大概是一年之前,我发了一条想法:想看DG2-512EU vs Navi33
当时我还没有玩到Arc A380,Arc旗舰卡还在对标3070;RDNA3还在PPT上秀+50%能耗比,并且在传闻中相比RDNA2拥有2.5倍的性能;Ada Lovelace也还有不少人在传>2x 3090性能。而我只是单纯好奇,同样是拥有4096个FP32 ALU的两个完全不同微架构的GPU,放在一起对比会是怎样的表现。
虽然到了年底这三个说法最后都成了笑话:Arc旗舰卡一路推迟到4090发布才发售,而且沦落到性能对标3060;RDNA3的频率与功耗表现严重不及预期;Ada Lovelace以1.6倍的实际游戏性能提升成为最接近传闻的那个。
但是好奇心还是在这里,自己挖的坑还是得填,该做的测试还是要做。本文从GPU规格、理论性能与GPGPU测试、3D游戏实测、光线追踪游戏测试、上采样测试等方面来对比大半年前发布的Arc A770 16G限量版与刚发布不久的Radeon RX 7600。同时部分测试会加入上一代的W6600、RX 6950 XT和同代旗舰RX 7900 XTX进行对比。
本文所有测试GPU、测试平台均为自费购买,无利益相关。
处理器规格
| A770 16G | RX 6600 (W6600) | RX 7600 | RX 7900 XTX | |
|---|---|---|---|---|
| Render Slice (Arc) Shader Engine / Array (Radeon) |
8 | Shader Engine: 2 Shader Array: 4 |
Shader Engine: 2 Shader Array: 4 |
Shader Engine: 6 Shader Array: 12 |
| Xe Core / Work Group Processor | 32 | 14 | 16 | 48 |
| Xe Vector Engine / SIMD 单元数量 |
512 | 56 | 64 | 192 |
| SIMD 宽度 | 8 | 32 | 32 或 64 (部分指令) | 32 或 64 (部分指令) |
| Wavefront 宽度 | wave8 或 wave16 | wave32 或 wave64 | wave32 或 wave64 | wave32 或 wave64 |
| FP32 ALU数量 | 4096 | 1792 | 4096 | 12288 |
| 每周期像素填充 | 128 | 64 | 64 | 192 |
| 典型频率 | 2400 MHz | 2044 MHz | 2250 MHz | 2269 MHz |
| 向量寄存器 | 16 MB (32 KB / XVE) |
8 MB (128 KB / SIMD) |
8 MB (128 KB / SIMD) |
36 MB (192 KB / SIMD) |
| 局部缓存 | Texture cache: 64 KB per Xe Core L1 & SLM: 192 KB per Xe Core |
LDS: 128 KB per WGP L0: 32 KB per WGP L1: 128 KB per SA |
LDS: 128 KB per WGP L0: 64 KB per WGP L1: 256 KB per SA |
LDS: 128 KB per WGP
L0: 64 KB per WGP |
| 全局缓存 | L2: 16 MB | L2: 2 MB L3/MALL: 32 MB |
L2: 2 MB L3/MALL: 32 MB |
L2: 6 MB L3/MALL: 96 MB |
| 显存位宽 | 256 bit | 128 bit | 128 bit | 384 bit |
| 显存速率 | 17.5 Gbps | 14 Gbps | 18 Gbps | 20 Gbps |
| 显存带宽 | 560 GB/s | 224 GB/s | 288 GB/s | 960 GB/s |
| 制造工艺 | TSMC N6 | TSMC N7 | TSMC N6 | TSMC N5 + N6 |
| 核心面积 (mm²) | 406 | 237 | 204 | 529 (304 + 37.5*6) |
| 晶体管数量 (亿) | 217 | 111 | 133 | 577 (454 + 20.5*6) |
| 密度 (MTr/mm²) | 53.4 | 46.7 | 65.2 | 150 / 55 |
| 板级功耗 (W) | 225 | 132 | 165 | 355 |
两家GPU针对不同的结构有不同的terminology,并且设计上有一些区别。但是从中我们可以找出一部分相对应的概念:
- Arc的Render Slice与Radeon的Shader Engine、Shader Array是同一层级的概念。Render Slice与Shader Array在数量上具备可比性;
- Arc的Xe Core与Radeon的Work Group Processor是同一层级的概念,数量上也具备可比性。其特征是包含数个共享wavefront调度的SIMD单元,并且共享一个低延迟的本地存储,Arc称之为SLM,Radeon则为LDS;
- Radeon还有“Compute Unit”这一级,然而实际上这一级更多的是为了兼容GCN,在技术上满足某些需求(比如游戏主机向下兼容)以及市场宣传上便于操作。
- Arc的Xe Vector Engine (XVE,旧称EU,例如著名的96EU牙膏核显)与Radeon的SIMD相对应。虽然是同一层级的概念,但是由于Arc的向量单元粒度远比Radeon更细,数量上并不适合直接比较。Radeon也从未将这一层级拿出来作为产品参数使用。
可以看出,同样是4096 FP32 ALU的两个GPU,实际规格却是天差地别。
- Arc的SIMD更窄,意味着执行分叉代码时更高的执行效率(例如光线追踪),但也意味着需要多达4倍/8倍的执行控制单元才能获得相同的FP32吞吐,带来更大的面积代价。
- RDNA3相比RDNA2将每一个SIMD单元的FP32 ALU数量翻倍,但是支持的wavefront宽度不变,依然是wave32与wave64两种。
- wave32模式则需要将两个ALU操作打包到一条指令里执行。RDNA3的ISA设计在这方面的局限性较大。
- wave64模式可以采用单周期执行或轮流发射的方式实现利用额外的ALU。官方PPT称其是单周期执行wave64。
- RX 7600除去FP32 ALU数量以及L0/L1缓存之外,实际整体规格更接近上一代的6600家族的平替(挤牙膏)。尤其是向量寄存器相比RDNA3旗舰卡砍掉了三分之一的规模,与RDNA2一致。
- 无论是从面积、晶体管数量、显存还是从图形管线等方面来看,A770都更应该看作是7600的两倍规模。A770更像是对标2080Ti、3070Ti、RX 6800等GPU,而非真正对标7600这个级别的显卡。
测试环境
Arc A770 16G、RX 7600、W6600以及RX 6950 XT的测试在我的测试专用机上进行
- CPU:i9-13900K
- 内存:64GB DDR5-5600B JEDEC时序
- Arc显卡使用驱动版本101.4335 beta
- Radeon显卡使用驱动版本23.5.1
- 所有测试环境均屏蔽核显,以防止干扰
RX 7900 XTX的拆解过于麻烦,因此测试在我的7950X3D日用PC上进行,仅供粗略参考。
理论性能
首先对比这几个GPU的理论性能,以及使用一些简单的GPGPU程序对其进行验证。
RDNA2与RDNA3支持wave32与wave64两种执行模式,意味着可以选择wavefront里包含32个还是64个work item。同理,Arc A770也有wave8与wave16两种模式。
RDNA3使用当前的驱动运行OpenCL GPGPU测试时默认会使用wave32执行,并且可以通过环境变量GPU_ENABLE_WAVE32_MODE进行控制。由于部分测试里两种模式的性能差异较大,本文会在部分测试里将两种模式的测试结论都进行列出。
需要注意的是,对于Direct3D/Vulkan/OpenGL等API,当前驱动会将大部分shader以wave64模式运行(除去一些光线追踪shader会运行在wave32),wave64测试对游戏的参考价值更大。
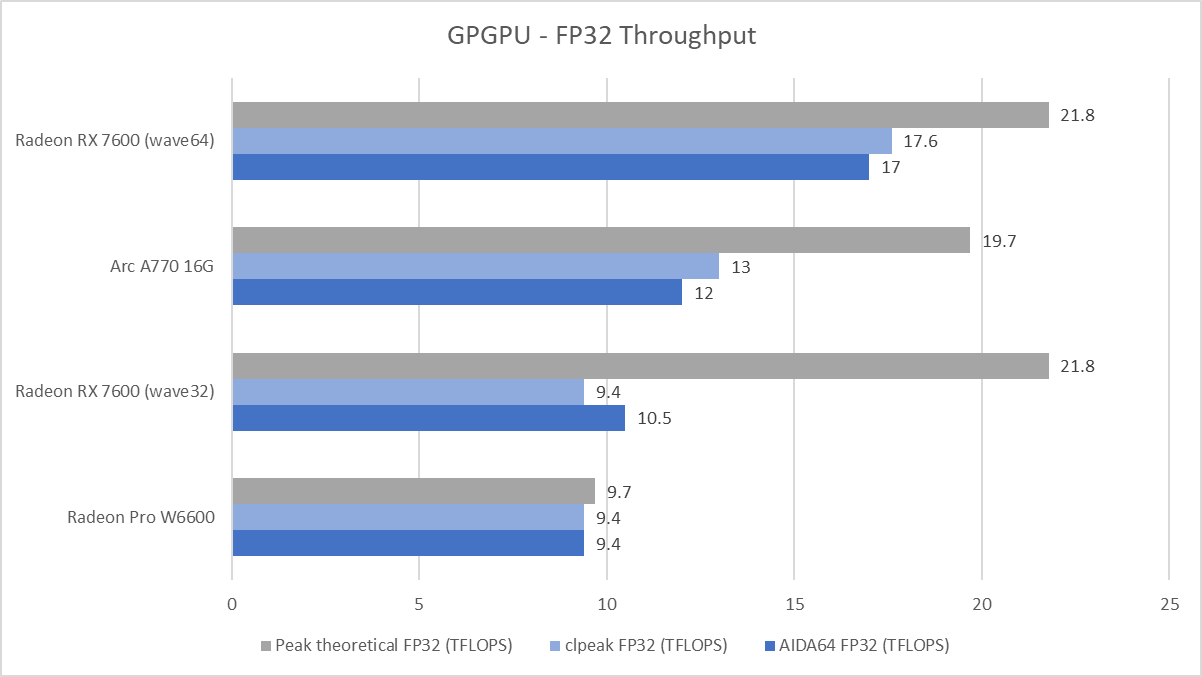
家用游戏主机圈子最喜欢的TFLOPS战争,人均TFBoy
使用常用商业软件AIDA64 GPGPU与开源测试软件clpeak分别进行测试。可以发现Arc A770大约能跑出12-13 TFLOPS左右的性能。RX 7600在wave64模式下可以跑出17 TFLOPS,但在wave32模式下只能跑出9-10 TFLOPS左右。这意味着在这两个OpenCL wave32测试里,RDNA3的FP32双发射完全失效。
分析clpeak的源码,发现clpeak测试的 x = mad(y, x, y); y = mad(x, y, x); 全部被编译成了VOP3的v_fma_f32指令,接受3个source operand和一个destination operand。
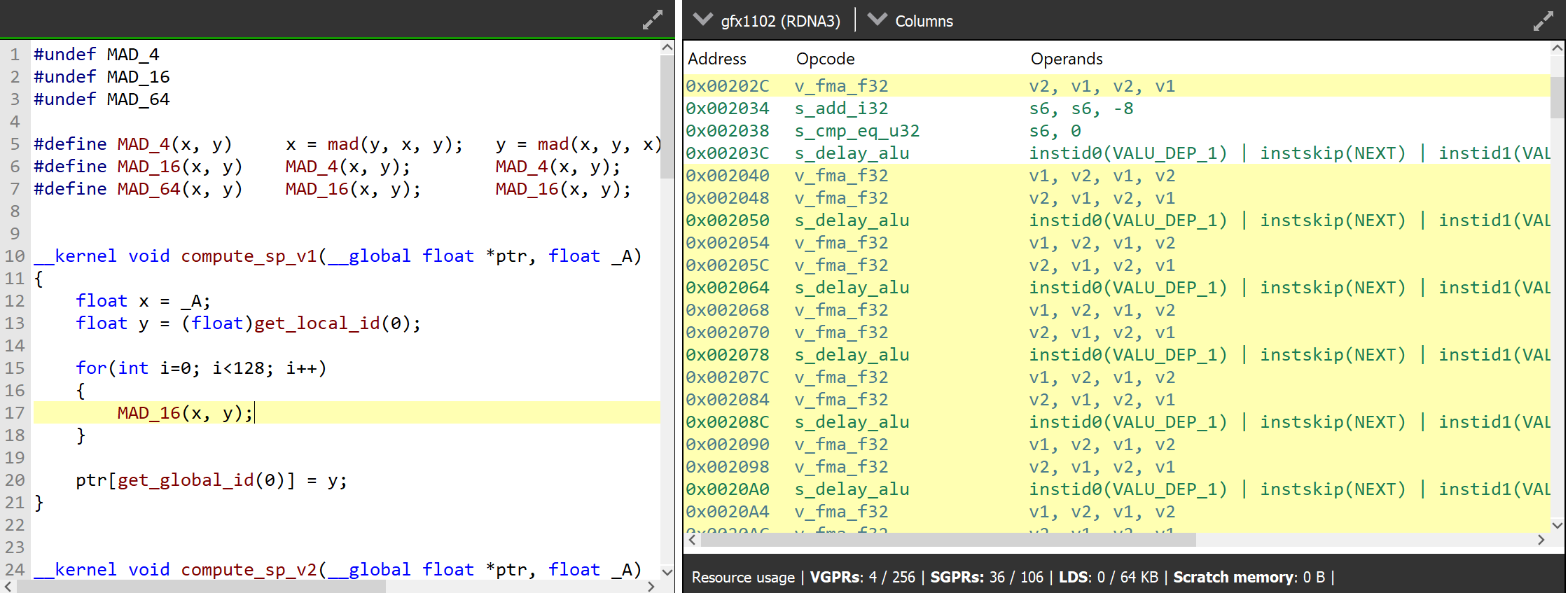
参考RDNA3 ISA文档可以发现,wave32下FP32双发射采用VOPD编码实现,其不仅对寄存器的使用有严格的限制,更大的麻烦是没有任何VOP3指令有对应的版本,也就是不能使用3个source operand的向量FMA指令。
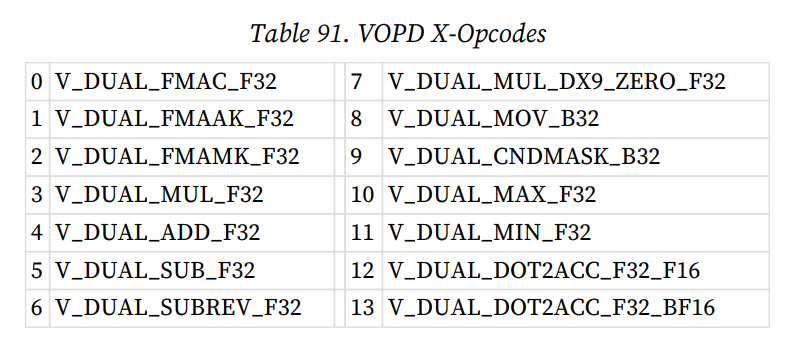
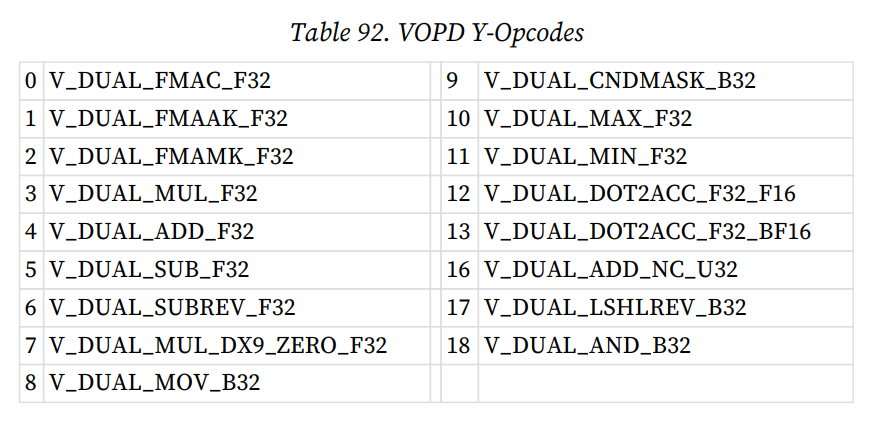
如果想要在wave32模式下跑出RDNA3的最大FP32吞吐,只能将代码修改成VOPD支持的指令(也就是两个源操作数的VOP2),例如在vector float2测试中将其改为FMAC,即可看到成功生成了双发射FP32的VOPD指令,同一指令内打包操作float2的两个element。
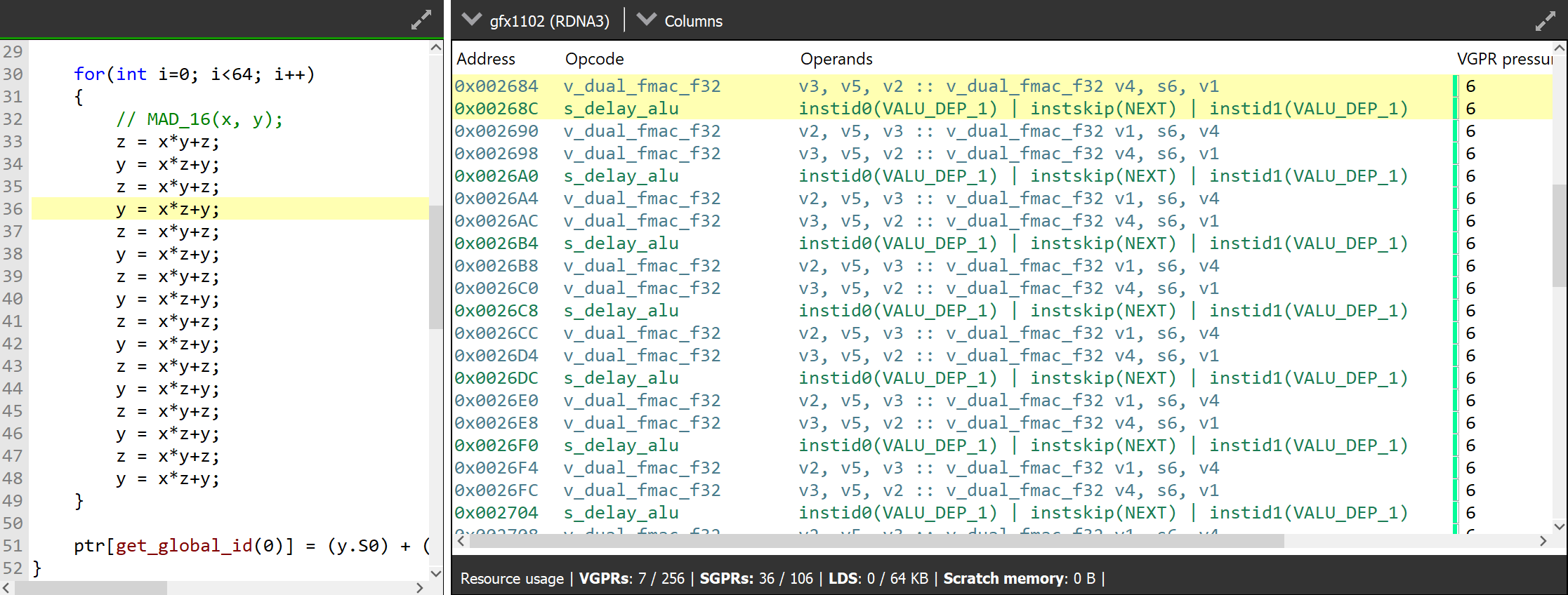
从上述测试结果不难看出,RX 7600运行在wave32模式(例如默认配置下的OpenCL/ROCm HIP),双发射在很多场景下无法使用,但其单发射FP32的执行效率符合预期;运行在wave64模式(例如游戏)时,双发射FP32是实际可用的,但效率并不是特别高,只能跑出理论性能的80%不到水平。Arc A770则以66%的效率垫底。
显存带宽
使用clpeak测试显存带宽并且与理论数值进行对比
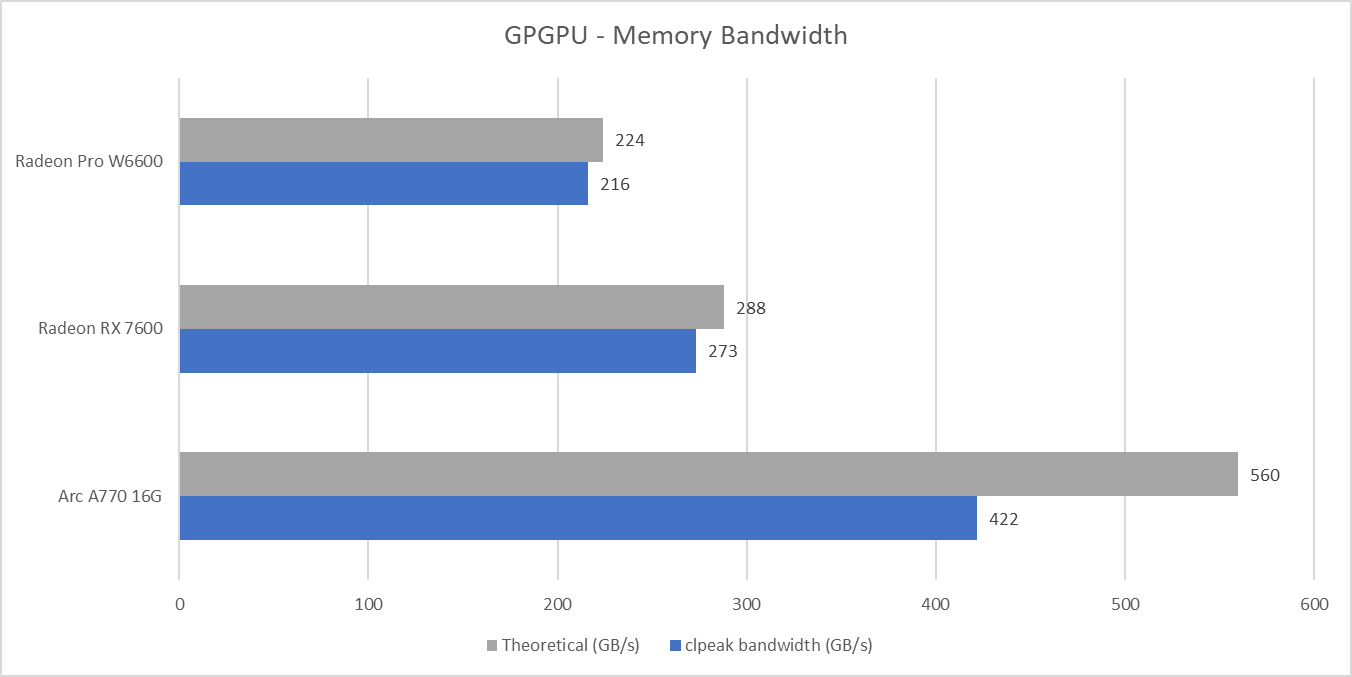
两张Radeon显卡的实测数据比较接近理论带宽数值(≥95%),但是A770则只能跑出75%的带宽,差距较大。即便如此,Arc A770的显存带宽依然比RX 7600高出50%以上。
Blender渲染测试
Blender 3.6 beta版分别对Arc和Radeon加入了Embree硬件光线追踪加速以及HIP-RT,意味着在这个版本中,各家GPU的硬件光线追踪单元都有了用武之地。使用GPU渲染4K分辨率的Barcelona Pavilion,分别开启、禁用硬件光线追踪加速进行测试
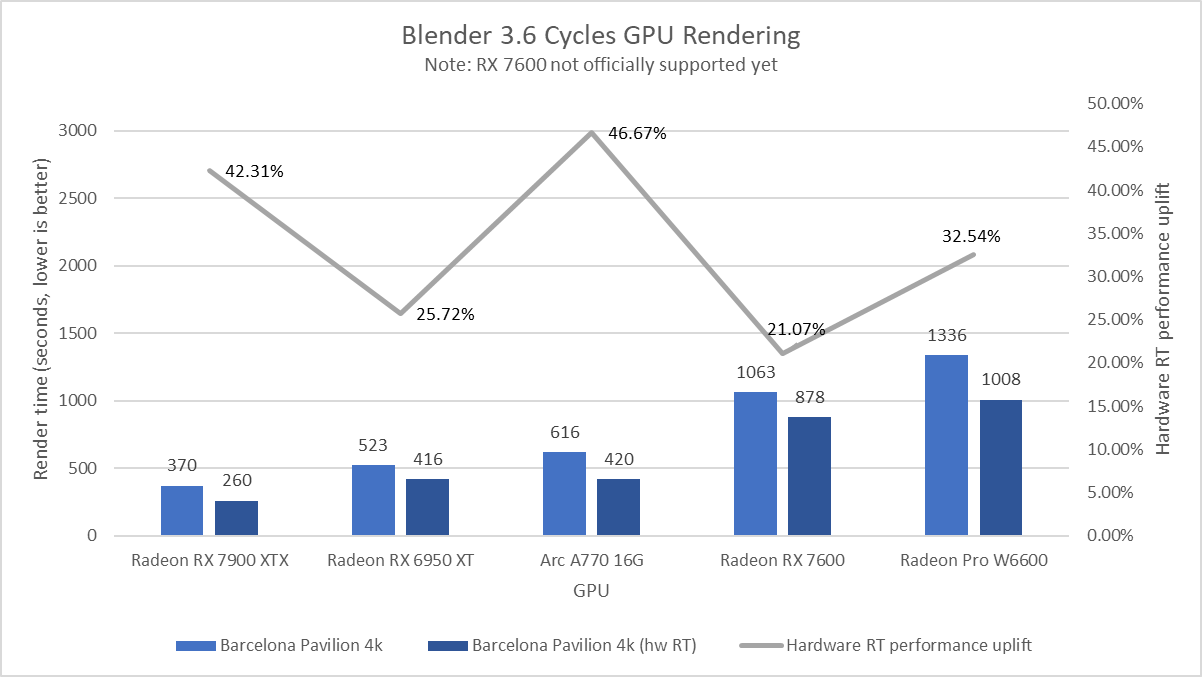
图中浅蓝色的条形图是关闭硬件光线追踪的渲染时间,深蓝色的条形图是打开硬件光线追踪的渲染时间,越低越好。灰色的折线图是不同GPU打开硬件光线追踪后的性能提升幅度,越高意味着硬件光线追踪对Blender渲染性能提升的帮助越大。
可以发现,Arc A770的硬件光线追踪性能提升幅度是图中所有GPU里最高的,其渲染性能已经非常接近芯片面积更大的RX 6950 XT,也超过了RX 7600的两倍。7900 XTX在这项测试中也获得了较好的成绩,硬件光线追踪的性能提升幅度达到了42%,接近Arc的提升幅度,并且绝对性能也对得起规模。但RDNA2显卡以及RX 7600的提升就不尽人意了,只有20%-30%左右。
需要注意的是,RX 7600目前最新版驱动暂时没有HIP-RT的正式支持。我将23.5.2驱动里的HIP-RT复制到RX 7600的环境里可以成功完成渲染,但加速效果远不如旗舰卡那么明显。目前暂不清楚是因为RX 7600砍掉向量寄存器导致光线追踪效率下降,还是因为单纯的HIP-RT库没有针对RX 7600优化好,有待后续驱动正式支持7600运行HIP-RT后重新进行测试。
Arc A770启用硬件光线追踪渲染后,blender会在渲染完成的一瞬间崩溃,需要等待后续版本修复bug。
除此之外,RTX 4090使用OptiX完成此项测试仅需要不到80秒,Radeon/Arc GPU目前在离线3D渲染的软件生态上已经有所作为,但还需要在光线追踪硬件上继续努力追赶NVIDIA。
3D游戏实测
选取一些比较有代表性的游戏进行简单测试,其中除了3DMark Fire Strike和原神之外,其余游戏都是基于DX12或者Vulkan API。
3DMark测试
很多人把3DMark称作“理论跑分”,但实际上相比一般的GPGPU理论测试而言,3DMark是非常接近真实游戏的测试,完全可以作为一些重特效、极高画面、高分辨率的3A游戏去看待。每个3DMark版本都代表了一个时代最高画质的游戏的表现。
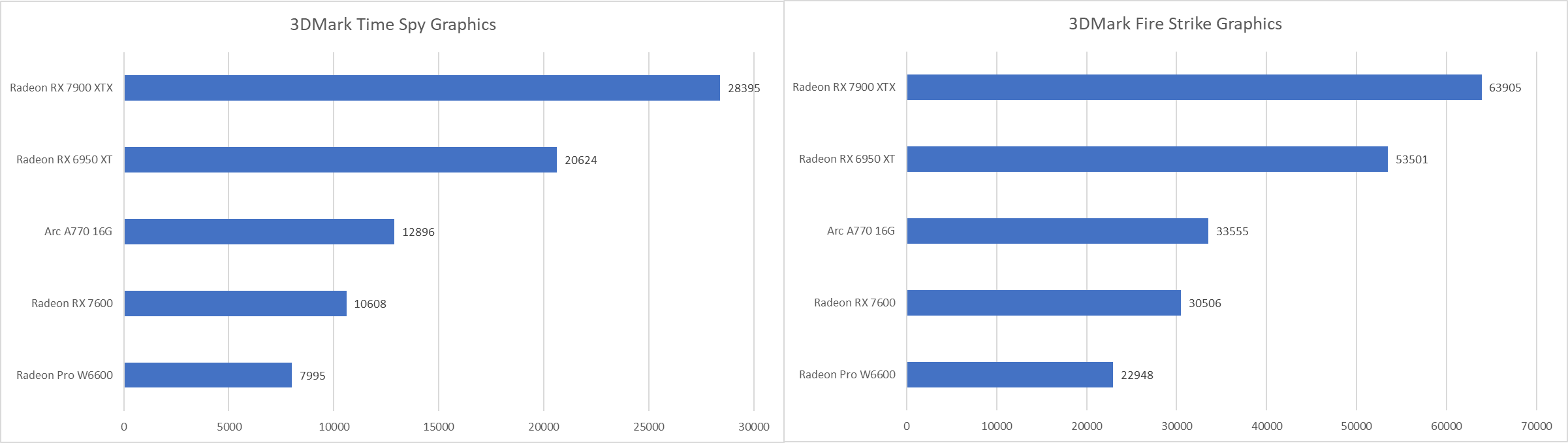
A770在1440p 3DMark Time Spy的图形测试中相比RX 7600有超过20%的领先,而在1080p Fire Strike图形测试中领先幅度下降到10%。尽管Arc被一些网友称作高分低能,但这个测试结论事实上确实可以反映到后面一部分画质极高的实际游戏测试里。
Cyberpunk 2077
《赛博朋克2077》是一个显卡杀手级游戏,并且在一次又一次的更新中加入了越来越多的新图形技术,享有“真正的3DMark”等称号,也是各大显卡厂商最喜欢放在PPT上展现图形性能进步的游戏之一。
使用其内置跑分进行测试,所有预设均手动关闭画面缩放(XeSS/FSR2)功能。
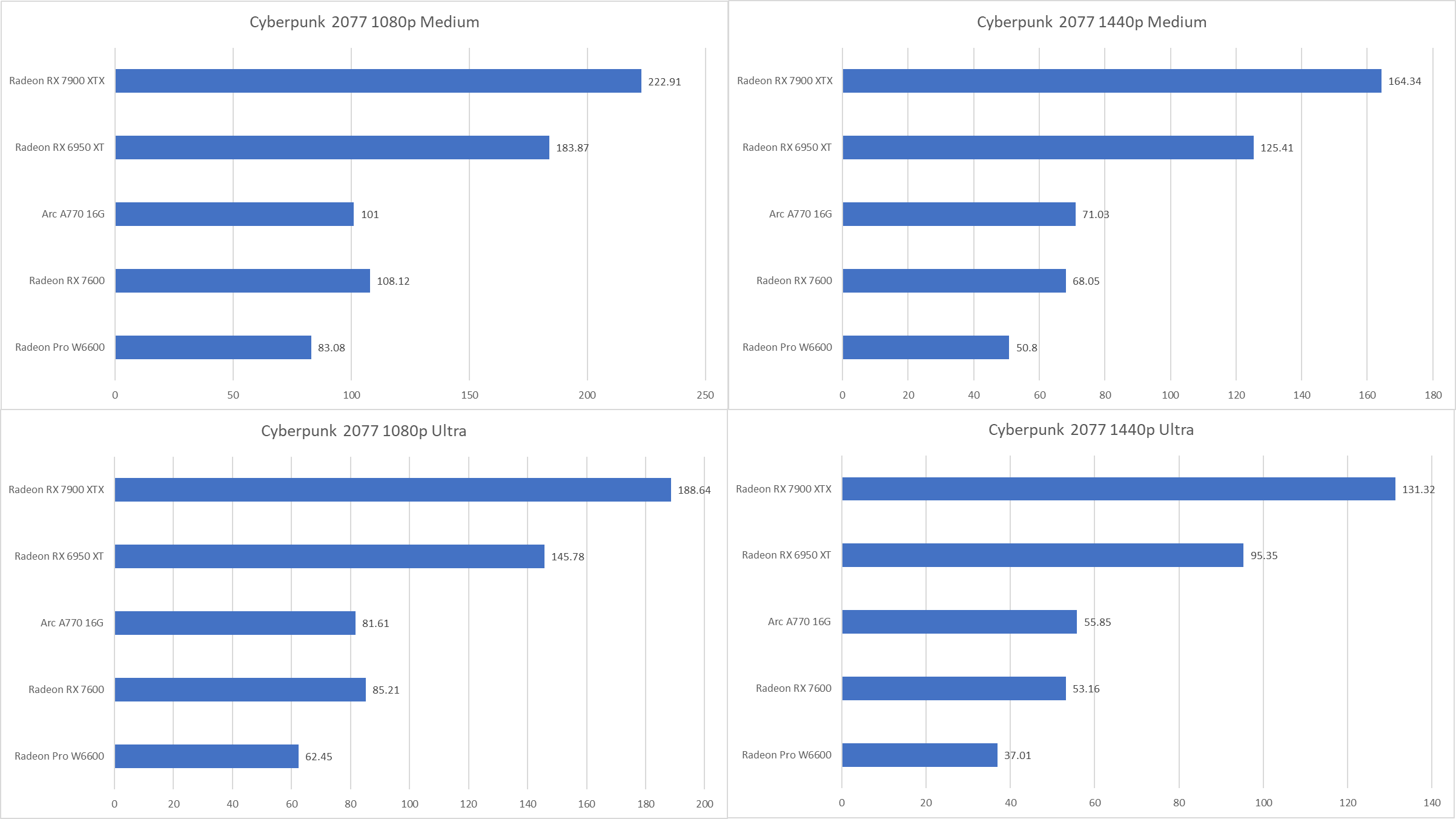
可以看到,在1080p下RX 7600无论是medium画质还是ultra画质都要略胜A770一筹,但到了1440p下被A770小幅度反超。
Call of Duty 19
《使命召唤 现代战争2》是目前热门的多人FPS游戏,也是Steam日活前10的游戏里最吃GPU的游戏。它虽然不是Radeon赞助的游戏,但是在Radeon GPU上的表现却是谜之好,尤其喜欢RDNA3。
本次测试中,6950 XT与7900 XTX使用了不同的CPU,并且在低分辨率下均撞到严重的CPU瓶颈,因此这两者的性能在低分辨率、低画质下不具备参考意义。
使用游戏的内置跑分进行测试。
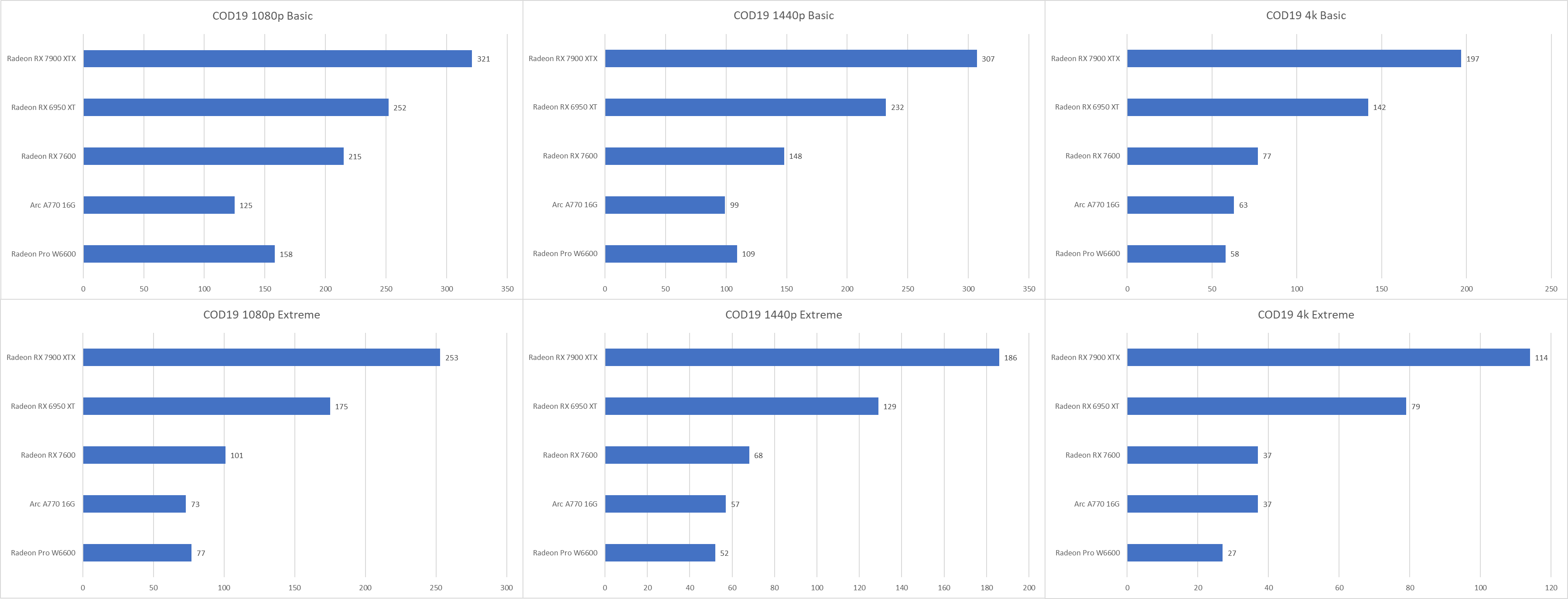
可以看到,无论是何种画质、何种分辨率,RX 7600的表现均在Arc A770之上。但是,分辨率越高、画质越高的情况下RX 7600的优势越小,在4k extreme画质下两者帧数接近。
作为一个电竞游戏,A770无论分辨率、画质降到多低都很难实现较高帧率,不适合重度COD多人玩家。而RX 7600则正好相反,在Basic画质下哪怕是原生1440p甚至4K FSR2都能获得相当好的高刷新率体验。
但如果只是想高画质、高分辨率体验单人任务,A770在较高画质下的表现也还算差强人意。
Forza Horizon 5
《极限竞速地平线5》是一款非常考验GPU的开放世界赛车游戏,其生成大量零碎draw call对GPU的任务分派系统产生非常极端的压力。使用游戏内置跑分搭配不同的画质预设进行测试。
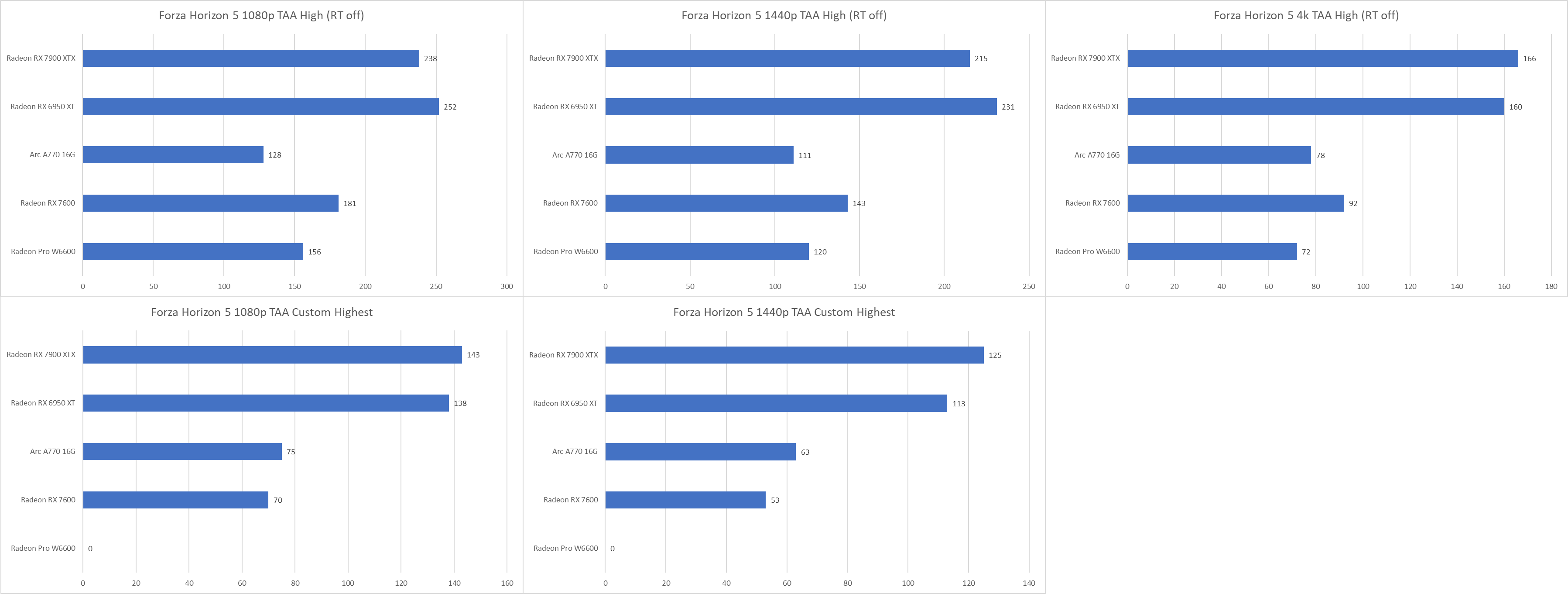
早在Ampere/RDNA2的时代,RDNA2就因为同级GPU有更高的频率搭配更少的前端规模而产生优势;而如今Ada Lovelace/RDNA3的形势完全逆转,甚至出现低分辨率、低画质下6950 XT反超7900 XTX的现象。但相似规模的RX 6600、RX 7600却是正常的代际性能提升,说明这个游戏并非对RDNA3不友好。
Arc A770在这个游戏里的表现也是如此。低分辨率、较低画质下的相对表现远不如竞品,但是随着分辨率、画质的提升逐渐反超,说明Arc可能存在潜在的任务分派、GPU利用率问题。
高分辨率下A770反超7600与A770的16G大显存也有一定的关系,使用8G版本的A770或者A750可能并不能复现这一优势。8G显存无法支持最高画质哪怕是1080p运行游戏(游戏显示占用9GB+)。其中W6600的性能损失、卡顿感极其严重,所以不记录数据。显存不足对7600可能也有一定的影响,但帧数稳定性依然可以接受,仅在游戏跑分途中报告过一次显存不足,可以作为有限的性能参考。
总的来说,Arc A770在这个游戏里充分体现了最高画质下全分辨率的性能优势,但调低画质带来的帧数提升则非常有限。
Red Dead Redemption 2
《荒野大镖客2》是光线追踪游戏普及之前显卡压力最大的游戏之一,手动拉满最高画质之后非常适合用于检验GPU对复杂着色器特效的处理能力。
使用游戏的内置跑分进行测试。

可以看到Arc在所有分辨率下都有与3DMark相称的表现,相比RX 7600的优势非常明显。
原神3.7 阿如村跑图
你说的对,但是《原神》是由米哈游自主研发的一款全新开放世界冒险游戏。
《原神》是本次测试中除了3DMark外唯一的Direct3D 11游戏。
阿如村的GPU压力较大,适合作为GPU压力测试点使用。将画质调节为手动全最高,抗锯齿使用FSR 2,关闭动态模糊进行测试,并记录平均帧数。
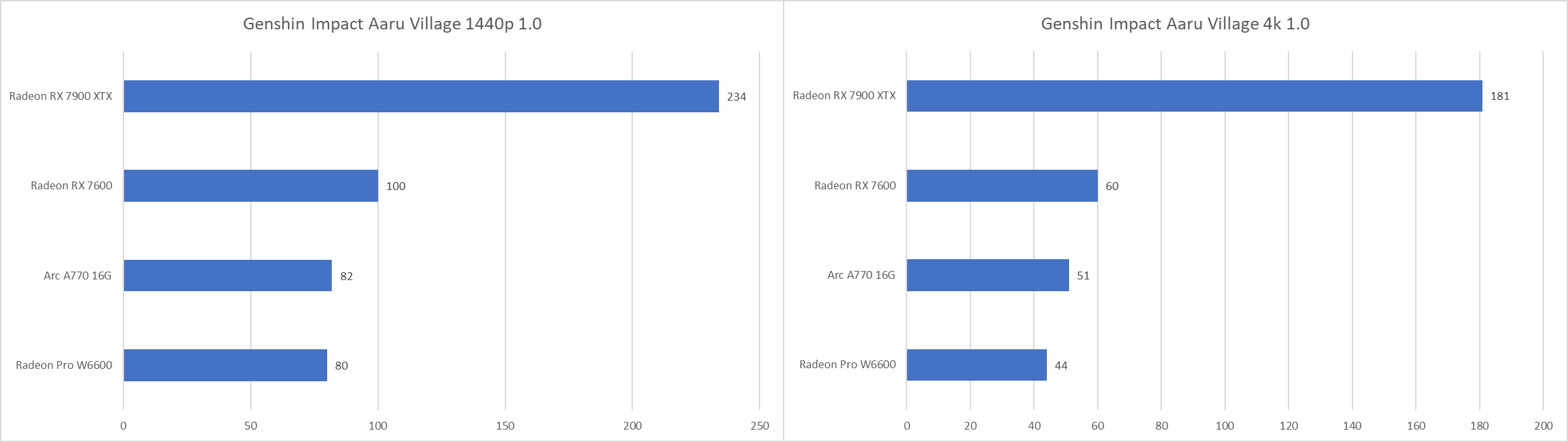
可以看到在原神里,RX 7600相比A770拥有不小的优势。1080p、1440p下无论是Arc A770还是RX 7600都能满足锁60fps的游戏体验,但是RX 7600能进一步稳住4k 60fps,而Arc A770在4k下的测试成绩只有51fps。
光线追踪游戏实测
Arc大获全胜
光线追踪游戏对于这个价位的显卡负载非常大,所以本文主要专注测试1080p下的表现,包含少量1440p测试结果。除此之外,DXR早期有大量游戏为了标榜自己“支持光线追踪”加入了一些不痛不痒的光线追踪特效(例如一些非常轻量的、感知不强的光线追踪阴影)。这些测试意义不大,不在本文的覆盖范围内。
3DMark 光线追踪测试
分别测试Port Royal、DXR Feature Test (修改参数为20 Samples) 以及最新的Speed Way场景。

其中Port Royal、Speed Way类似光栅化管线为主的基础上增加光线追踪特效的混合渲染游戏场景,而DXR Feature Test是一个纯路径追踪的偏理论性质的测试。前者可以拟合大部分有一定光线追踪特效的游戏的性能,后者适合测试光线追踪理论性能,以及反映类似2077 RT OD这种路径追踪游戏的性能。
可以看出,A770 16G在混合渲染的两个场景里性能分别高出RX 7600 30%和24%,而在DXR路径追踪测试中则高出57%。
Cyberpunk 2077
针对2077的画质测试主要分为4档:RT Medium预设,RT Ultra预设,RT Ultra预设+Psycho光照,以及最近新增的最有挑战的RT Overdrive模式。所有测试均为关闭XeSS/FSR2并在1080p下运行内置跑分。
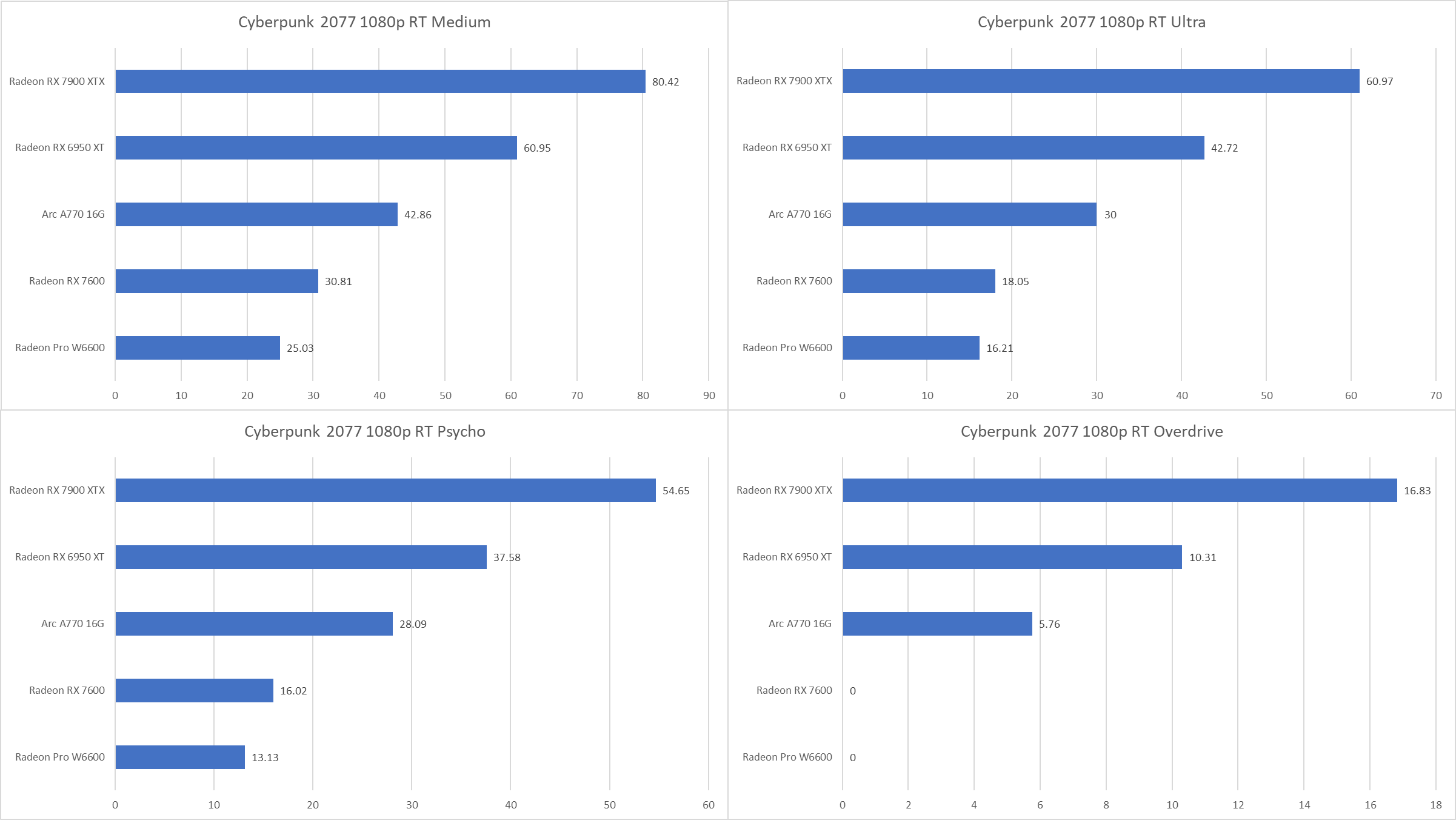
可以看出Arc A770对它的两位竞争对手表现出了碾压之势,在1080p Medium下领先接近40%,在1080p Ultra预设下领先66%。并且1080p光线追踪的帧数并非不可接受,Medium画质下A770搭配XeSS以及一个VRR/FreeSync屏幕完全可以获得较为优质的体验。
8G显存的显卡由于显存不足无法完成原生1080p分辨率的RT Overdrive的测试,所以RX 7600与W6600两名选手遗憾退场。不过Arc A770在这个测试下的表现也不够理想,仅有6950 XT的56%,相对性能不及其它光线追踪测试。
Metro Exodus Enhanced Edition
《地铁·离去 增强版》是首个强制要求DXR才能启动的游戏。它在《地铁·离去》原版的基础上基于DXR大幅度增强了光照效果,将场景光影特效绘制得栩栩如生,是我认为最值得测试的DXR游戏之一。同时,它提供的多档预设也使得哪怕是最低配的支持光线追踪的主流显卡在1080p下可以有一个合格的体验。
使用内置的跑分功能测试1080p下High、Extreme以及1440p Extreme的性能。

Arc A770再次毫不留情地吊打两位竞争对手。所有GPU在1080p High下均有可接受的性能,但Arc A770可以实现100fps的高刷体验。而即便是在1440p Extreme画质下,Arc A770也可以维持VRR/FreeSync屏幕上可以接受的>40fps帧数。
上采样测试
PS4 Pro于2016年将棋盘渲染推向主流市场,在那之后3D游戏的上采样逐渐发展到各类基于历史帧信息的技术,例如虚幻引擎的TAA-U、TSR,动视IW引擎的SMAA TU2x,以及PC玩家最熟悉的DLSS 2.x、FSR 2.x以及XeSS等技术。
表面上看,高质量的上采样可以大幅度提升主流价位显卡以及老显卡的使用体验,然而事实上这类技术在多个层级存在“旱的旱死涝的涝死”的问题
- 分辨率越高,画面效果越好
- 帧数越高,画面效果越好
- 显卡架构越新、越高端,开销越小
因此一直以来上采样技术反而是经常出现高端显卡提升大,低端显卡提升小的现象,而高端显卡又很少真的需要上采样技术。所以有必要测试不同微架构显卡运行上采样代码的开销,判断同一级别的显卡,谁运行上采样的开销更低。
PC端三家各有自己的上采样技术,其中DLSS是NVIDIA专属,FSR2是最通用且广泛适配的技术,XeSS虽然理论上也可以通用但是目前支持的游戏较少。考虑到Arc与Radeon的实际情况,这里直接对比测试FSR2 demo。

分别记录1440p、4k两种分辨率下运行质量档的性能开销(越低越好)
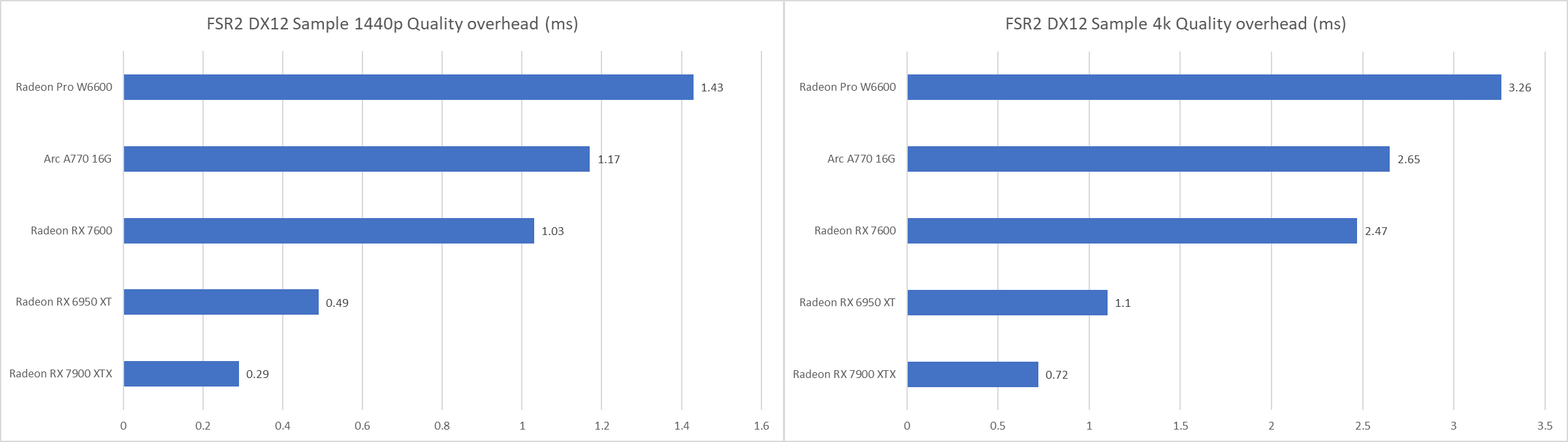
可以看到RDNA3相比RDNA2大幅度降低了FSR2的性能开销,而Arc A770在每一种分辨率下运行FSR2的开销均低于W6600但是略高于RX 7600。理论上Arc A770与RX 7600会比前一代相似规模的显卡更适合使用FSR2运行高分辨率游戏。
总结与点评
RX 7600在缩减芯片面积、降低成本的情况下,相比前一代小幅度提升性能,这是RDNA3微架构PPAC进步的表现。唯一的问题在于价格:2023年的一个128bit位宽、200mm²出头的N6制程的显卡,显然本质上是50级而不是60级的产品。例如2019年发布的RX 5500 XT显卡有同样的128bit位宽和158mm²的面积,它的8GB版本MSRP是$200。如今在N6远比2019年的N7便宜的情况下,RX 7600这样的显卡卖到$270左右是否真的合适?
对于Arc A770而言,其实当我把Arc A770与RX 7600这两者放在一起作比较的时候,Arc就已经输了。尽管RX 7600的代际提升不尽人意,又尽管Arc A770在这一对比中与RX 7600打的有来有回、不相上下,甚至在光线追踪测试里具备全面领先的优势。但无法忽视的是,A770在同样的TSMC N6节点上,相比RX 7600使用了将近两倍的芯片面积、高40%的功耗,却在大部分测试里没有与之相称的优势。这代表着Arc目前与Radeon存在巨大的PPAC鸿沟,而作为大规模并行计算的电路,PPAC就是GPU的生命,是微架构竞争力的最直接体现。在这方面,Radeon追赶了NVIDIA很多年才有了今天的成绩,而Arc看起来还有更长的路要走。
除此之外,A770有着非常严重的utilization/scaling问题。降低分辨率、降低特效经常不能足够有效地提升帧数。这一点只有在对同一个游戏测试多个不同质量预设的情况下才能看得出来,而大部分评测通常是无脑用最高画质,并不能反映问题。遗憾的是,在Arc A770相比竞品有足够性能优势的画质和分辨率下,它本身的帧数也已经低到体验非常差的程度。这让我不禁想起几年前的Vega GPU的表现,尽管两者在微架构上没有什么直接关联。
对于普通消费者来说,芯片本身的PPAC并不是特别值得关注,只需要关注厂商如何定价即可。在这一方面,尽管Arc目前的价格已经足够具备性价比,但这是建立在Radeon/GeForce N-1库存高位,新品控价,谁也不愿意第一个降价的市场环境下。显然Arc的降价空间没有Radeon/GeForce那么大,他们的MSRP定价策略也并非足够的搅局。总的来说,我认为A770、A750官方定价在RX 6600 XT、RX 6600的实际销售价格附近比较合适。
这两张显卡虽然各有各的看点,但正如标题所说,它们依然是卧龙凤雏(讽刺意义的)。在新品显卡价格回归正常之前,或许都不太值得考虑。