
上一篇文章里,我们浅显地聊到了Zen 5的微架构层面的变化,主要是规模的扩大、指令吞吐的提升,以及最关键的关于分支预测的改动。
本文我们将会进行一些性能分析与对比,观察Zen 5微架构这些改动会对实际负载造成怎样的影响,与前代相比会发生怎样的变化。
由于桌面Zen 5也就是Ryzen 9000系列的高端型号暂时没有发售,因此本文目前依然是使用移动端HX 370进行测试。后续会直接将有价值的数据补充在本文。
2024/08/13 更新:修正了因为GCC bug引起的x264子项测试数据问题。此前沿用了部分znver3的老数据,但是新测试的数据使用znver4导致得出x264几乎无提升的结论。统一flag之后无论是znver3还是znver4/5均可获得类似的提升幅度。更新后将所有此前使用-march=znver4测试的Zen 4/5的数据使用-march=znver3重新测试。
SPEC CPU 2017
在撰写本文前,我已经将HX370的SPEC CPU 2017单线程整数测试结果更新到博客页面,本文会注重分析性能背后的微架构细节。
单线程性能
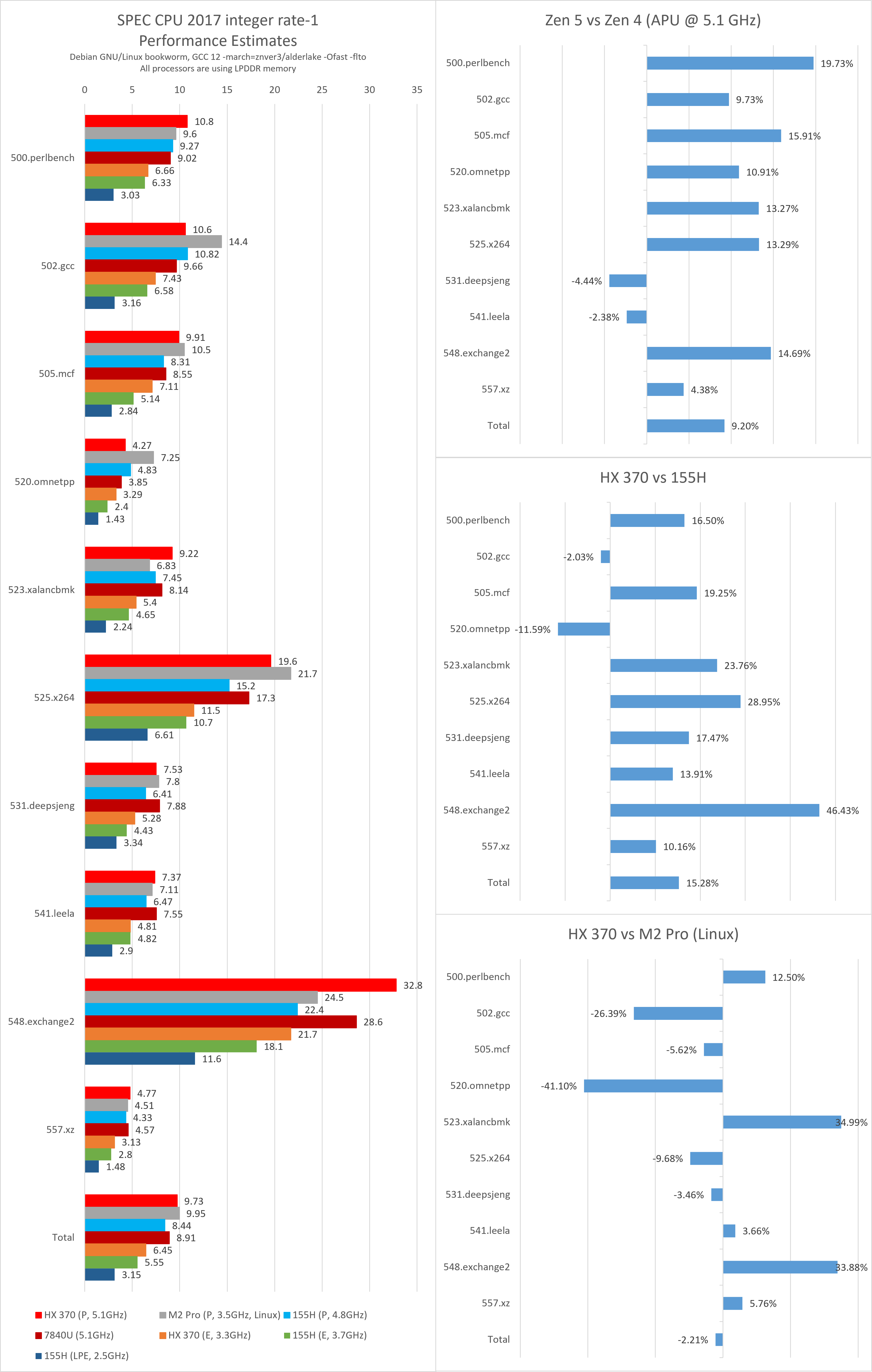
Zen 5的单线程整数性能与其主要的竞争对手相比,
- 高于7840U约9.2%;
- 高于155H约15.2%;
- 低于M2 Pro约2.3%。
Zen 5与Zen 4相比,
- 在perlbench、mcf、x264、exchange2子项中有相当大的提升(>10%);
- 在gcc、omnetpp、xalancbmk子项中有较大的提升(~10%);
- 在deepsjeng、leela、xz子项中几乎没有提升,甚至有所倒退(±5%)。
Zen 5与155H相比,
- 在gcc子项中几乎没有性能差异,在omnetpp子项中劣势较大(~10%),这些子项与L3缓存容量关系较为密切;
- 在exchange2子项中优势巨大;
- 在其余子项中均有较大的性能提升。
Zen 5与M2 Pro (Linux)相比,
- 在perlbench、xalancbmk、exchange2子项中有较大优势;
- 在gcc、omnetpp、x264子项中有较大的劣势;
- 其余子项性能接近。
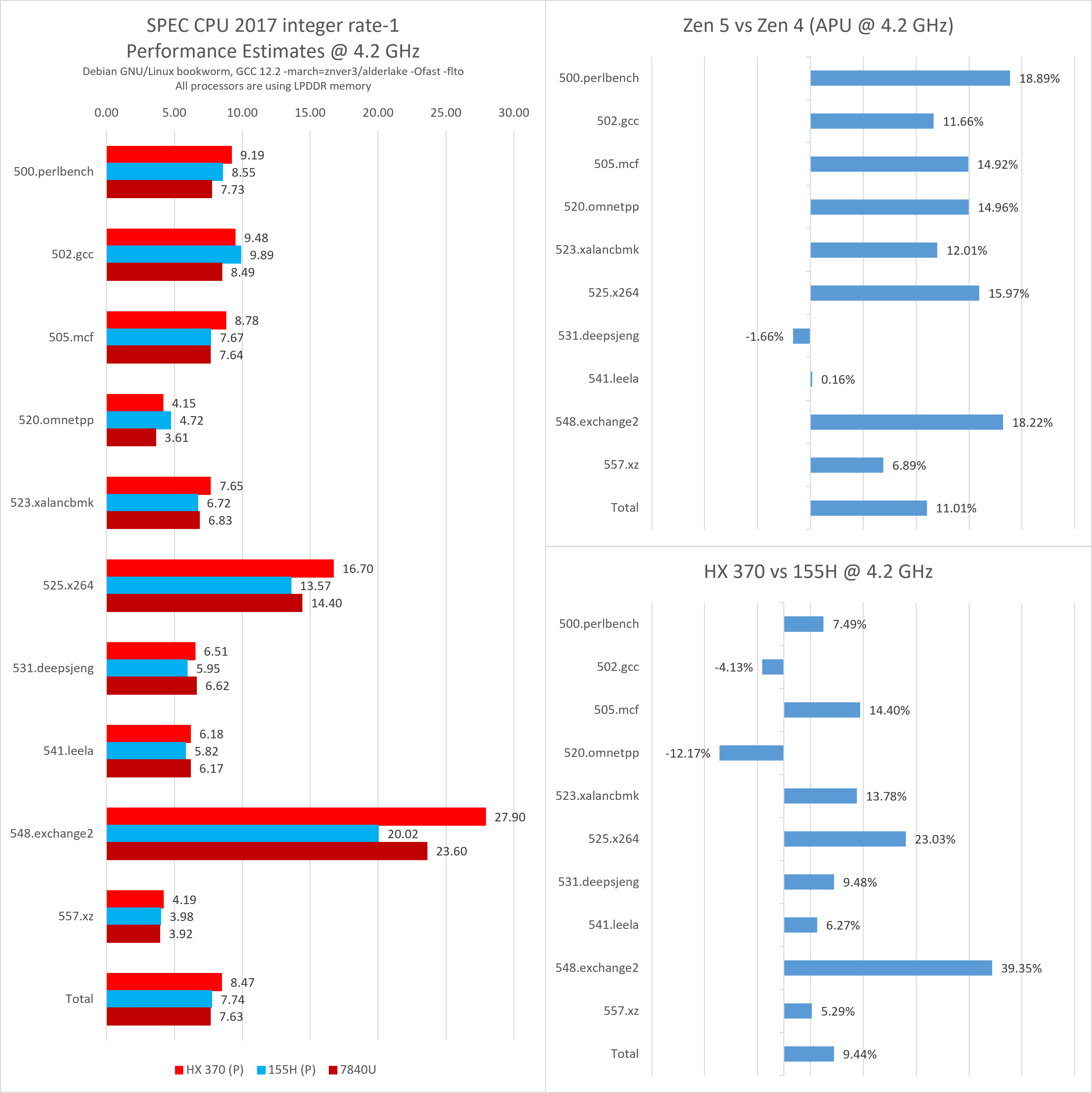
单线程IPC
为了更好地消除频率差异带来的影响,这里提供同频(4.2 GHz)的测试数据进行比较。同频测试的结论与上面的默频测试差异不大。
SMT性能
SMT在本代成为了AMD最独特的功能——其长期的竞争对手Intel近日宣布在消费级产品中移除SMT,而ARM阵营支持SMT的内核则是几乎没有出现在消费级产品(除了华为泰山等服务器下放架构)。
将处理器频率定为3GHz分别测试其4核4线程与4核8线程的性能,并记录其封装功耗:
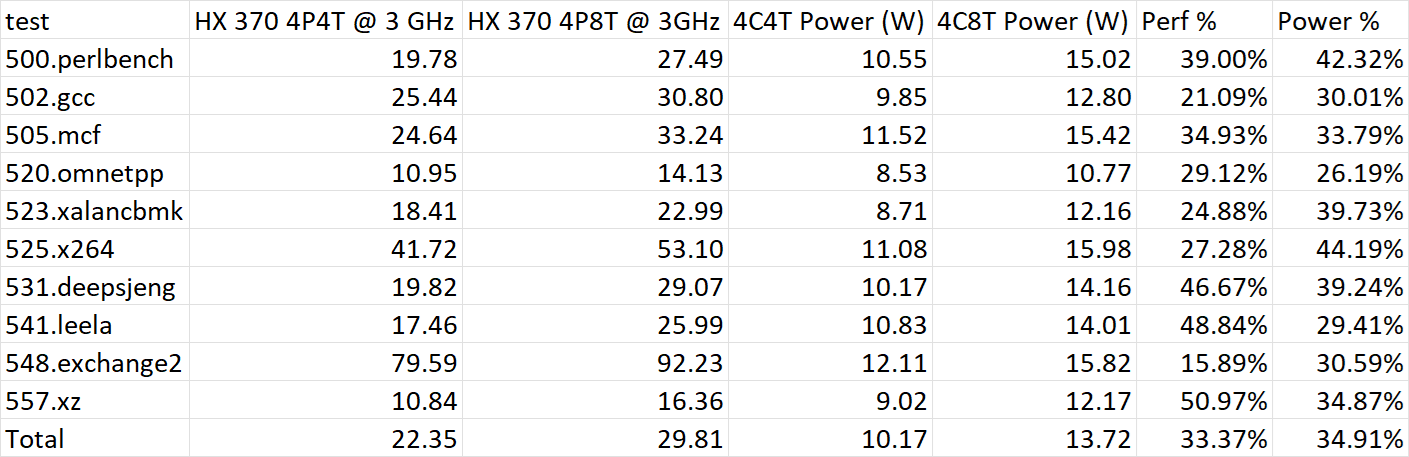
可以看出,在每核心4MB L3的测试环境下,SMT几乎在所有子项里都能带来非常明显的相同频率的性能提升。诸如deepsjeng、leela、xz等部分子项的性能提升甚至能达到50%附近。
当然,SMT也会非常明显地增加核心功耗。在部分子项里,SMT对功耗的增加远大于性能提升;但在另一部分子项里则刚好相反。总的来说,SMT对性能的提升与其功耗提升基本相当。
性能瓶颈分析
针对SPEC CPU的测试数据,我们可以提出很多问题,例如
- 为什么处理器从6发射提升到8发射、后端从4 ALU提升到6 ALU之后的性能提升远低于纸面数字的提升(33%-50%)?
- 从最早测试的微架构Microbenchmark中发现单线程在op cache失效时只能做到4宽解码,这一现象对性能有多大影响?
- deepsjeng、leela、xz这几个子项的提升为什么微乎其微,甚至发生倒退?
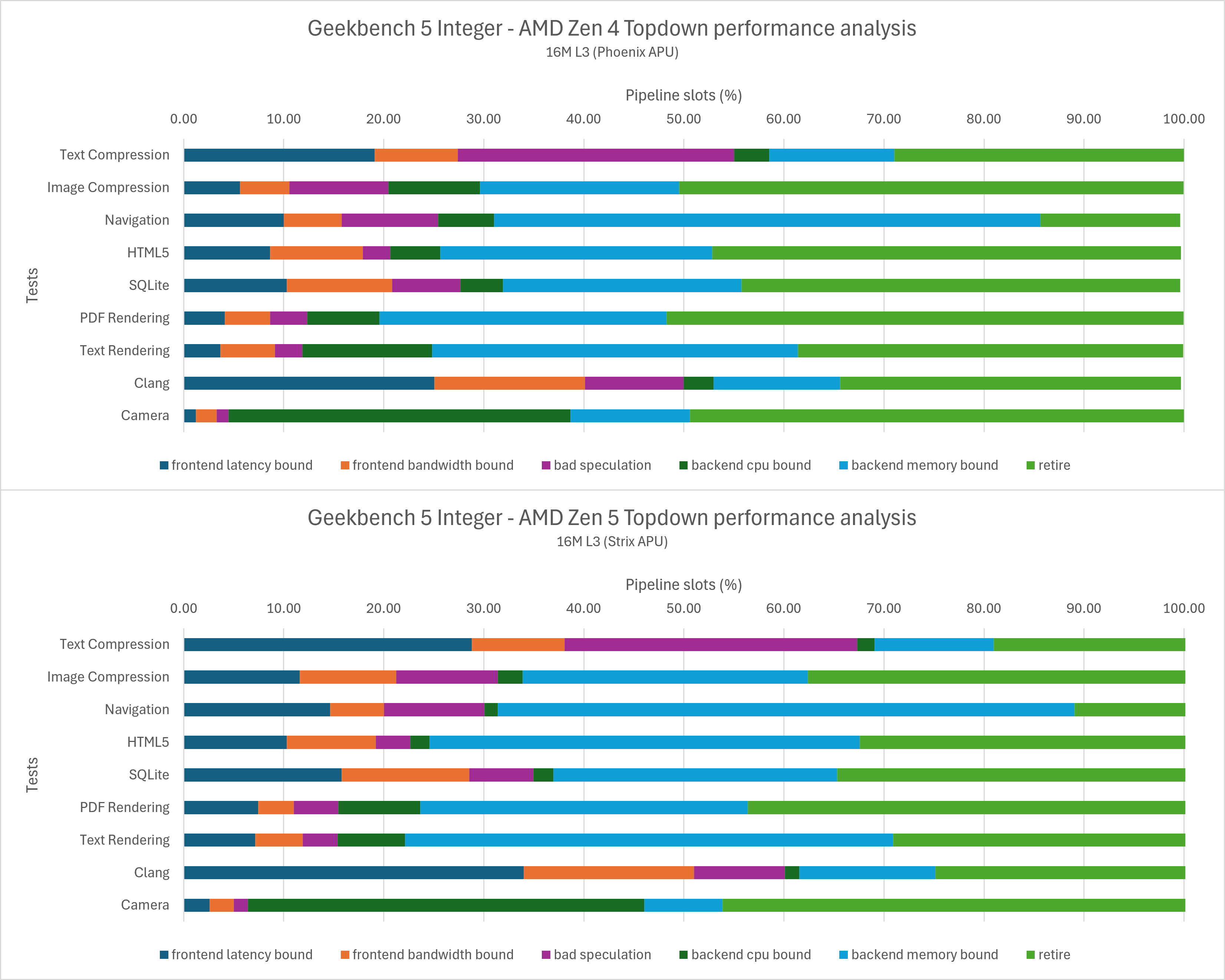
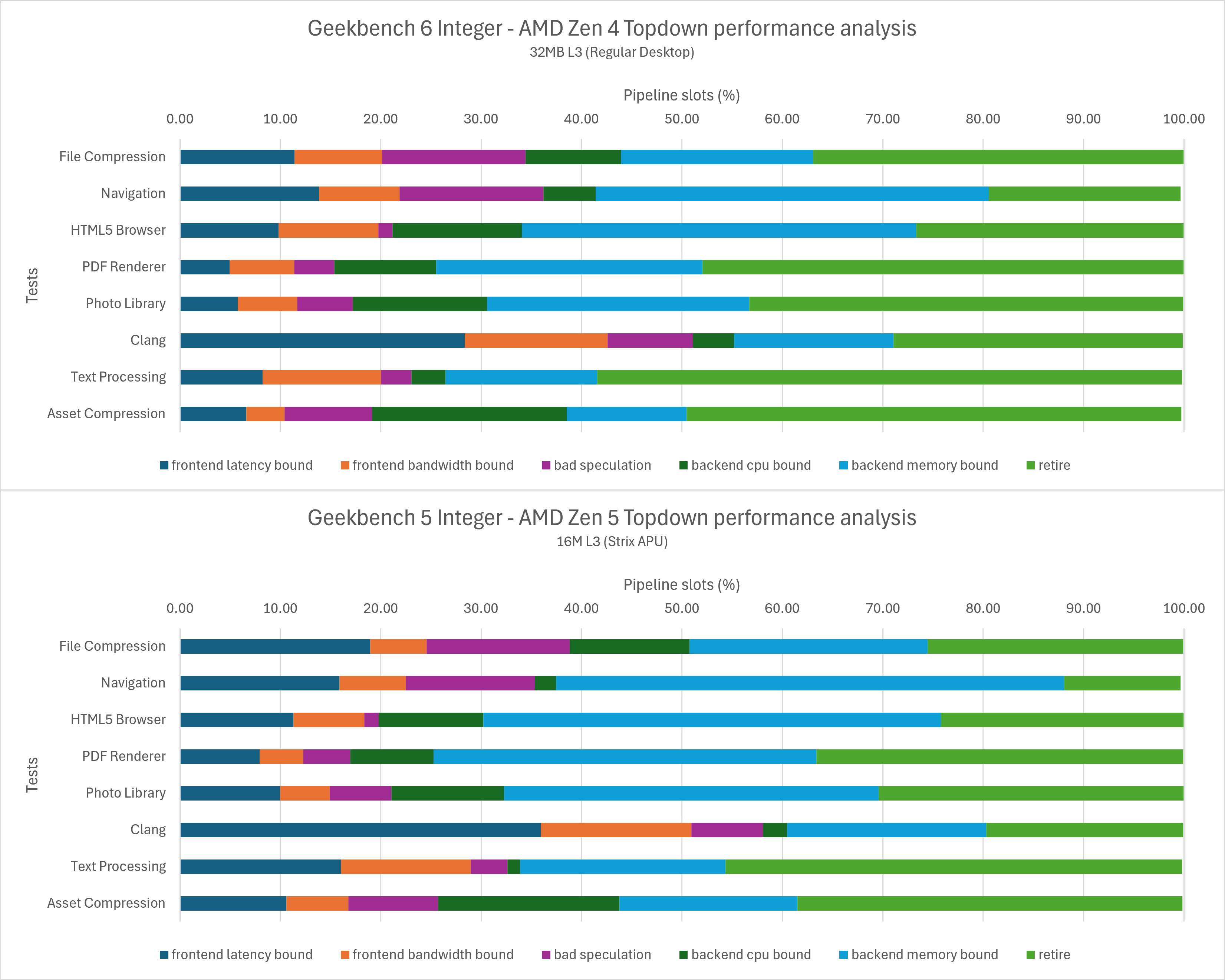
由于SPEC CPU是多项测试组合而成的综合测试,因此我们需要对其中每一个子项单独进行分析,回答这些问题也会比较复杂。由于篇幅所限,本文将从现成的PMC数据入手,为解答这些问题提供一个大致的方向,而不是尝试完全解释这些问题。
指令融合 (macro fusion)
在进行性能分析之前,首先我们要先观察处理器实际执行的指令差异。尽管本次测试中的所有AMD处理器均使用了同样的编译器参数,但指令融合依然会对处理器前后端产生差异。
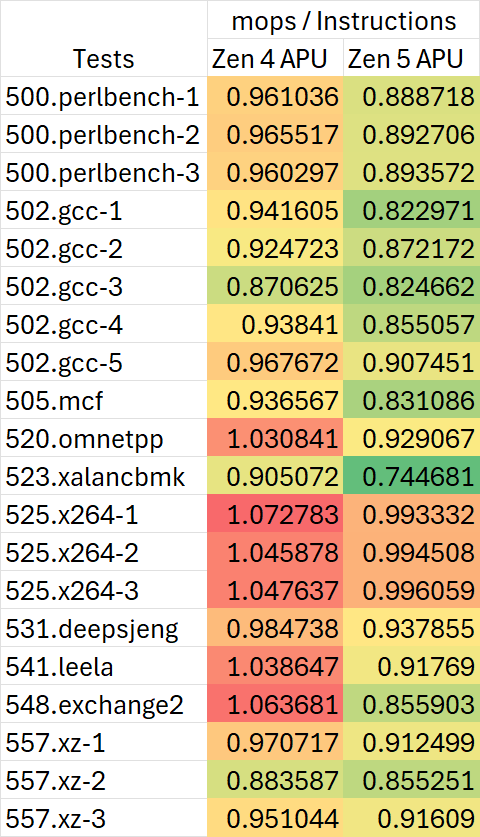
如上图所示,Zen 5在SPEC int的所有测试项里都有更好的指令融合表现。这代表着Zen 5运行同样的代码,其dispatch / rename / retire的吞吐压力都要小于Zen 4,op cache / re-order buffer / scheduler等容量压力也要小于Zen 4。同时,它运行同样的代码会占用更少的pipeline slots,这一点对后面的topdown分析会有一些影响。
改进的op cache与消失的loop buffer
Loop buffer是前代Zen处理器中用于优化tight loop的机制。AMD在Zen 5这一代直接移除了loop buffer相关的PMC事件,mop来源只剩下x86解码器与op cache两项。
Loop buffer的移除可能是因为Zen 5支持单周期处理多个taken branch且btb容量巨大,所以不再需要这些针对循环的优化。其op cache本身就能做到类似loop buffer的效果。
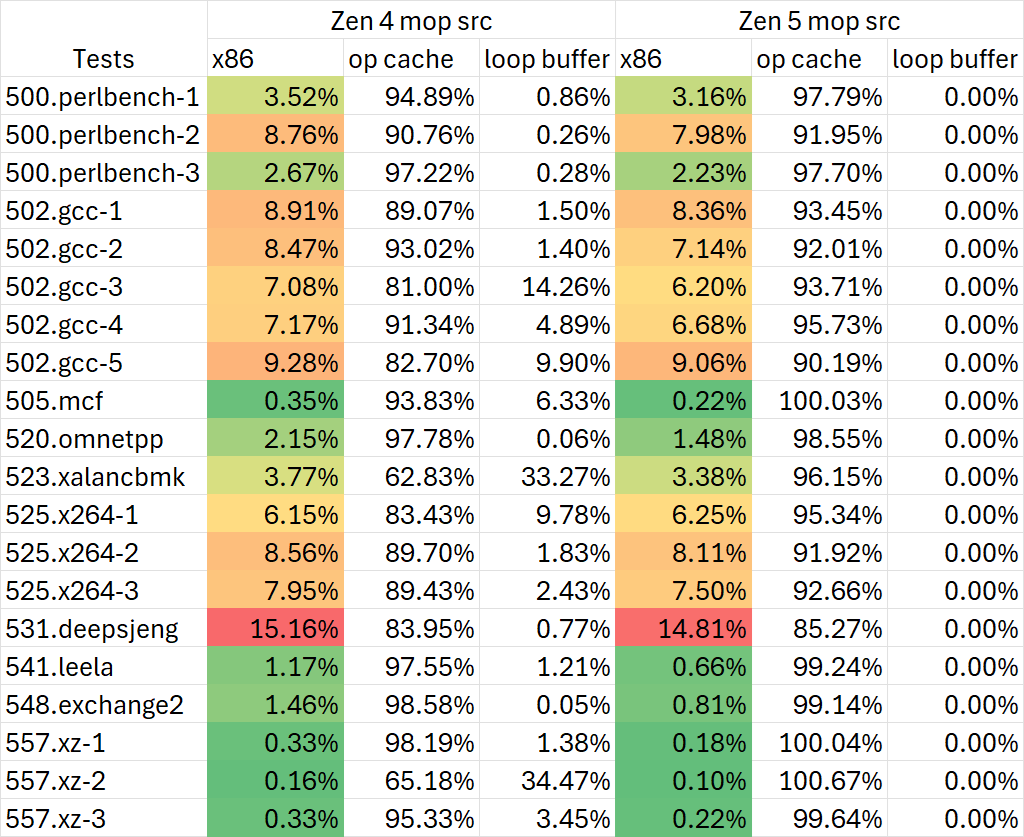
图中接近/超过100%的比例可能是PMC测量误差导致
通过观察mop source相关的PMC,我们可以看出尽管Zen 5的op cache从6.75K缩减到6K,但实际效率是增加的。在绝大多数情况下,Zen 5来自于x86 decoder的mop占比都要小于Zen 4。这可能是由两个原因共同导致:
- Zen 5改变了op cache的组织结构,从Zen 4的9 mop * 768 entry (12-way)改为6 mop * 1024 entry (16-way),而更多的entry和更高的相联度都能提升op cache的实际等效容量和利用率;
- Zen 5改进了macro fusion使得同样的程序产生的动态mop数量减少。
总的来说,尽管在此前的测试里op cache等效容量疑似发生缩减,但在大多数情况下Zen 5依然维持了相当高的op cache使用率。也就是对于SPEC int而言,其x86解码的宽度在大多数情况下对整体性能无伤大雅,这一点在后面的性能分析中也可以看出。
当我们尝试关闭op cache,则会产生如下的性能影响:
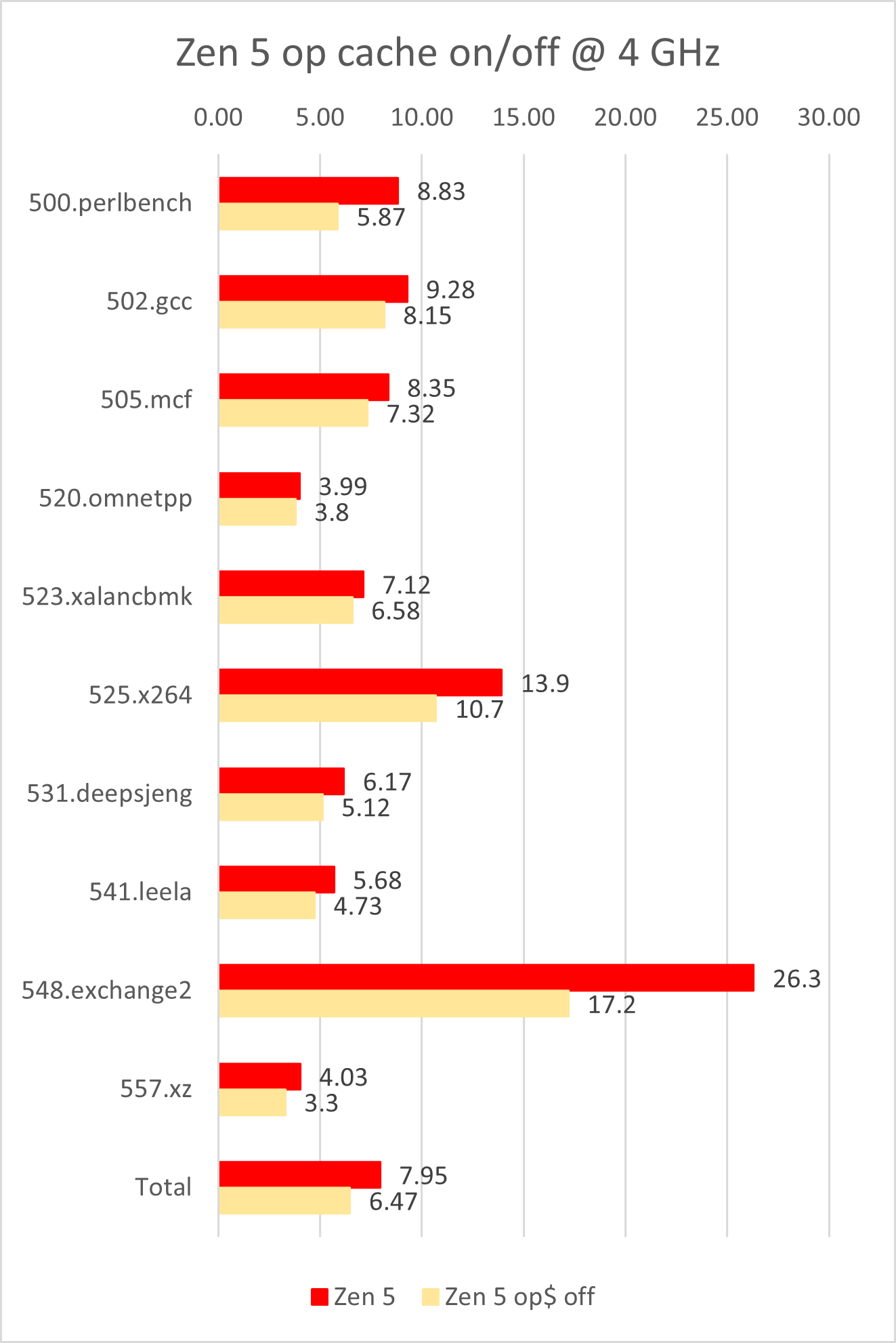
Op cache对Zen 5的性能提升在23%左右。作为对比(非严谨),根据现成的测试数据,7950X开启op cache的性能提升仅有13%左右。可以看出,对于Zen 5而言,op cache的重要性远高于前代架构。
Topdown性能分析
使用Linux v6.10.2的perf工具分别记录Zen 4/Zen 5的topdown metrics,如下图所示:
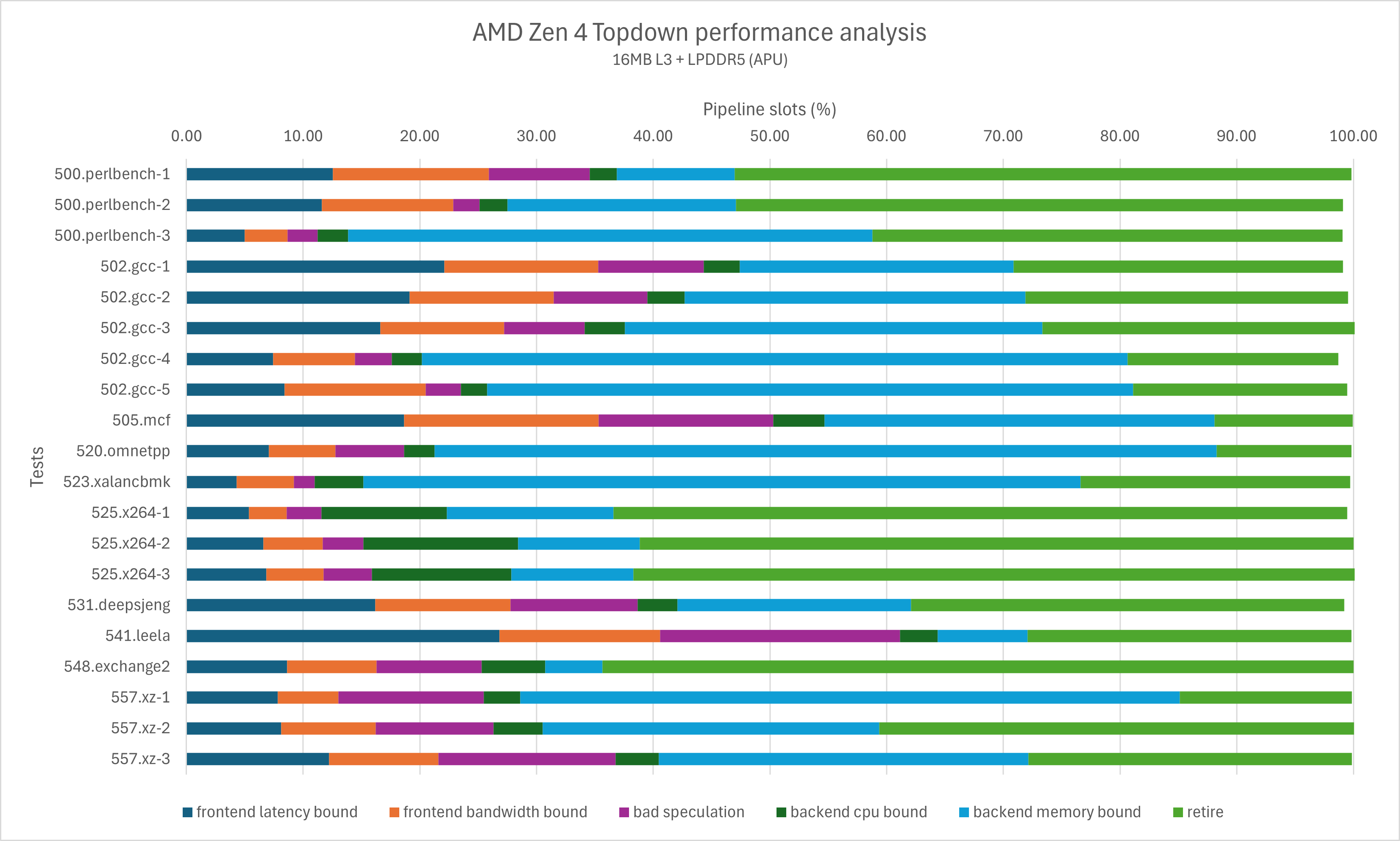
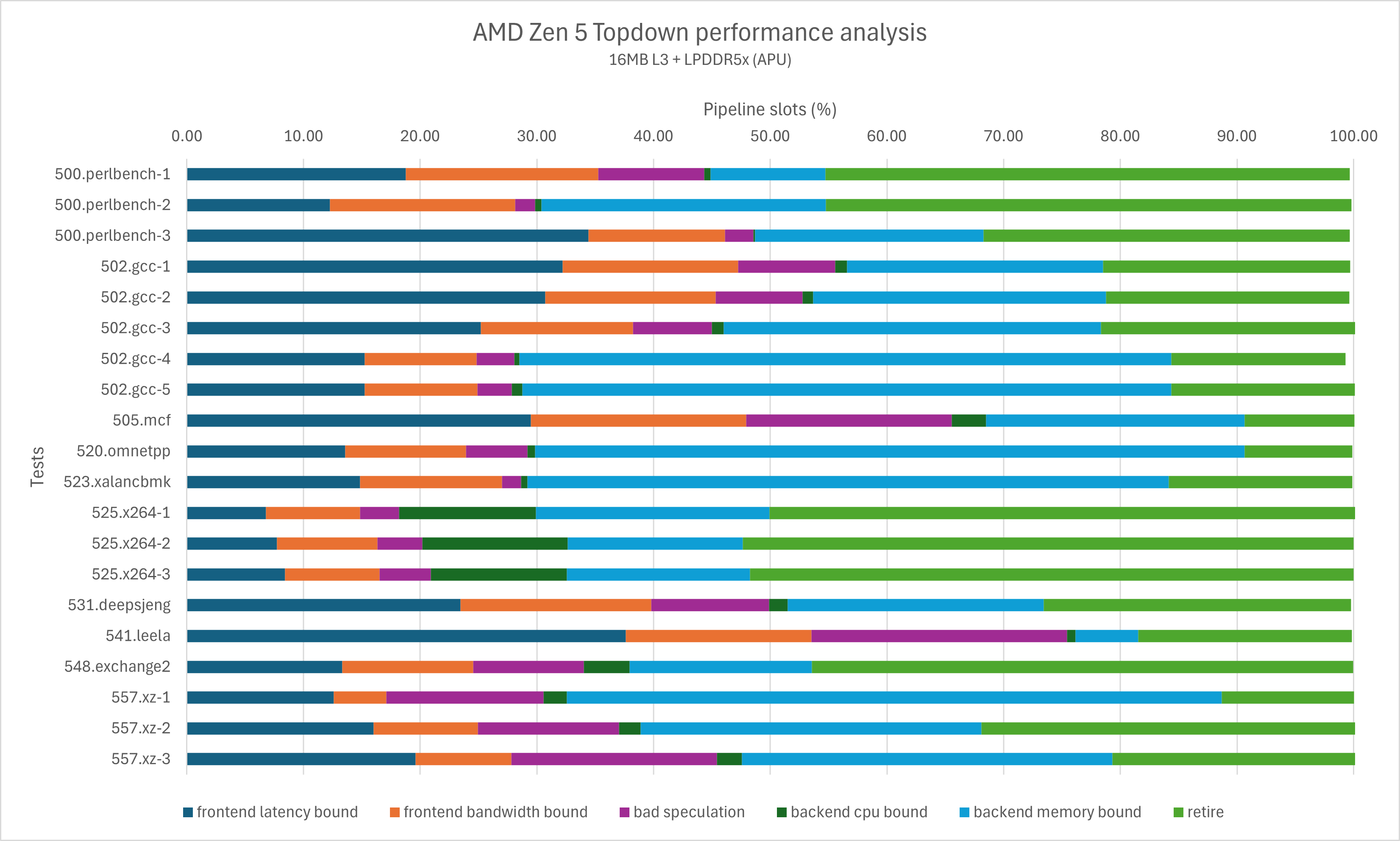
由于Zen 5是8-wide rename的架构而Zen 4只有6-wide,因此它们同样的百分比数值实际上代表的不是同一个意义。为了更直观的对比,我们将百分比改为绝对值重新做一组对比图,这张图展示了不同原因的pipeline空泡,也就是距离理论的最大IPC(6或者8)的差距都在哪些地方。
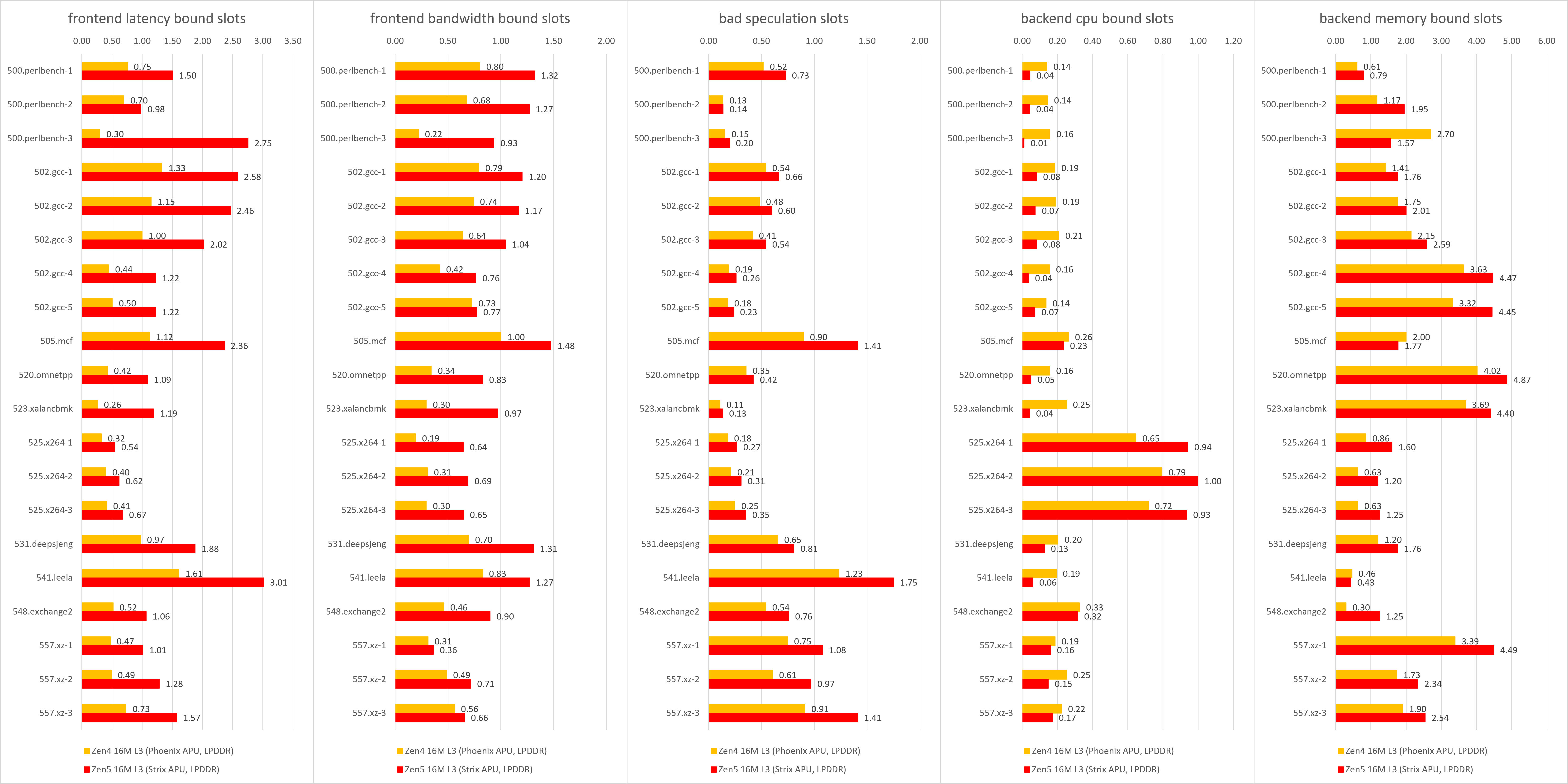
注意图表的刻度差异
可以看出,在deepsjeng、leela、xz这几个我们最关心的提升较小的子项里,
- deepsjeng子项:前端延迟瓶颈显著增加,后端访存瓶颈也出现一些上升;
- leela子项:前端空泡达到了2.4左右,尽管后端CPU瓶颈有所下降,但依然无法避免IPC出现明显降低;
- xz子项:前端延迟瓶颈显著增加,分支预测失效清除的mops增加。这个也非常容易理解,Zen 5不仅加宽了dispatch/rename宽度,还拉长了流水线,发生分支预测失效时的slots损失会显著高于Zen 4。
除此之外,在gcc以及部分perlbench的测试中也可以观察到显著的前端延迟瓶颈增加。
前端性能瓶颈
我们继续分析前端的性能,可以发现更多蛛丝马迹。
典型的前端latency bound可以大致的分解为以下几种可能:
- L1i/iTLB miss:取指令时发生缓存缺失而产生空泡;
- Branch resteer:更高一级的BTB修正预测结果,产生空泡;
经过一些microbenchmark的实测,Zen 5由于超出op cache条目数量限制而导致taken branch吞吐降低到1时,会将损失的slots计入latency bound,但是关闭op cache则会将其计入bandwidth bound。 - Branch detect:分支数量超出BTB容量,完成解码/执行后才得以重定向。
我们来观察Zen 5的PMC相比Zen 4发生的变化
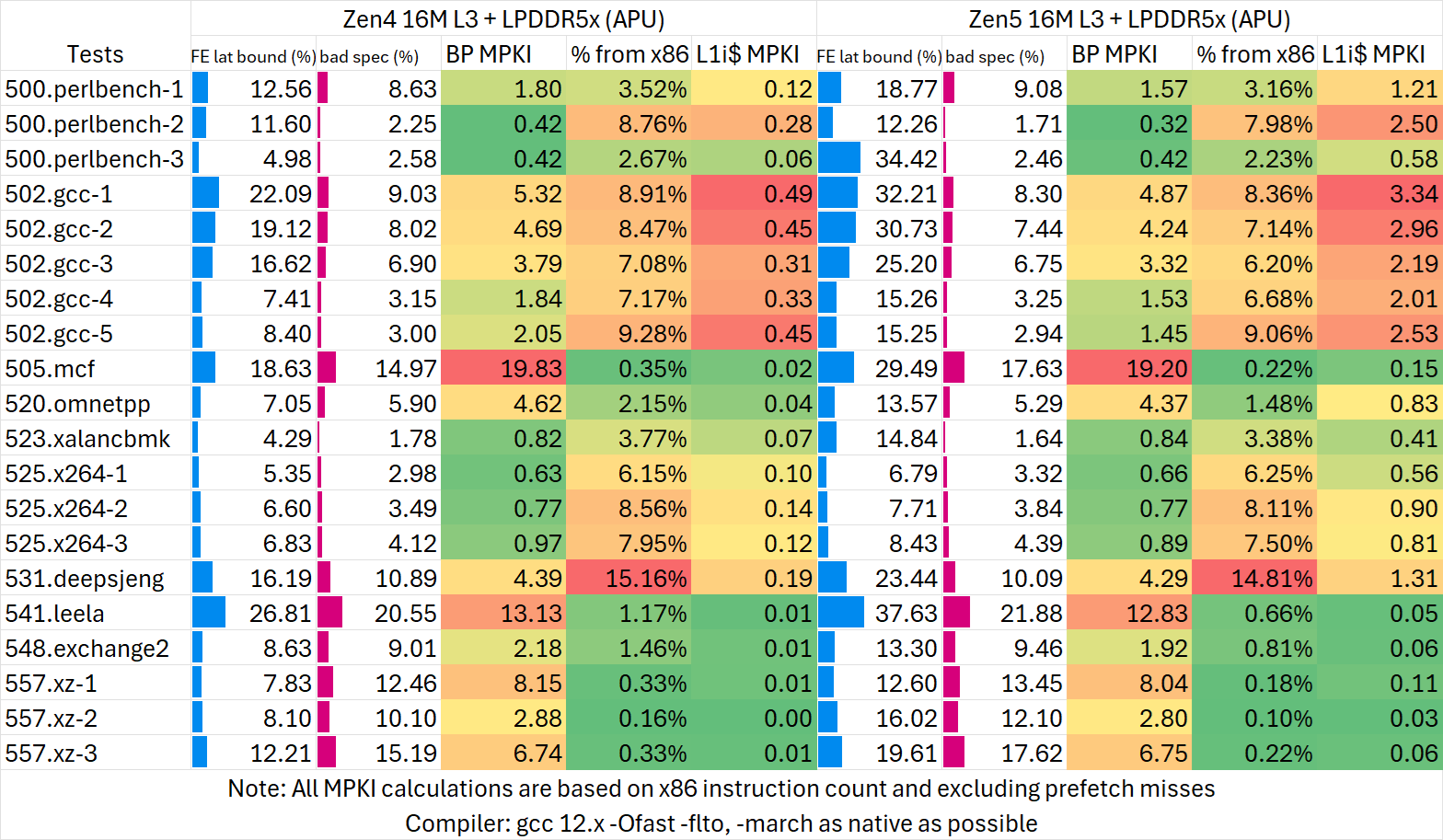
首先最明显的一点就是Zen 5的L1i MPKI相比Zen 4明显增加了许多倍。现代高性能处理器的分支预测单元能很准确地预测指令流的去向,以此来指导L1i的预取。在分支预测正常工作的情况下L1i的MPKI应当非常低,但Zen 5显然在这方面并没有达到预期,因此Zen 5的L1i预取机制比较值得研究。
L1 BTB:变大了,但是变笨了?
除了L1i之外,我们很容易观察到另一个PMC的异常之处:L2 BTB override,也就是上面提到的Branch resteer。这一项指标也会显著影响frontend latency bound,而Zen 5在这里发生了翻天覆地的变化。
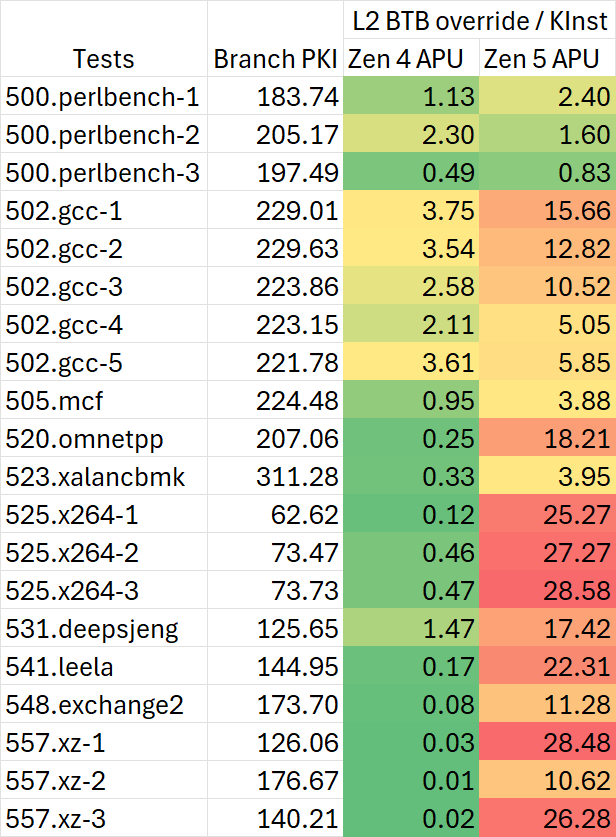
如上图所示,Zen 5的L2 BTB override的perf counter与Zen 4的画风完全不同。目前暂时不清楚这是perf counter的问题还是真正如此,因此本文暂时只呈现一些数据,不对其进行过多的解读。关于Zen 5的L1/L2 BTB为什么画风会如此奇特,可能需要等待后续更多来自AMD官方的微架构细节。
其它前端相关的PMC(例如branch detect)暂时未发现不符合预期的数字,这里不再赘述。
数据缓存
数据缓存是Zen 5的一大亮点:首次引入了48K 12-way L1d且在不牺牲频率的前提下维持了4周期的延迟,在4nm制程下实现了竞品3nm的水平,频率还更高。
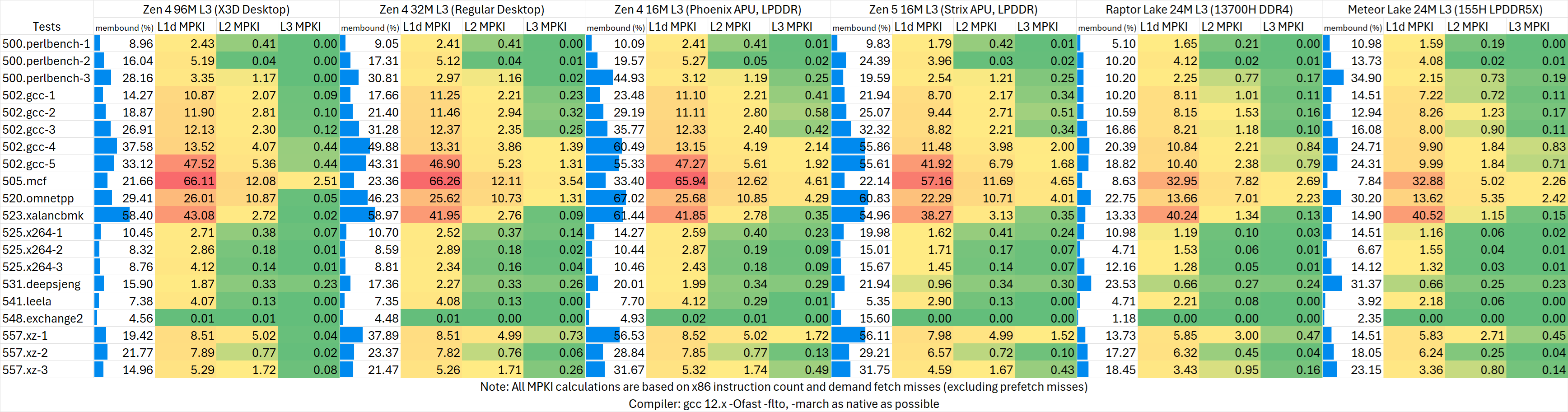
从测试结果来看,Zen 5增加的L1d容量的效果显著,在很多测试里相比Zen 4大幅度降低了L1 MPKI。但在大多数测试里依然不如Intel平台同容量的L1d命中率高,其memory bound的程度也高于Raptor Lake与Meteor Lake,当然这两者的次级与末级缓存容量也要更大,不适合直接比较。
能效曲线
能效是移动端处理器的重中之重,AMD从Zen 2开始正是因为在能效方面具备较大的优势所以赢得不少用户的青睐。我们照例使用SPEC CPU 2017在Linux环境下测试单线程、多线程的能效曲线图。
需要注意的是,Strix Point是较新的SoC,需要手动编译内核包含一些尚未合并的kernel patch才能正常使用电源管理与监控。
除此之外,华硕的这台Zenbook在低功耗会出现非常明显的package功耗读数偏高的问题,在Windows与Linux下都可以复现,并且可以通过其它电流计确认这个功耗并不存在(例如电池放电比package功耗还低)。本文所提及的package功耗在低功耗下至少偏高2W左右。
核心能效
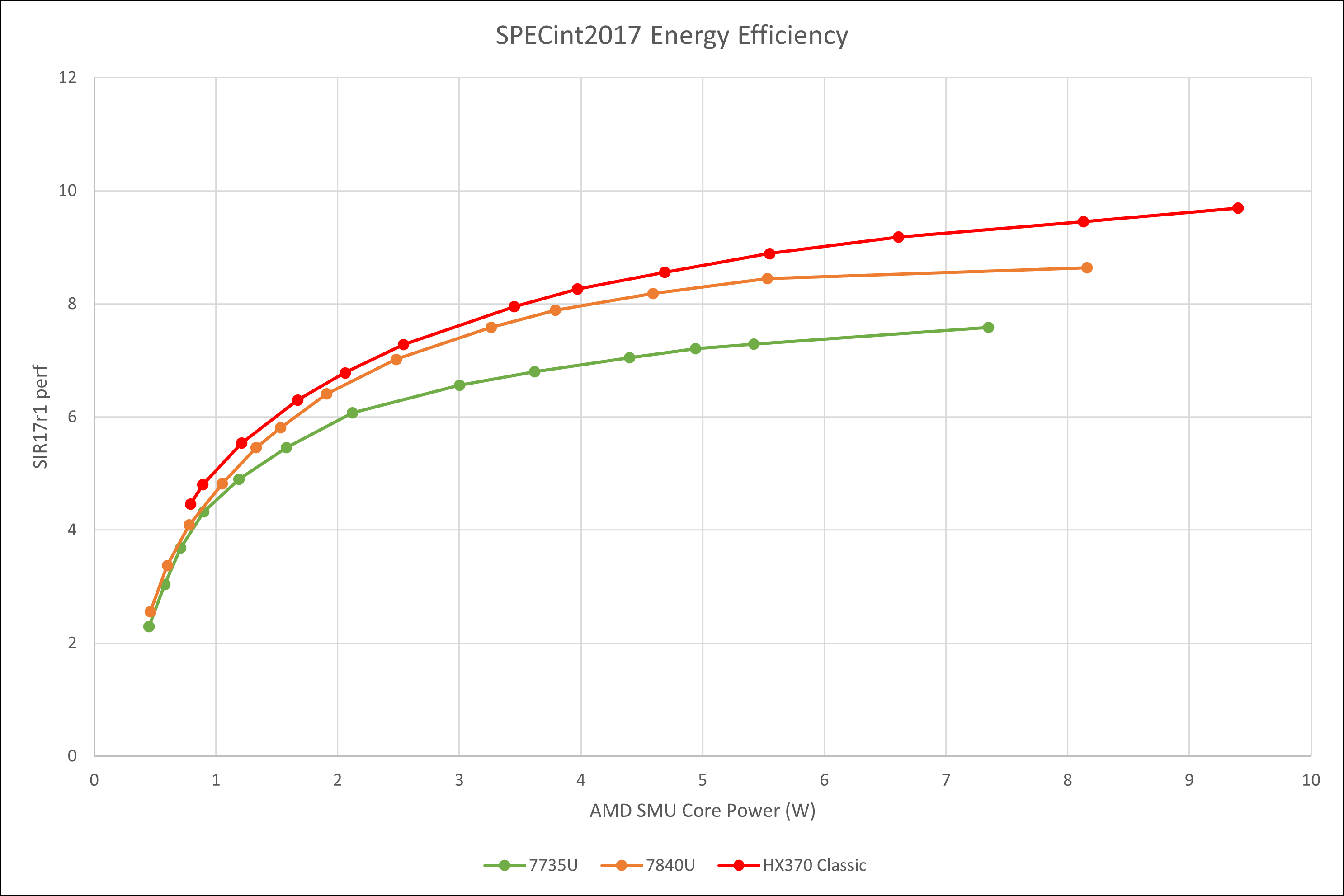
使用msr读取核心本体的功耗(MSRC001_029A),绘制不同频率下的能效曲线。我们可以看出,Zen 5在高功耗下具有更强的极限性能,低功耗的能效则与Zen 4几乎保持相同。
Package能效
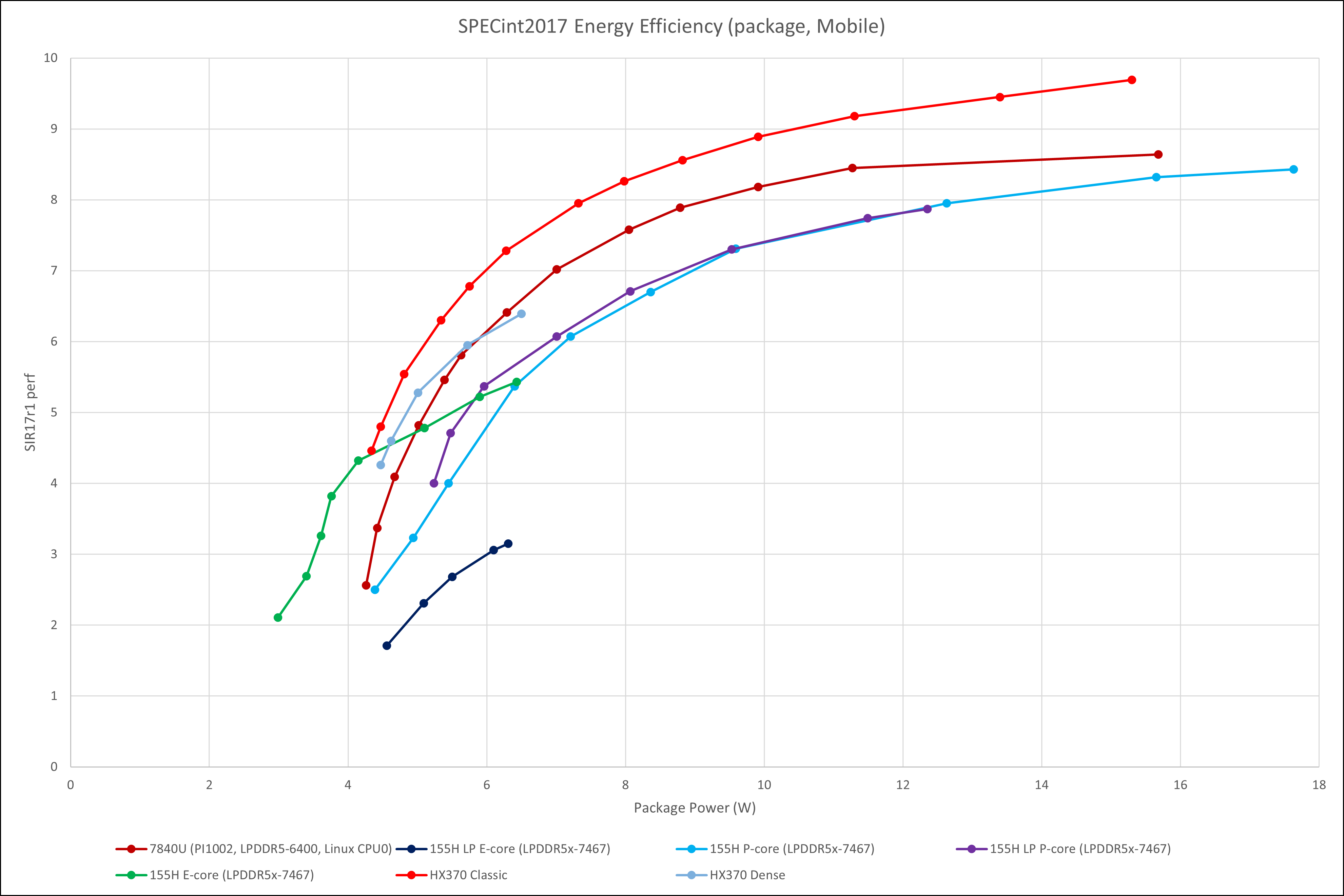
使用msr读取package功耗(MSRC001_029B),绘制不同频率下的能效曲线。我们可以看出,尽管Strix Point在Zenbook这一台机器上存在低功耗报告的问题,其package能效依然在所有频率下遥遥领先其它的大核。尽管其极限性能下的核心功耗高于Zen 4,package功耗却更低,这说明Strix Point在SoC层面比Phoenix更加节能。
相比之下,Zen 5c的能效则不那么乐观。图中的Zen 5c的测试范围为2 – 3.3 GHz,可以看到Zen 5c在这个范围内的单线程能效要全程低于Zen 5大核。这也就意味着Strix Point上Zen 5c的性质类似Intel在12-13代加入的小核——以Cinebench刷分为主要目的。
多线程与SMT能效
前文简单提到了Zen 5的SMT在3 GHz下的性能与能效,但那只是一个单一的点。本次也测试了从2 GHz到默频(大约4GHz)的4核8线程/4核4线程能效曲线
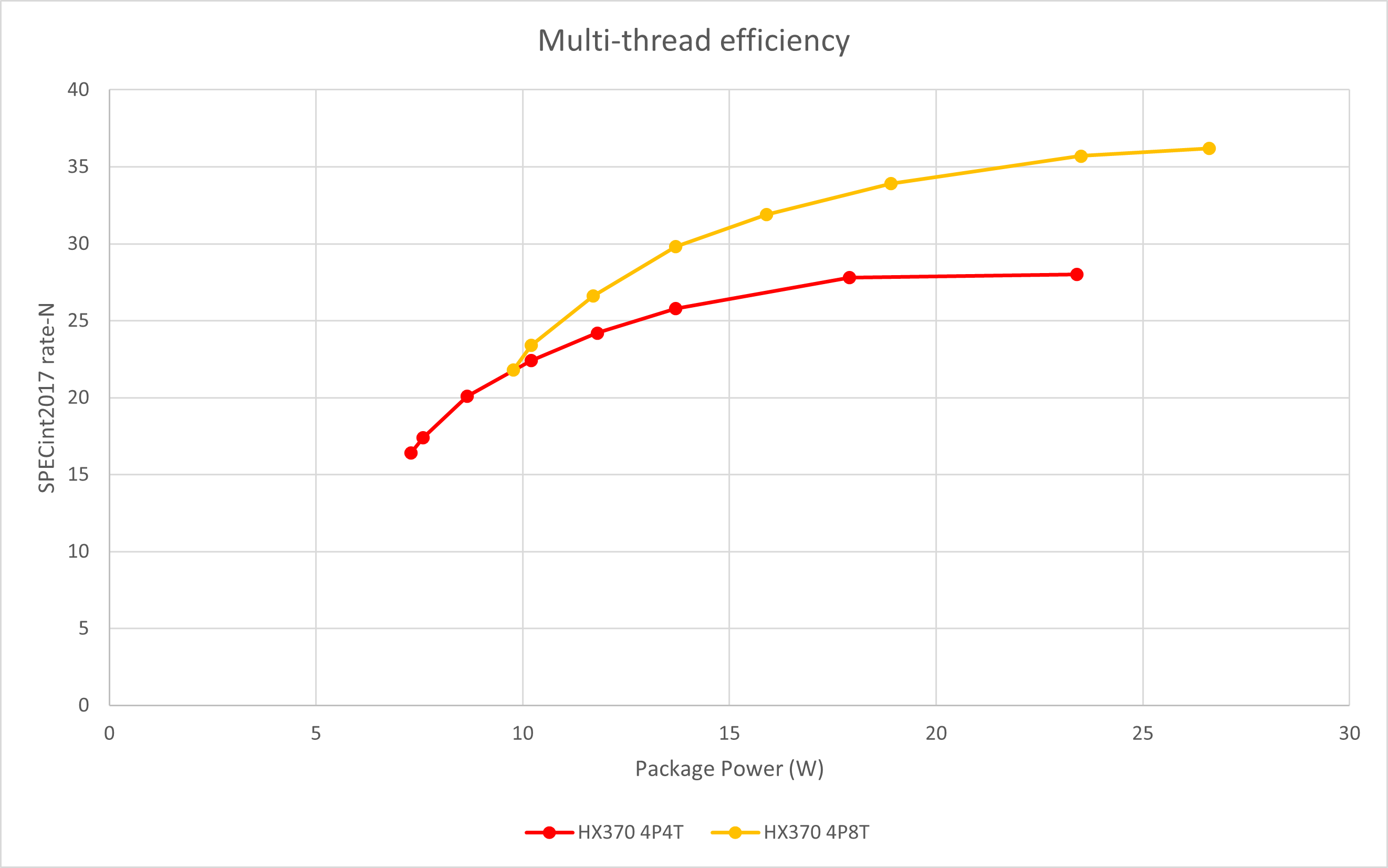
可以看出SMT对高功耗段的性能有着相当大的提升,但是在低功耗下则表现出能效不佳的趋势。
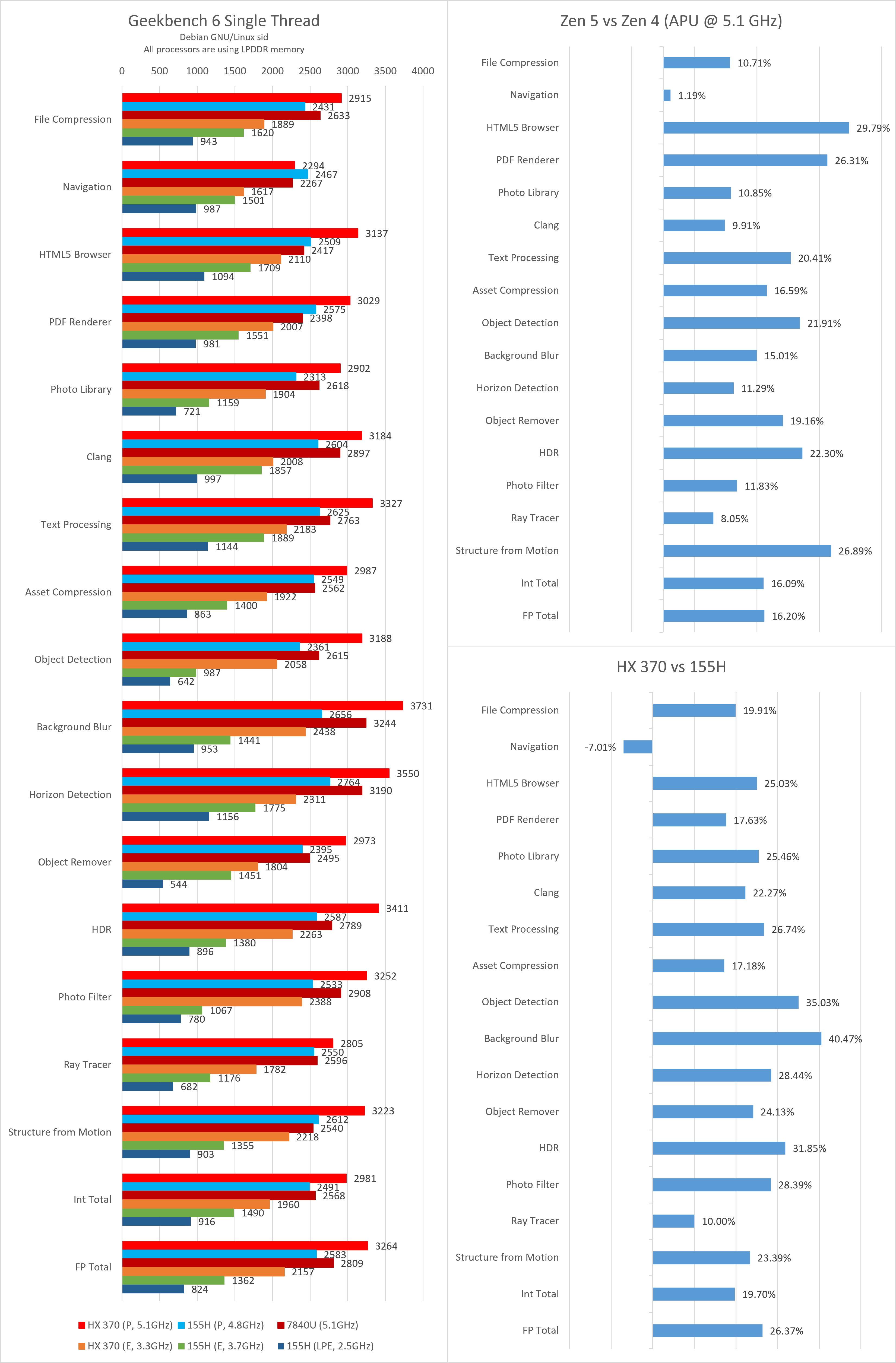
Geekbench
相比SPEC CPU,Zen 5在Geekbench里的表现则要显得更加符合预期。因此本文也不再详细分析Geekbench的性能瓶颈,只给出测试数据作为参考。
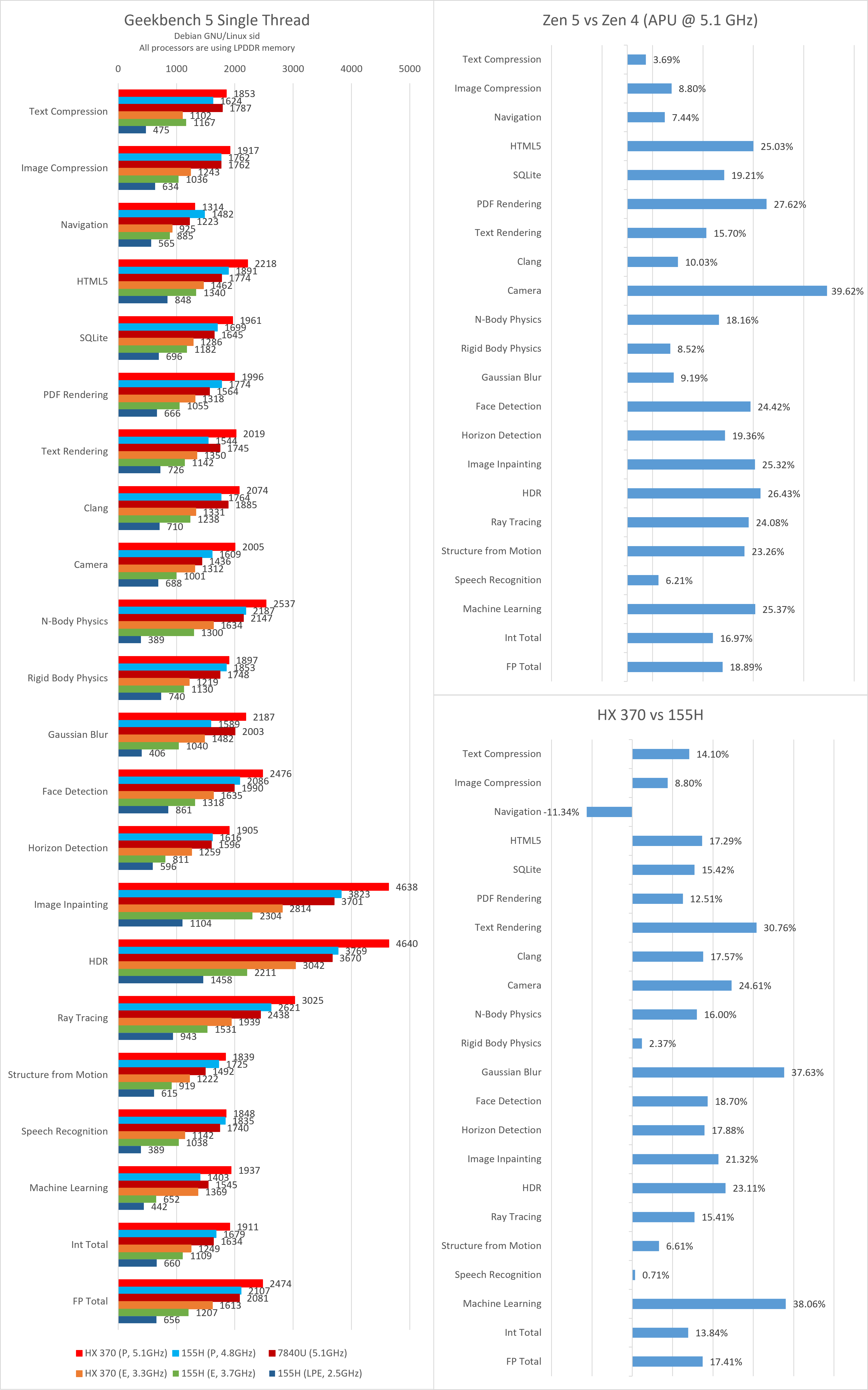
单线程性能
Geekbench 5
Geekbench 6
性能瓶颈分析
Geekbench 5
Geekbench 6
总结
性能
单纯从性能上看,在制造工艺和芯片面积变化不大的背景下,Zen 5的提升可以说是中规中矩,稳中有进。虽然整数性能的提升幅度与我个人预期有一些差距,但考虑到当前半导体行业整体提升不大的环境,它也并没有特别让我失望。事实上,相比以往不增加L3缓存时的性能提升,Zen 5的表现确实算是正常的。
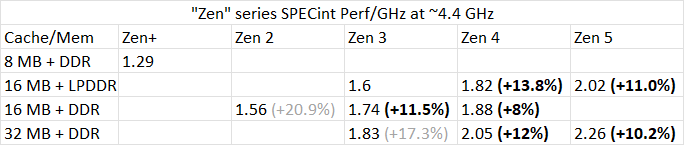
(2024/12/2 更新加入Zen 5 32 MB L3 + DDR) 历代”Zen”架构的SPEC CPU 2017整数性能提升,其中灰色的提升数字包含缓存的增加,而加粗的数字则为相同的L3缓存容量。
这让我不禁想起了一些人之前散布的那些离谱的传言,最终被事实证明是错误的。他们不仅被打脸,还恼羞成怒地声称Zen 5是自推土机以来最差的架构。关注我Twitter的读者可能还记得,我在文章中提到的PMC数据其实早在4月初就开始收集了。当时我的目的是想看看要实现某些人吹嘘的那种性能提升,到底需要做多少工作。结果发现,只要简单地看一下PMC数据,就能知道对于现在的x86微架构来说,在不牺牲极限频率和极限性能的情况下,想要达到那些离谱传闻中的目标简直是“做梦”。
所以,我的建议是不要理会那些不靠谱的传闻,还是应该修正自己的预期比较好。在半导体工艺没有重大突破的情况下,未来很多年内的CPU性能提升恐怕也只有这个幅度了。这句话我在今年每一家芯片厂商发布产品之后都会提一次,因为无论是ARM的Cortex-X,还是Apple A13之后的微架构,再或是AMD/Intel各自的x86微架构,都是如此。
微架构
从微架构细节上看,Zen 5无疑是一个激进的新设计,我甚至认为它应该有一个新的命名,而不是继续使用“Zen”这个名字(事实上,Zen 3就已经与原版Zen有非常大的差异)。
上一次微架构层面有如此重大改动的微架构可能要追溯到初代Zen或者推土机,前者是AMD的翻身之作,而后者则让AMD深陷泥潭。单纯从性能提升上看,Zen 5在历代架构里的提升里既不算差也不算好,显然不如原版Zen或者推土机那么“惊世骇俗”。它在为我们展示了x86乃至超标量微架构未来发展方向的同时,也留下了层层迷雾,例如目前无法在单线程测试中体现出作用的“双解码”技术。
相信后续AMD披露更多详细微架构细节之后,我们会有更多的机会来评价这样一个令人感到耳目一新的微架构。
npu砍掉,8个小核换成四个大核,性能更强成本更低,就是完美的移动处理器了。
可惜amd跟Intel好的不学,专学坏的。
这样最大的问题是刷分刷不过导致marketing不好做。我觉得给4+8是有点太过分了,弄个6+6甚至6+4都比现在好的多,不过AMD也没在zen上做过L6或者V6。
npu是必须会上的。即使不去扯什么本地跑llm这种可能更多是杂耍的功能;笔记本的音频、视频等应用,包括但不限于视频通话,音频和视频的生产制作等领域都证明了npu的作用与效能。与其复古,不如督促多适配npu
当年cuda没跟上 amd已经吃了大亏了
Has strix point the same MSR like granite ridge ?
https://x.com/InstLatX64/status/1822699473358795106
Thanks for this amazing writeup!