
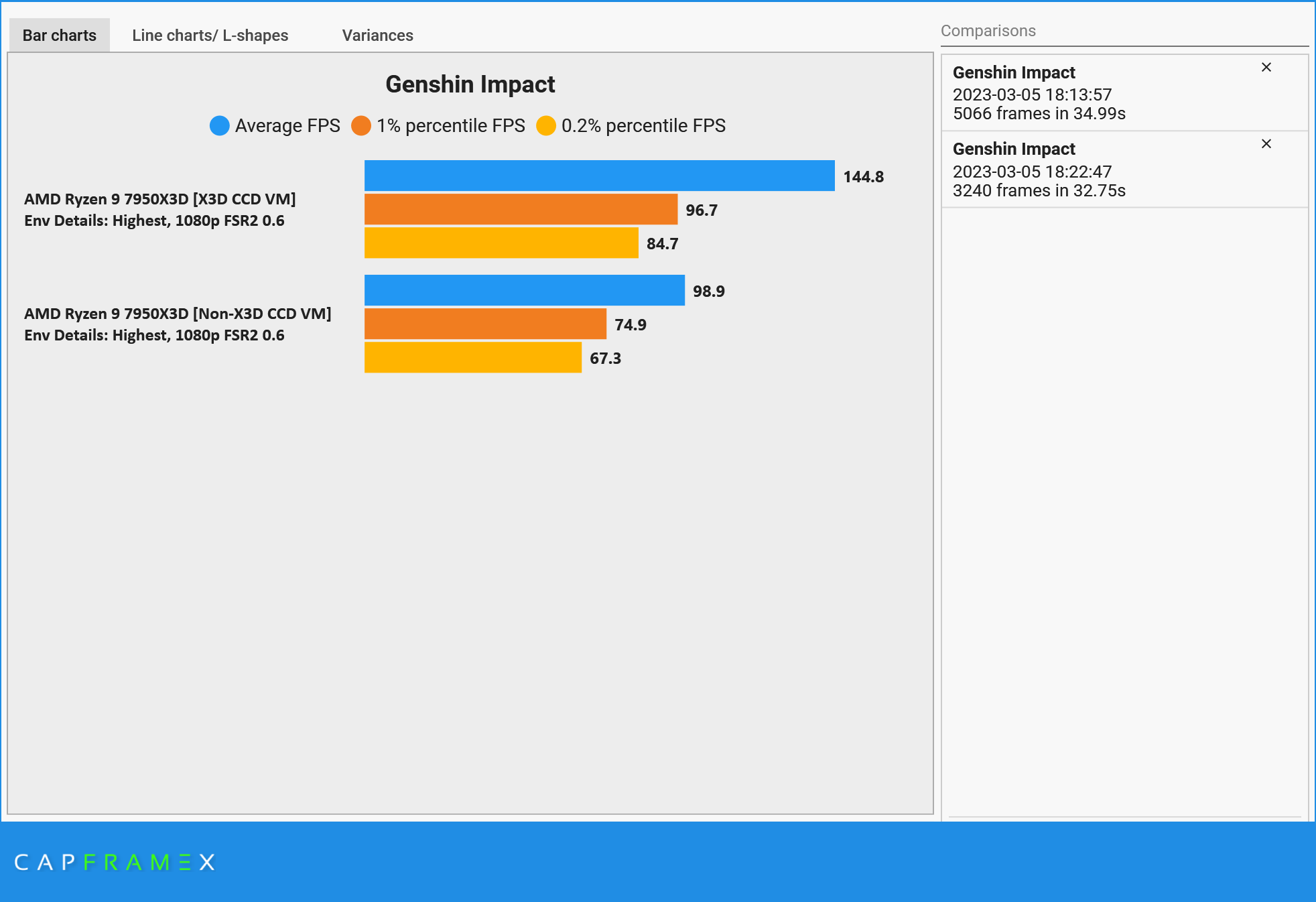
场景细节:极高
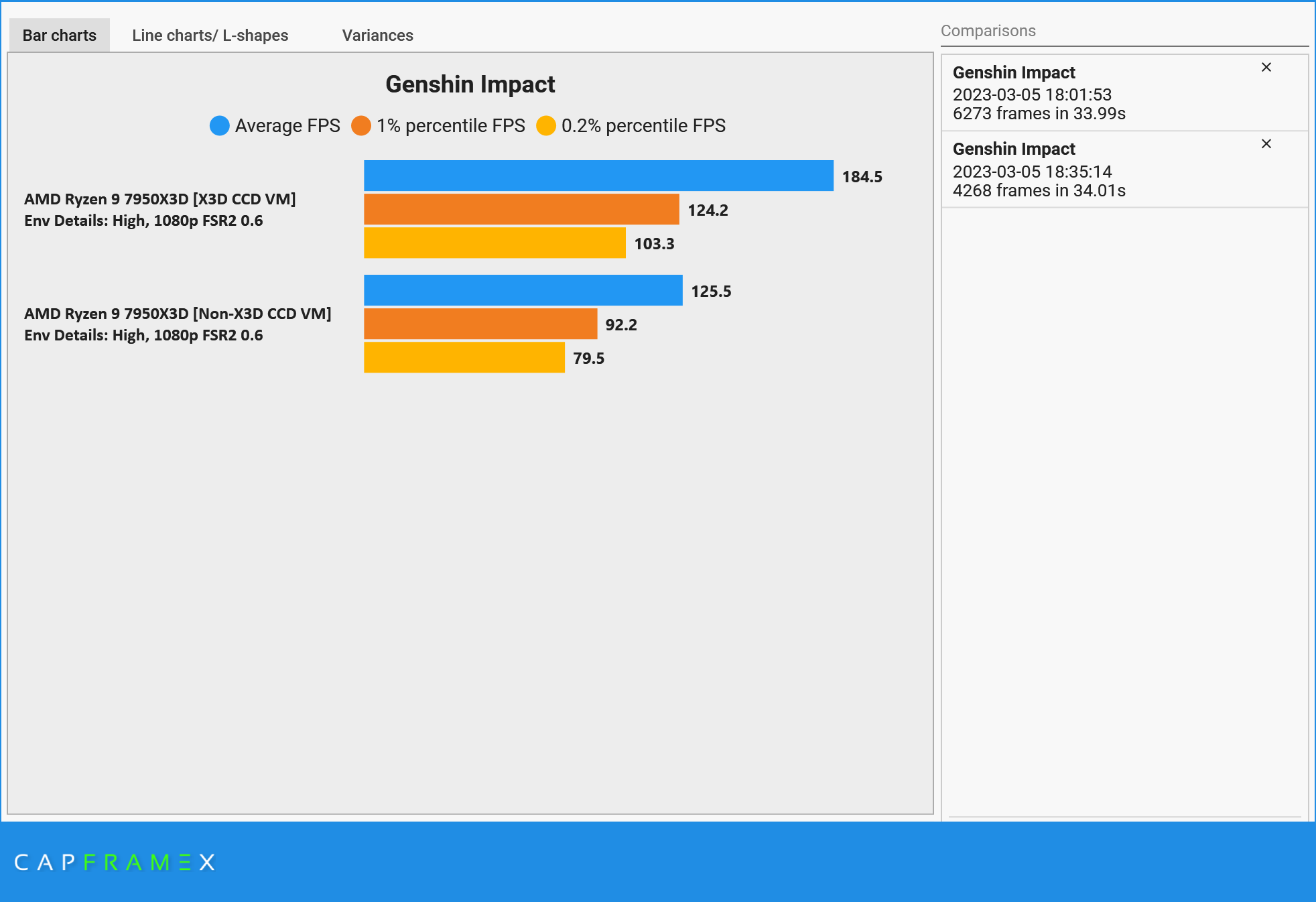
场景细节:高
在场景细节设置为极高/高的情况下
- 平均帧数提升46.4%/47.0%;
- 1% low帧数提升29.1%/34.7%;
- 0.2% low帧数提升25.9%/30.0%。
无论是在极高还是在高画质下,X3D 均可以做到大幅度提升游戏帧数,并且对平均帧、1% low、0.2% low均有效。
简单记录几个PMU计数器进行对比
| X3D – 细节极高 | 普通CCD – 细节极高 | X3D – 细节高 | 普通CCD – 细节高 | |
|---|---|---|---|---|
| ls_any_fills_from_sys.int_cache | 871,907,830 | 683,058,105 | 947,293,353 | 695,311,676 |
| ls_any_fills_from_sys.mem_io_local | 13,777,056 | 35,999,229 | 12,257,034 | 33,423,281 |
| L2+L3 填充命中率 | 98.4% | 95.0% | 98.7% | 95.4% |
| l3_cache_accesses | 21,050,015,677 | 15,339,265,770 | 21,469,525,460 | 14,929,755,404 |
| l3_misses | 4,376,715,756 | 7,611,123,387 | 3,412,183,889 | 6,888,899,822 |
| L3 缓存命中率 | 79.2% | 50.4% | 84.1% | 53.9% |
可以看出,在非常复杂的游戏场景中,超大的 L3 缓存确实能显著降低缓存失效概率,降低内存压力,提升游戏帧数。
总结
AMD Ryzen 9 7950X3D 处理器通过 3D V-Cache 技术,在少量牺牲延迟,保持高带宽的同时,将三级缓存容量提升为普通 Zen 4 处理器的三倍,从而在游戏性能方面取得了显著的优势。这种技术不仅提高了处理器的性能,也降低了功耗,为未来的CPU设计开辟了新的可能性。期待各大半导体厂商在未来能够继续推出更多采用 3D 堆叠技术的产品,为消费者带来更好的体验和价值。