最近这些年的CPU市场上,虽然表面上看Intel和AMD打的如火如荼,但是Intel事实上从未满足于在笔记本电脑领域仅仅跟AMD展开竞争——他们的许多规划都是剑指Apple Silicon与MacBook。
这也并不难理解。早些年Intel Mac时期,虽然MacBook的市场份额一直不温不火,但Apple向来都是Intel最优质的客户,为Intel带来了相当高的利润。Apple不仅以高出同行的价格购买特挑、高功耗高性能的SKU,还经常提出大量的定制需求。例如Iris Plus核显的主要客户就是Apple,而Apple带来的需求扶持了Intel的GPU业务。除此之外,Apple × Intel的高端形象也使得Intel的品牌更进一步深入人心。相比之下,微软/PC阵营的高端轻薄本一直略显逊色。
因此,现任CEO Pat Gelsinger上任后多次提出想要赢回Apple这个客户。怎么赢?今天我们要测试的这颗处理器就是Intel交出的答卷。
声明:本文仅为个人测试,测试使用的一切设备、工具等资产与本人所在公司/职位无关,也没有接受任何赞助。由于使用非正式版系统固件/软件,测试结论可能与零售设备有少许差异,仅供参考
Lunar Lake给我们带来了两种新微架构,因此本文测试微架构的部分较为冗长。如果对微架构不感兴趣,可以直接跳到性能测试部分。
处理器规格
Lunar Lake (LNL-V)是一个新的处理器系列,它不隶属于前代的U/P/H等系列,也不直接与AMD的移动端处理器竞争。本次测试的型号是Intel Core Ultra 7 258V,主要规格:
- 由两个主要的tile组成
- TSMC N3B Compute tile,包含所有的CPU/GPU/NPU/fabric/内存控制器等
- TSMC N6 PCH tile,包含一部分外部IO接口
- 4个Lion Cove大核心
- 单核4.8 GHz,全核频率4.2 GHz
- 64 KB L1指令缓存,48 KB “L0”数据缓存
- 192 KB “L1”数据缓存 (新增层级)
- 每个核心2.5 MB L2
- 共享12 MB L3
- 4个Skymont小核心
- 单核、全核均为3.7 GHz
- 64 KB L1指令缓存,32 KB L1数据缓存
- 共享4 MB L2,没有L3
- 32 GB LPDDR5X-8533内存
- 8 MB Memory Side Cache 也就是ARM SoC常说的SLC,或者类似AMD的Infinity Cache
- 8核心Xe2核显
- 1024sp规格,与Meteor Lake相同
- SIMD单元的宽度增加到16,因此EU数量对应的从128个降低到64个
- 独占8MB GPU L2
如果一定要给它找一个前身,它可能与Lakefield最为接近:
- 使用最先进的制造工艺,并且SoC整体的设计偏向于低功耗而不是高性能;
- 为未来的主流SoC架构提供了一些设计方向参考;
- 使用类似手机与平板电脑的定制PMIC供电,而非传统PC的VRM架构,提高供电效率;
- MoP (Memory on Package)将DRAM集成在package内,减少主板面积需求。
不同之处在于Lunar Lake是4大核+4小核的设计,而不是Lakefield那种尴尬的1+4。不过二者在砍掉SMT这方面倒是殊致同归。
很容易看出,Lunar Lake在SoC层面是Intel几乎1:1复刻Apple M-series的产物,并且Intel在这个产品系列中用上了能用的一切手段去增强它的竞争力。
微架构
我们先从Lion Cove、Skymont两个微架构层面的细节入手,观察Intel在Lunar Lake中加入的这两个全新微架构有哪些明显的改变。
注意:由于笔者的Meteor Lake机器已经二手出售,本次并不是所有测试都有Redwood Cove / Crestmont对比数据。考虑到Redwood Cove / Crestmont本身相比前代改动不大,一部分微架构分析与对比我会使用Raptor Lake (13700H)的Raptor Cove与Gracemont进行。
指令吞吐
使用clamchowder的InstructionRate工具测试Lunar Lake两种不同核心的吞吐,并与13代Raptor Lake以及竞争对手AMD的同代微架构“Zen 5”进行对比
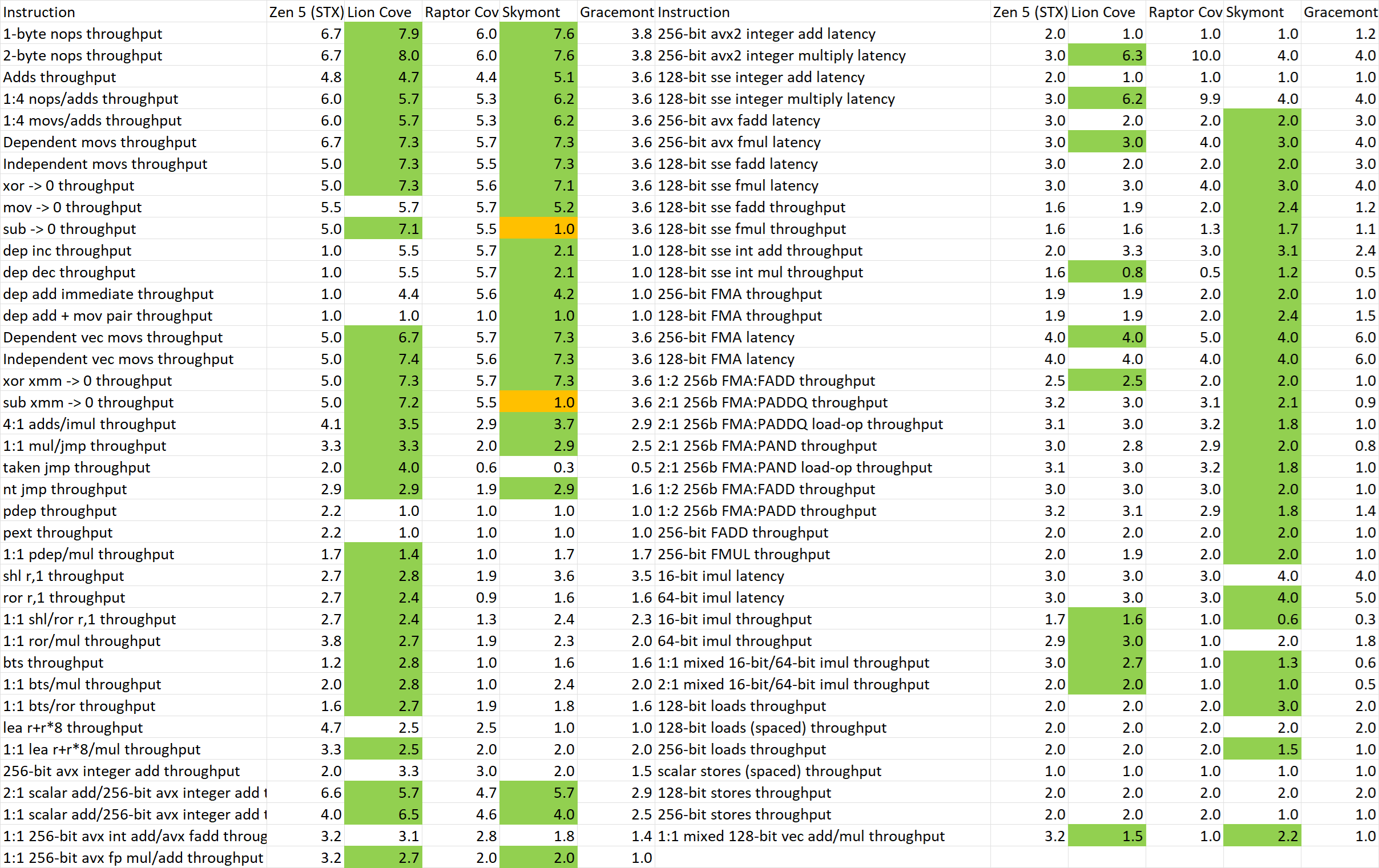
可以看到无论是Lion Cove还是Skymont在指令吞吐方面相比前代都有非常明显的提升。Lion Cove的提升注重于scalar指令的吞吐,Skymont的scalar与vector都有大幅度提升,不少指令组合的性能翻倍。Lion Cove与Zen 5相比,则是表现得各有千秋。
大/小核两种微架构都是8-wide级别,小核的一部分指令吞吐甚至超过大核。这也代表着,某些写的不太好、考察不太全面、不够现实世界的跑分软件极其容易出现大小核IPC倒挂的现象。例如PC DIY圈子常用的CPU-Z就会受到小核128bit SSE fadd/fmul同频性能显著超过大核的影响,导致小核跑出特别搞笑的分数。当然了,正如我一直以来所说的那般,CPU-Z自古以来就是个搞笑跑分。如果看到有谁做评测带CPU-Z分数还把它的性能一本正经分析一通而不理解CPU-Z本质上是在跑毫无意义的垃圾指令,基本就可以关掉这个评测不看了,没什么参考价值。
取指令
与AMD Zen 5相同的是,Intel在Lion Cove / Skymont也正式迈入8-wide微架构的时代。不过与AMD那种取巧的方式不同,Intel保质保量地为大核都实现了单周期解码不低于8条x86指令的能力,小核虽然略有局限性但也整体好于单线程的Zen 5。
我们测试Lion Cove / Skymont在不同指令长度下的取指带宽,以IPC的形式展现,并与Raptor Cove / Gracemont组合以及Zen 5进行对比。指令长度为4的对比图里,也加入了最新的ARM Cortex-X4与A720。
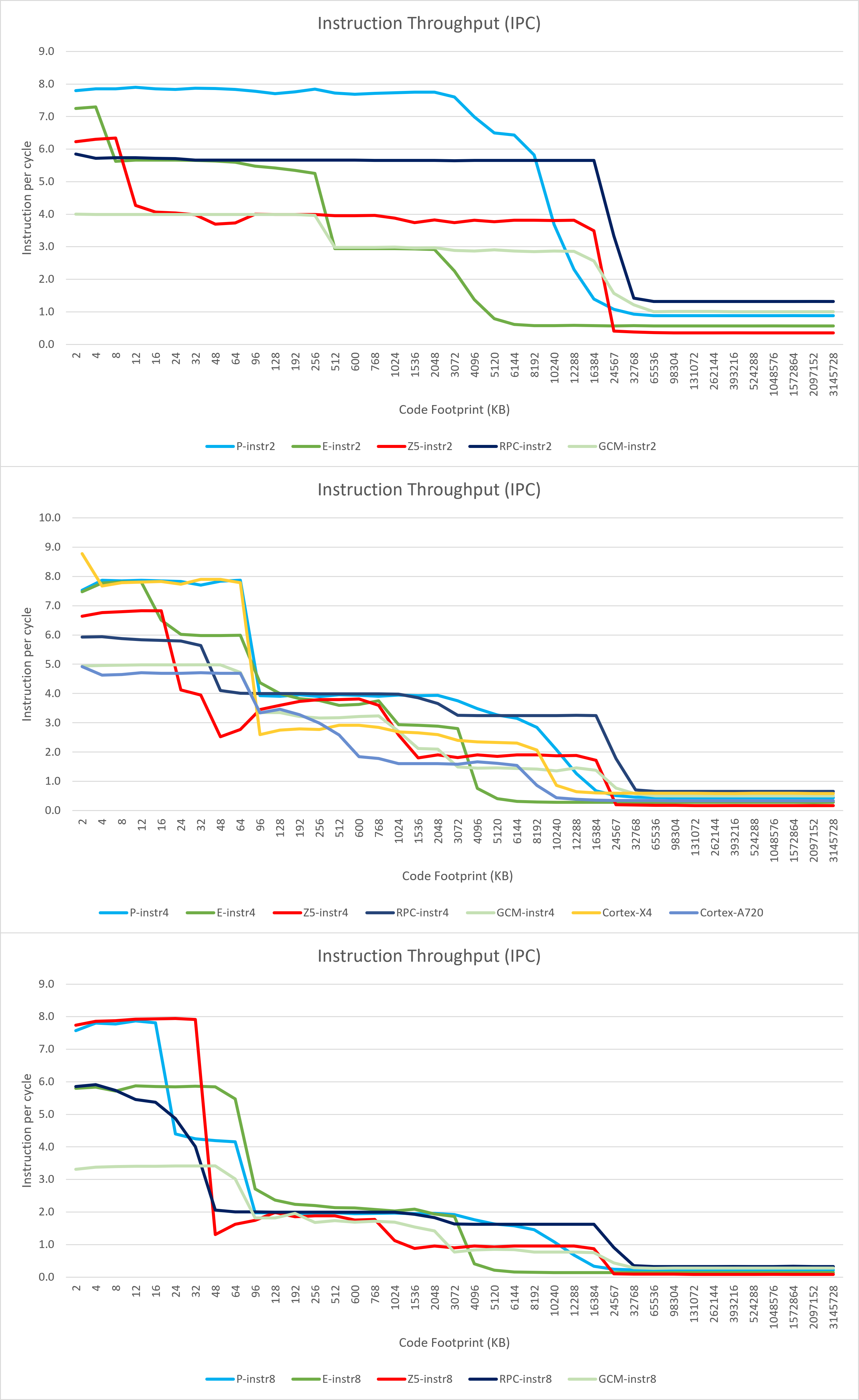
从测试中我们可以看出,Lion Cove具有当之无愧的本代最强x86取指令/解码能力:
- 整体与Raptor Cove表现较为相似,不过在规模方面有所增强(6 wide -> 8 wide);
- 解码较短指令时可以在整个L2区域内实现每周期解码8条指令,甚至超出L2也依然有很高的吞吐;
- 从不同指令长度在L2区域的IPC可以看出,L2到L1i的带宽为16B/cycle;
- 对于较长的指令(例如8字节),超出op cache容量之后的指令吞吐能力会受到L1i取指带宽的限制,而非指令数量限制;
- 同样4字节指令的情况下,Lion Cove的指令吞吐能力不亚于ARM最新的Cortex-X4,这对x86处理器来说是极其难得的一件事情。
作为对比,虽然Skymont的模块化前端具有3×3的解码能力且具备单线程使用所有解码器的能力:
- Skymont仅在非常小的范围内达到每周期8条指令的理论吞吐,超出后IPC迅速下降到6;
- 全L1i内取指令的带宽至少为48B/cycle,L2到L1i的带宽为同样的16B/cycle;
- Pre-decode cache可以缓存大约192K条指令的边界,并且这些指令并不一定需要存放在L1i中,只是L2到L1i的取指令带宽受限使得只有部分情况下能观察到超过3的IPC;
- 这些表现与Gracemont整体相近,表现出非常大的局限性。意味着虽然理论发射宽度达到了5/8-wide,实际由于指令的长度/排布等影响,最大IPC有大打折扣的可能;
- 同样4字节指令的情况下,Skymont的指令吞吐能力显著优于ARM最新的Cortex-A720,这使得其作为一个中核在指令吞吐方面的性能高于ARM的方案。
总的来说,Lion Cove是传统的作派,设计一个较长流水线的monolithic decoder,使用op cache缓解前端的延迟并节省功耗;Skymont延续Gracemont/Crestmont的思路使用模块化解码器提高指令吞吐,使用Pre-decode cache替代op cache实现单线程利用多个解码器模块;AMD的Zen 5则维持单线程4宽x86解码并继续扩展与优化op cache,将双前端设计用于优化SMT性能,单线程的microbenchmark数字略显逊色。
当然,单纯地从顺序取指令的吞吐这个角度并不能评价处理器的实际应用性能。正如我上一篇Zen 5评测里讲到,单线程环境里大部分场景的op cache命中率都是极高的水平。但Lion Cove如此强大解码能力的出现,足以让数码圈子里的很多ARM一派armchair分析师所谓的类似“x86微架构的IPC不如ARM是因为变长指令的解码宽度不够”的论调不攻自破。在2024年,如果说AMD Zen 5架构在指令吞吐方面依然还有所争议,Intel则是毫无疑问地彻底解决了这一问题,使得ARM架构的指令吞吐优势彻底化为虚无。
分支预测
高吞吐的前端需要优秀的分支预测来使其得到充分发挥,现实世界里的很多应用都对前端的延迟非常敏感。接下来我们测试Lion Cove、Skymont与分支预测相关的一些结构,观察前端的综合延迟表现,并与前代Raptor Cove、Gracemont,同代竞品Zen 5等微架构进行简单对比。
BTB测试
大核
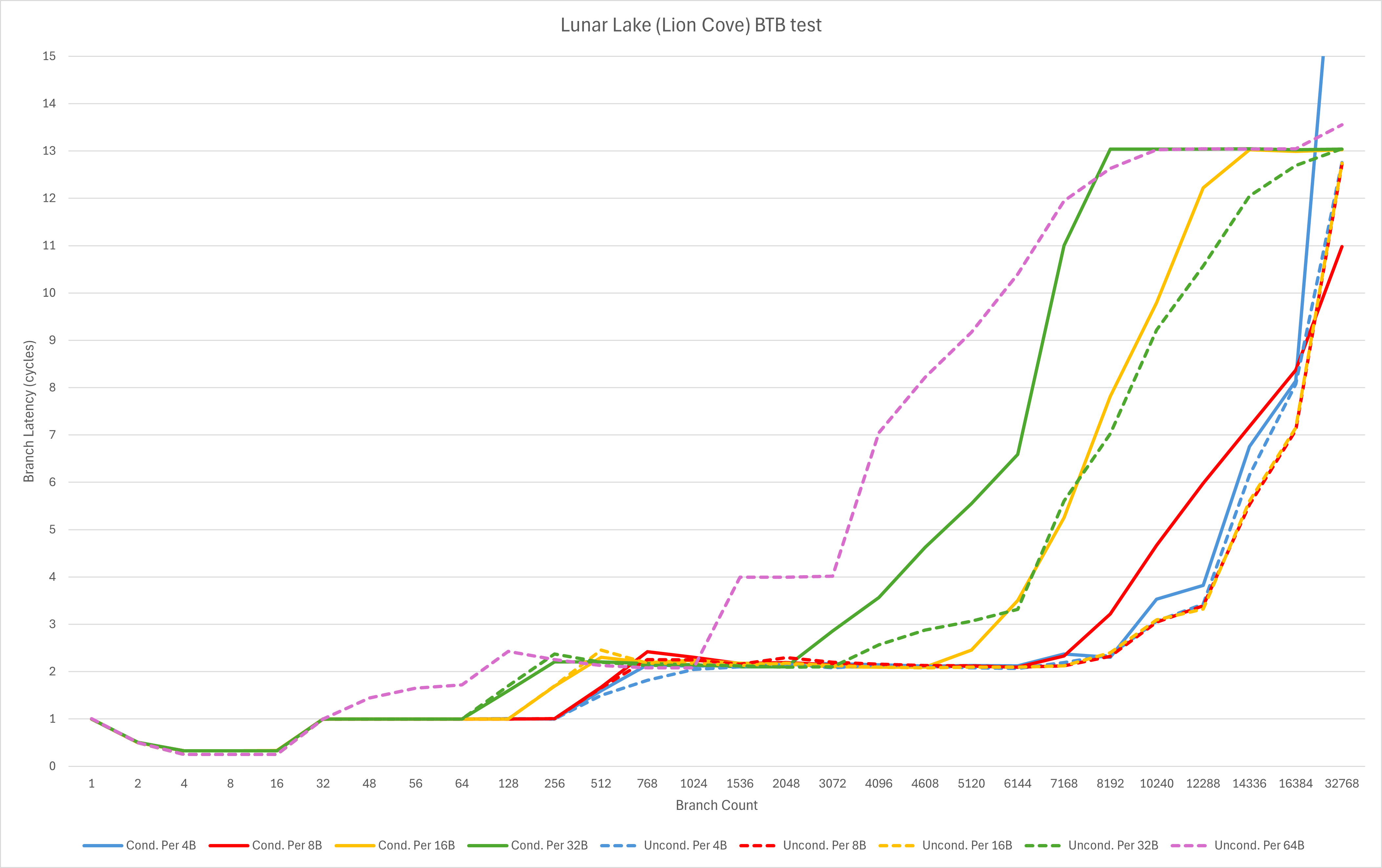
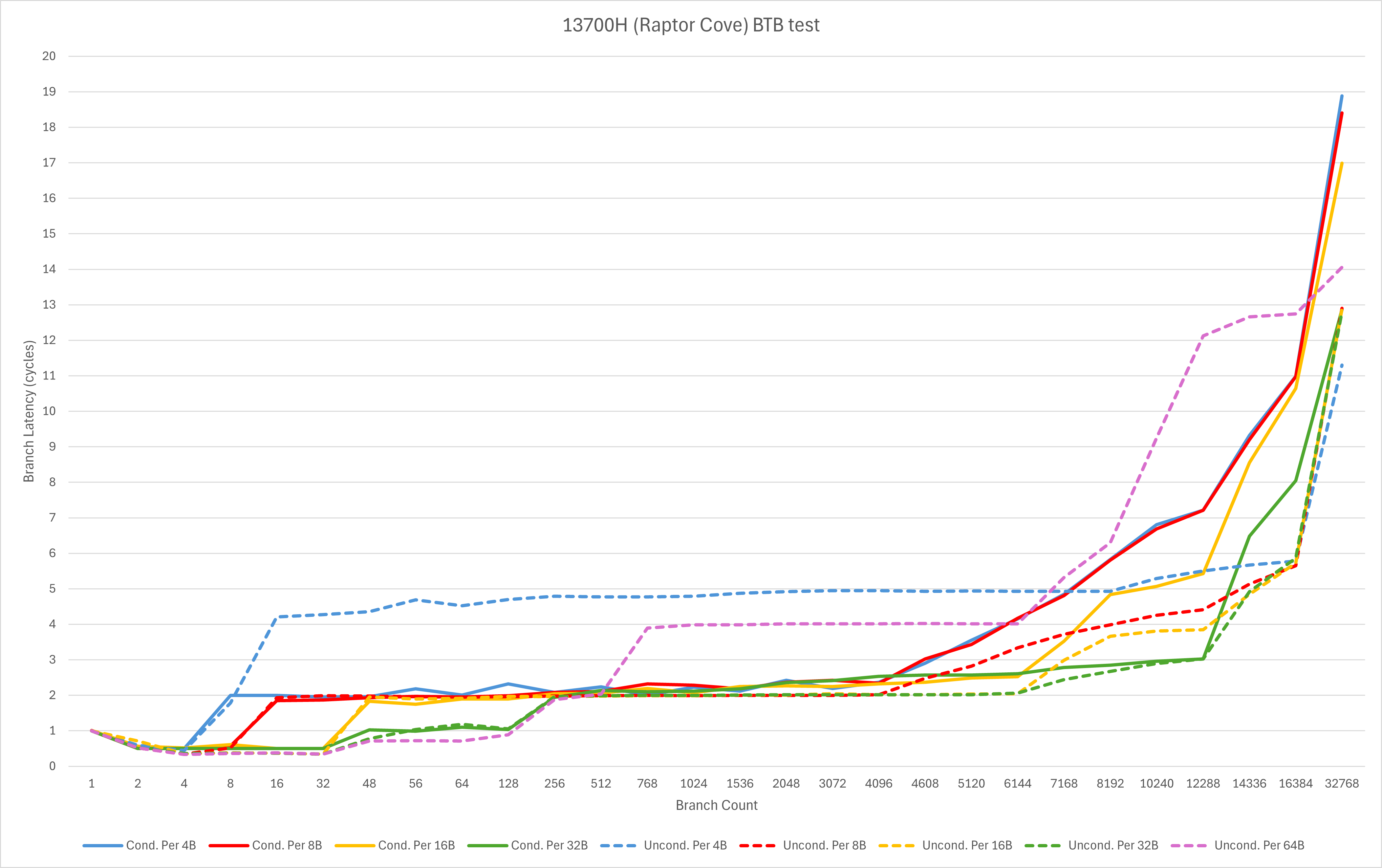
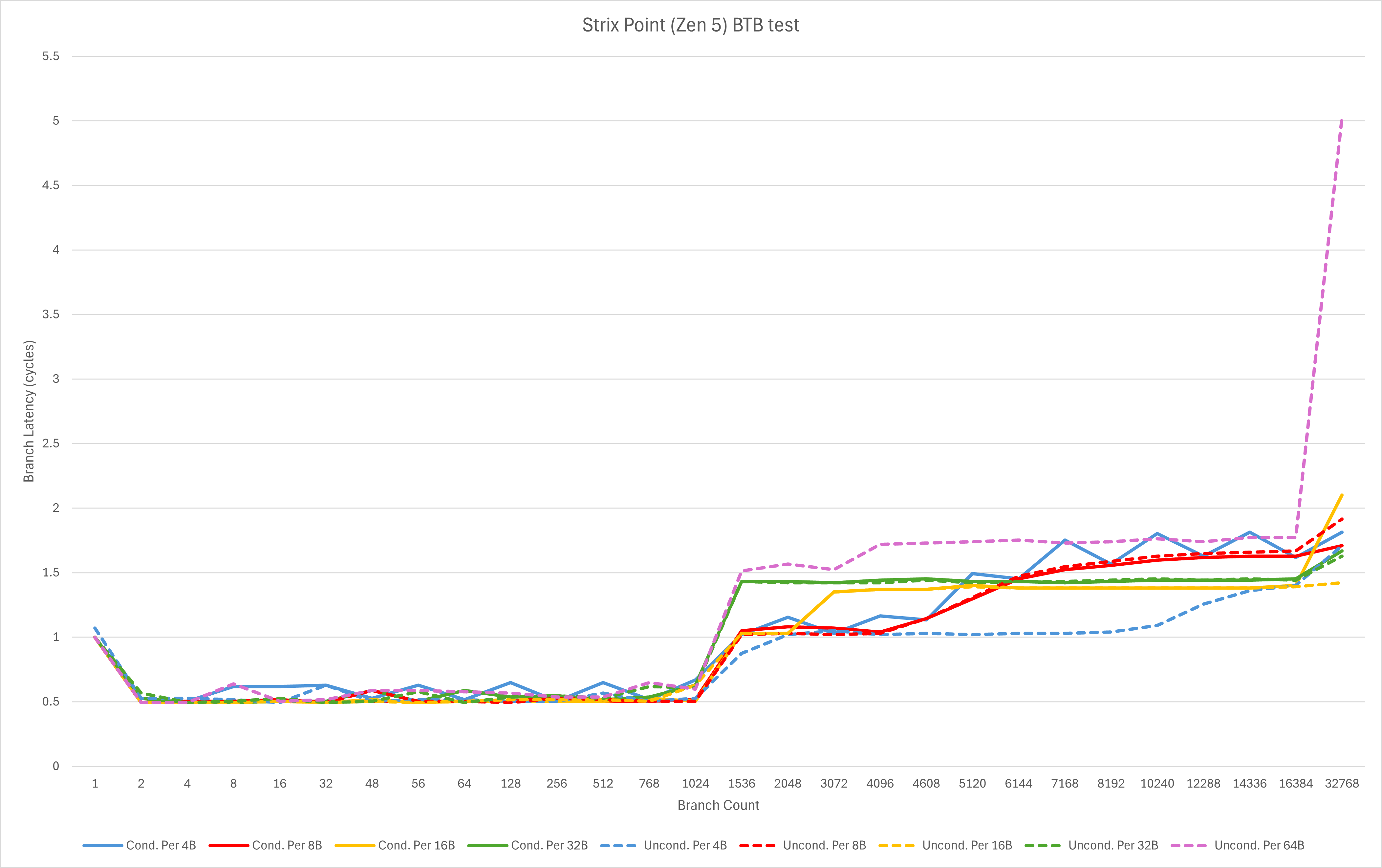
从Lion Cove与Raptor Cove的对比中,我们可以观察到
- Lion Cove在32分支以内可以单周期执行最多3-4个taken branch,而Raptor Cove为2-3个。这代表着Lion Cove的loop buffer获得了进一步的增强,但是容量疑似略有缩减;
- L0 BTB的覆盖范围和容量都有较明显的提升,尤其是对于分支密度较高的场景,但分支较为稀疏的部分场景的等效容量有所下降;
- L1/L2 BTB的最大等效容量没有发生特别明显的改动,但是不同test pattern下的表现发生了较大的变化。这里推测实际容量发生下降,但通过一些简单压缩来实现部分场景等效容量维持不变。
与Zen 5相比,我们可以观察到
- 看不见尾灯了
本代Intel核心在分支预测上的改动,很明显并不完全是奔着性能去。即便使用了远比Intel 10nm (Intel 7)或者7nm (Intel 4/3)更先进的TSMC N3B工艺,他们也没有进一步加大规模,而是在现有规模下进行调整。
个人猜测,这样的调整背后可能是为了更好的能效,毕竟Intel过去几年在这方面一直饱受诟病。而尽管I系御用KOL和某些市场部门的员工在互联网上嘴硬不承认,从我私底下与研发人员的交谈看,Intel自己却是非常希望可以大幅度改进能效一雪前耻的。
小核
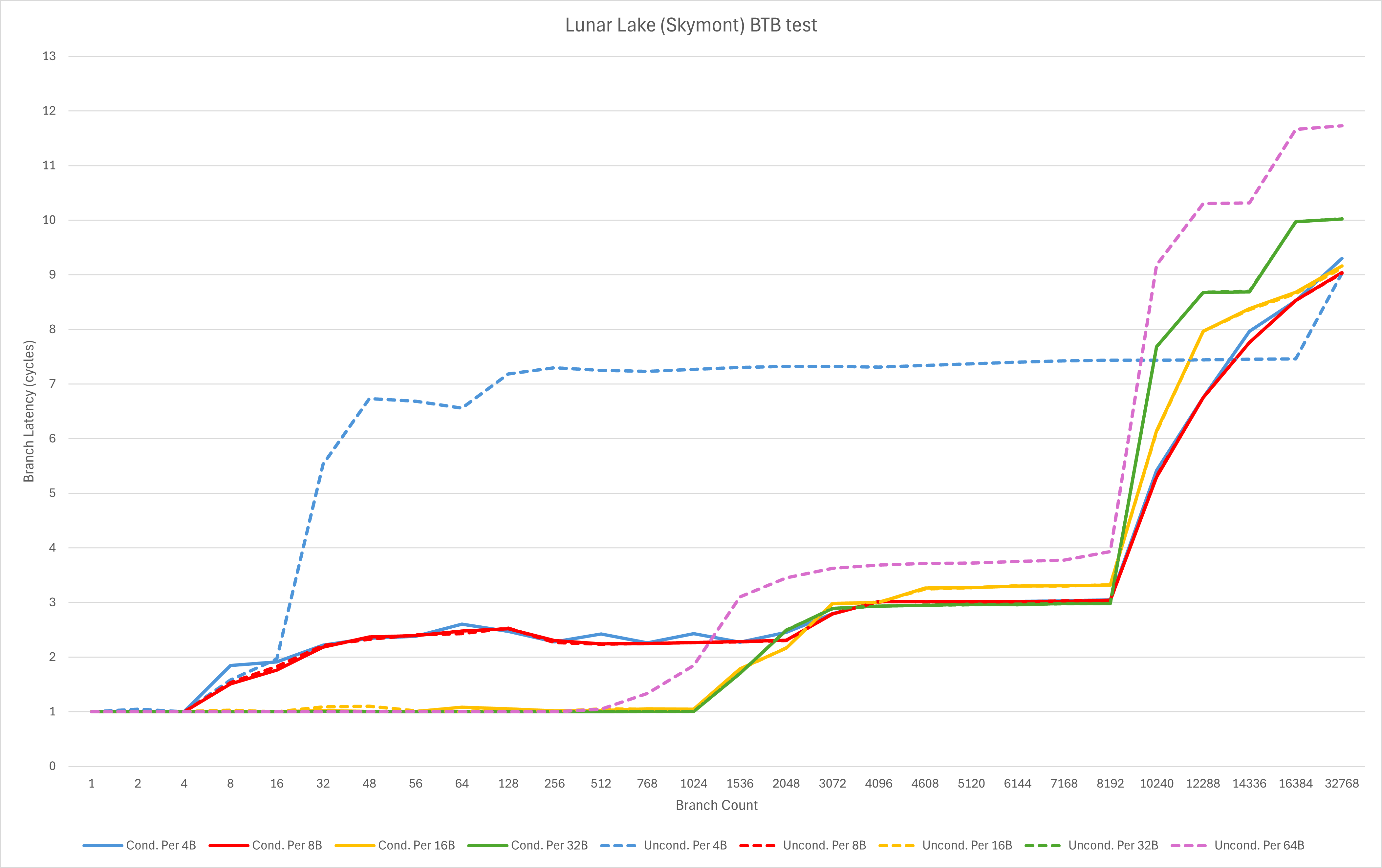
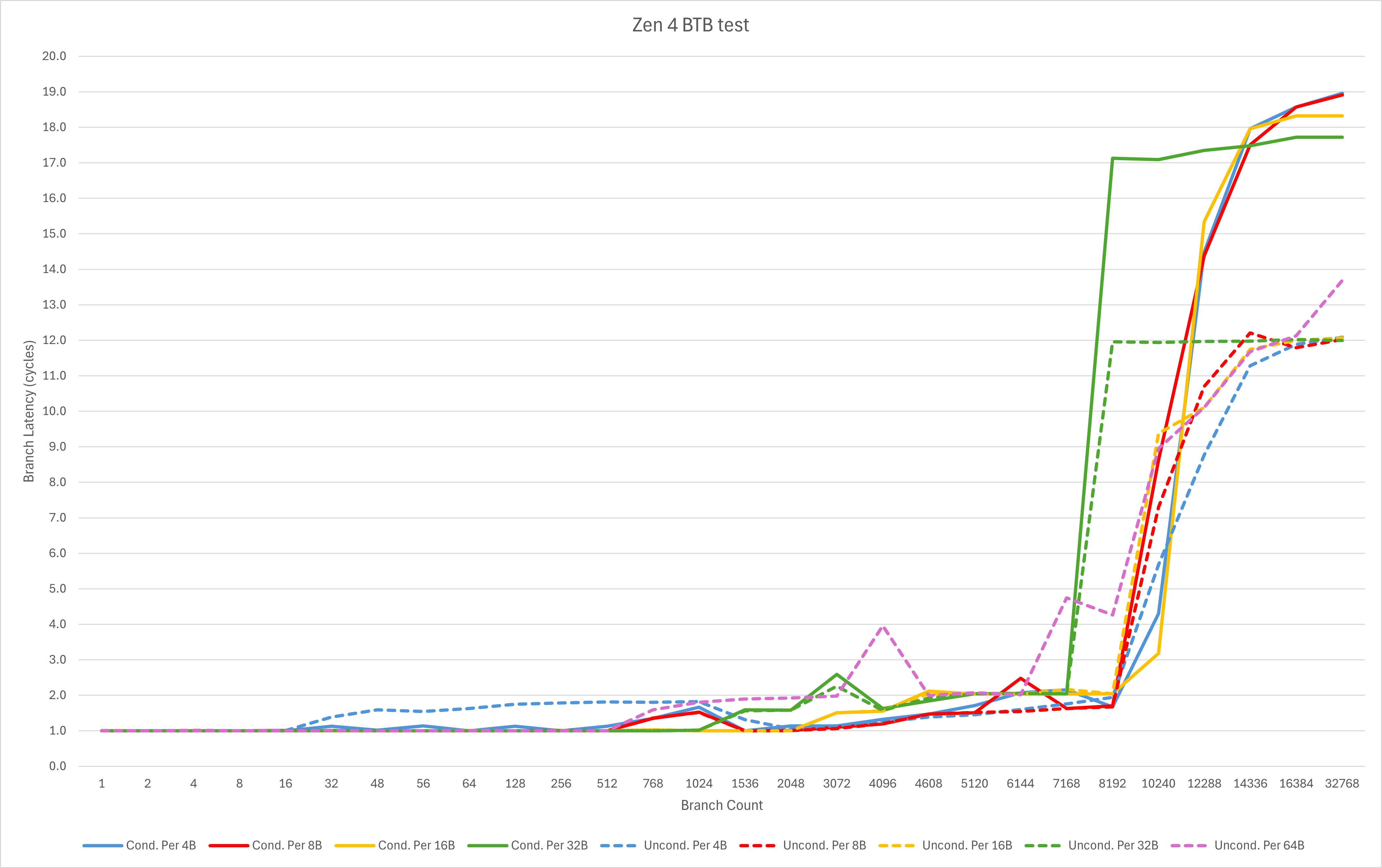
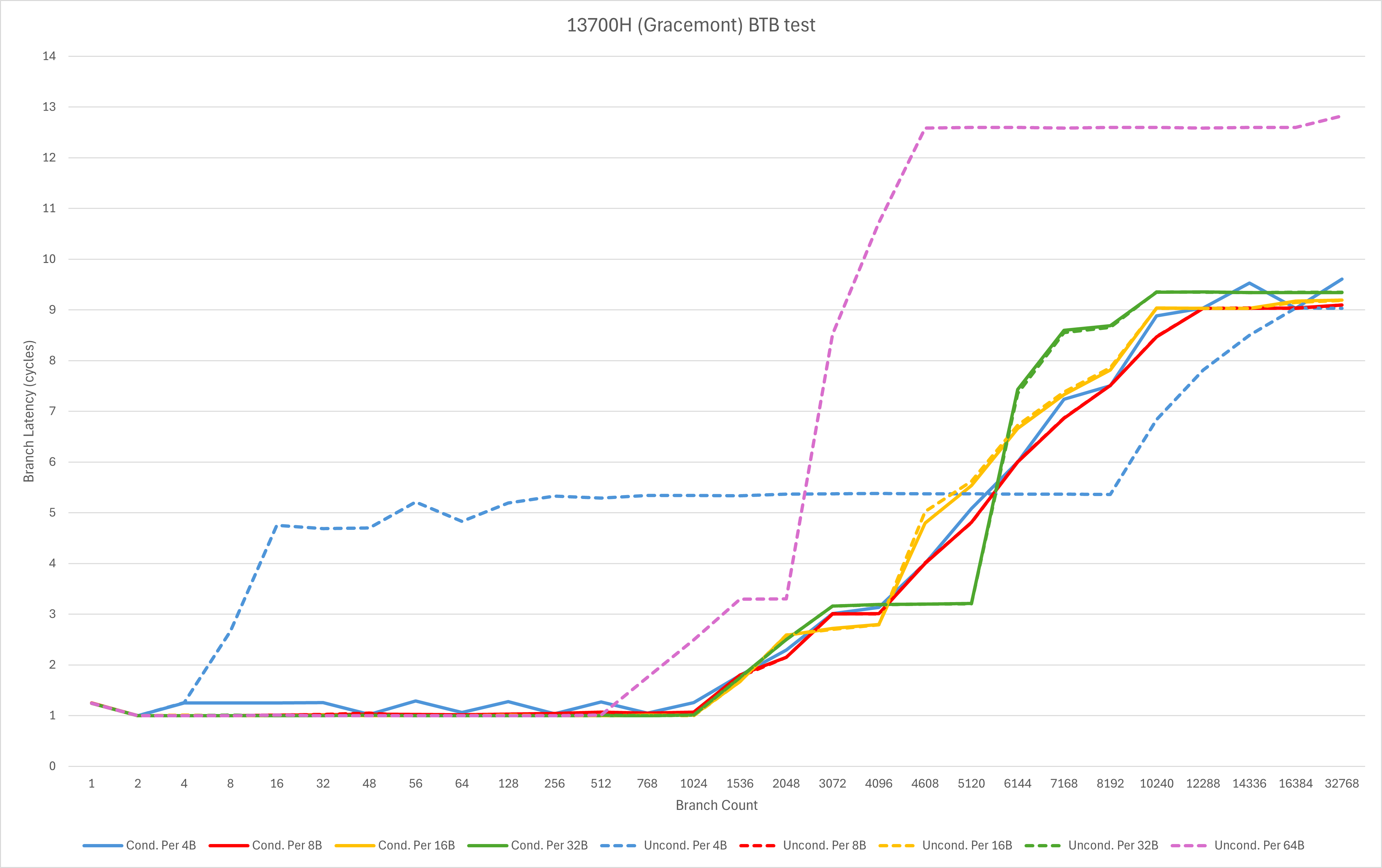
小核组这边的状况比大核要好得多。由于规格相近,为了方便直观的对比,我把AMD的Zen 4核心也加入了这一组(希望AMD粉丝们不要把我挂到贴吧黑三天三夜)
- 可以看到小核与大核比起来,对极其密集无条件跳转的处理能力依然比较差。不过在现实世界中这种情况本身较少,作为一个小核心,在这种边边角角的地方作裁剪可以理解;
- 借助这个测试,我们可以观测到decoder override的延迟,从大约5个周期上升到了7个周期。
这代表着Skymont的前端取指与解码的延迟周期数相比Gracemont显著变高,这可能是为了更低的SRAM设计压力、更低的电压、高负载下更好的能效,以及更好的极限频率、极限性能这些目的中的一个或多个。同时增长的流水线长度这也体现了Atom团队对于分支预测准确度的信心。
- 借助这个测试,我们可以观测到decoder override的延迟,从大约5个周期上升到了7个周期。
- L1 BTB依然为1024条,并且对于密集分支的处理能力相比Gracemont有所调整,密集分支的处理延迟上升一个周期左右;
- L2 BTB从5K增加到8K,达到了Zen 4级别。分支类型和密度的覆盖相比Zen 4和Gracemont有较大的优势,但是延迟依然维持了Gracemont的3周期,比Zen 4略高1周期。
从BTB的角度看,Skymont确实做到了上一代x86大核心(Zen 4)的级别。
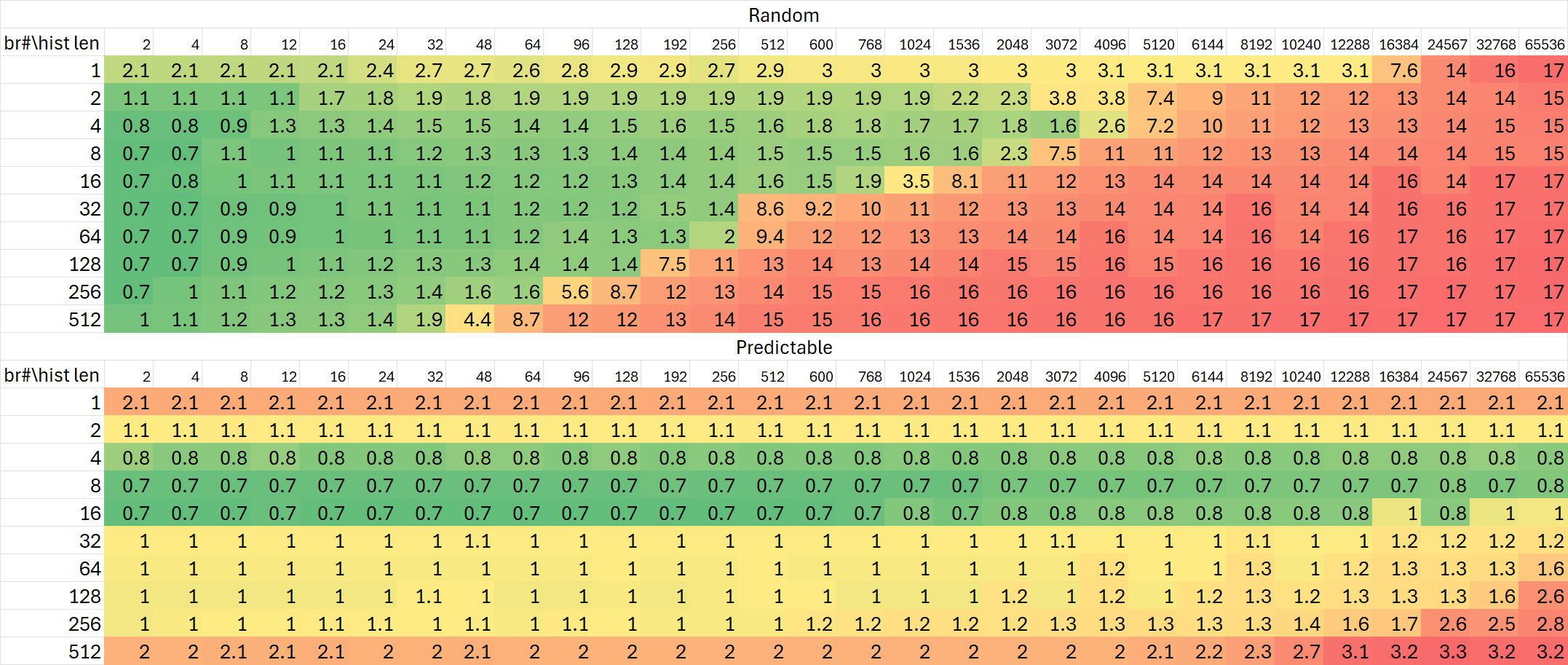
分支历史追踪能力
Lion Cove
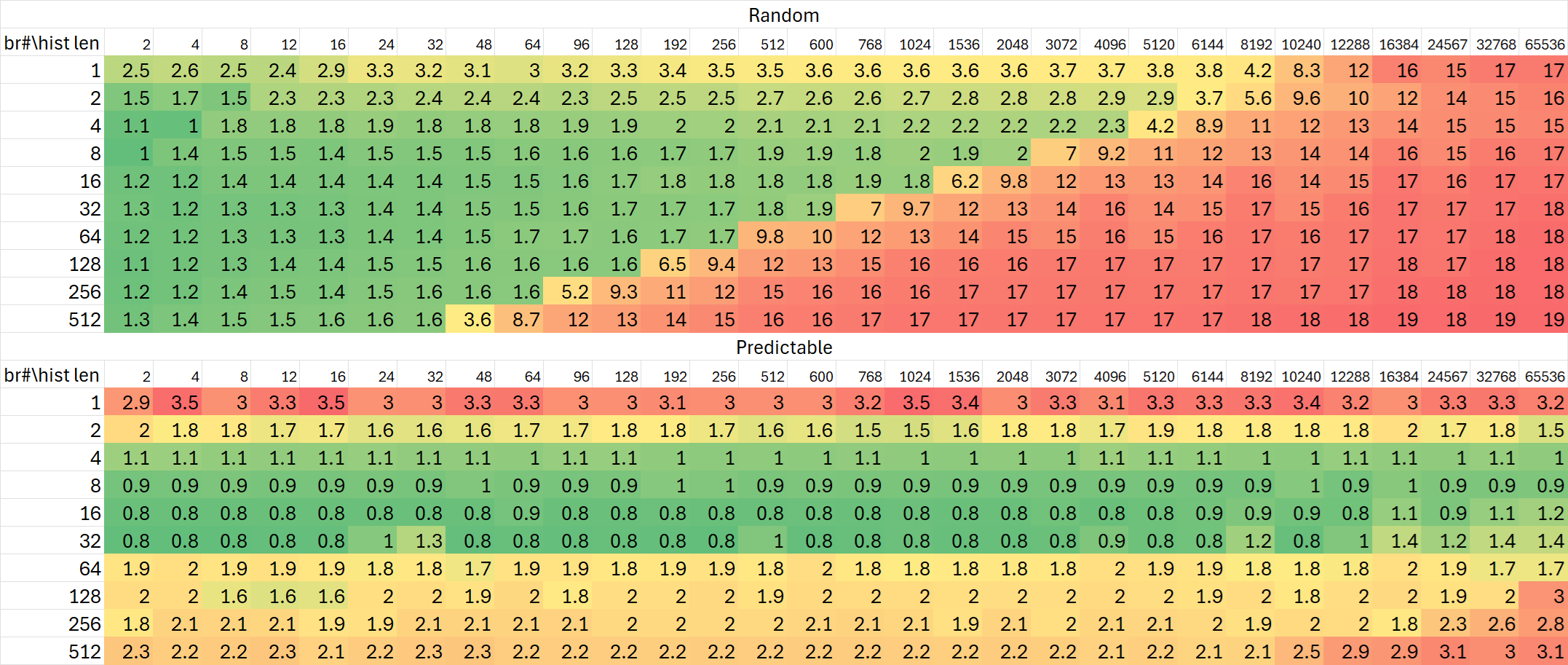
Raptor Cove
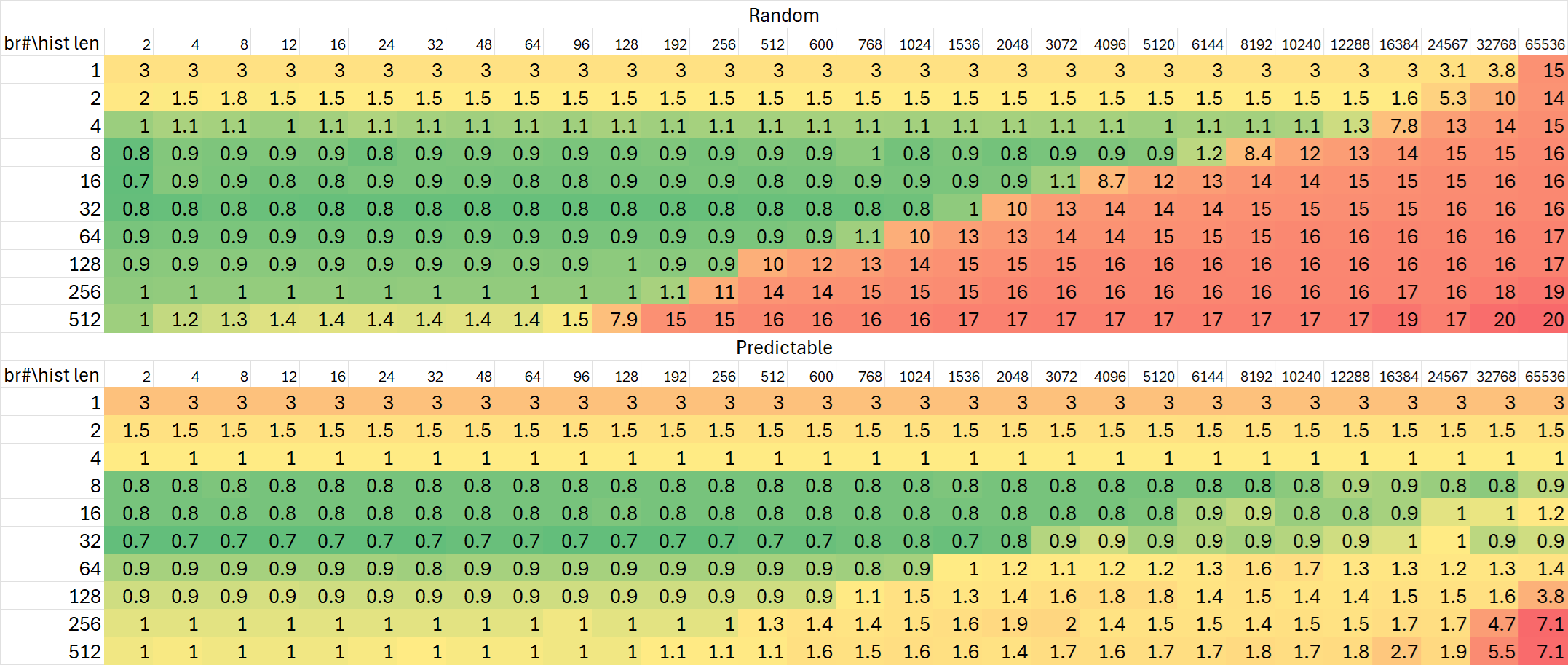
Zen 5
Skymont
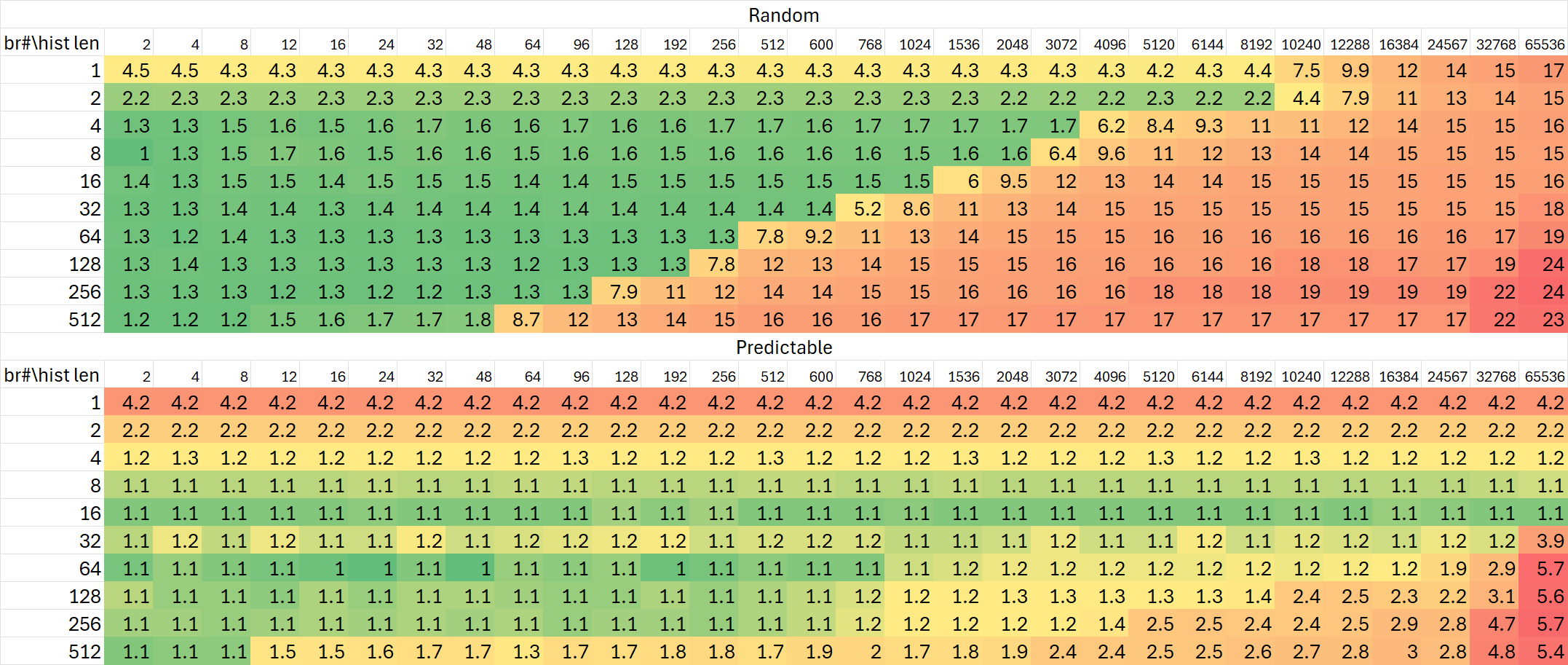
Gracemont
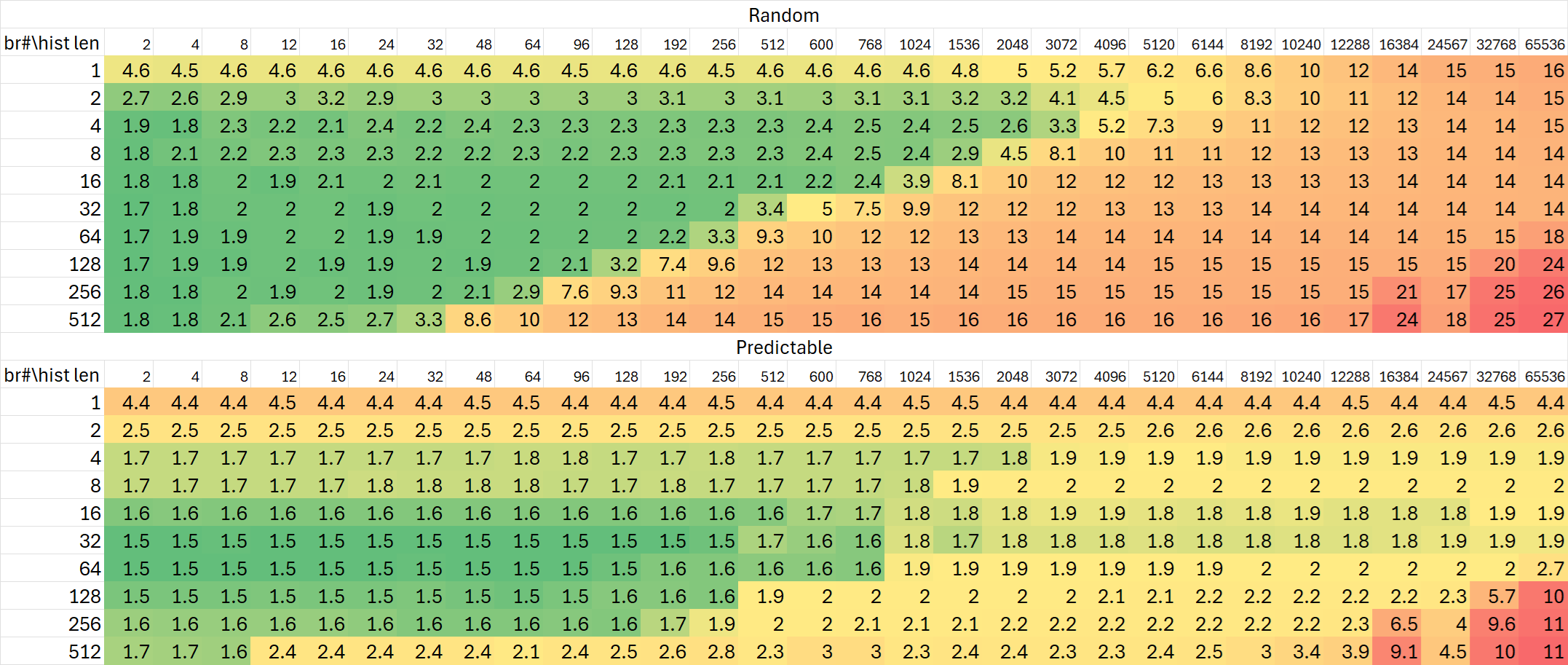
可以看出,Lion Cove对于分支历史的追踪能力并没有非常显著的提升,与Raptor Cove基本相同;但Skymont再次在这项测试里展现出极大的提升——规模增加到24K分支历史,相比Gracemont与Raptor Cove高出50%。
当然,前面BTB测试里观察到的Skymont流水线的加长也能从这项测试里体现出来。但同时有趣的是Lion Cove的流水线却缩短了。大小核心双向奔赴,左右互搏?
从上述这些测试中,我们可以看到Lion Cove对分支预测相关结构的规模改动比较保守,部分测试里相比Raptor Cove甚至出现了一些倒退;而Skymont相比Gracemont大幅度增加了相关结构。这一点在后续的实际测试数据中也能得到较好的体现。
与AMD Zen 5那令人感到惊讶的分支预测规格相比,Intel的改动则是平平无奇的一代。
实测分支预测准确度:喜忧参半
由于进行测试时最新的Linux内核对Lunar Lake的支持依然比较初级,我们只能收集一些最基本的数据。好在分支预测准确度相关的PMC可以采集,我们收集这些计数器在不同微架构之间作出横比。
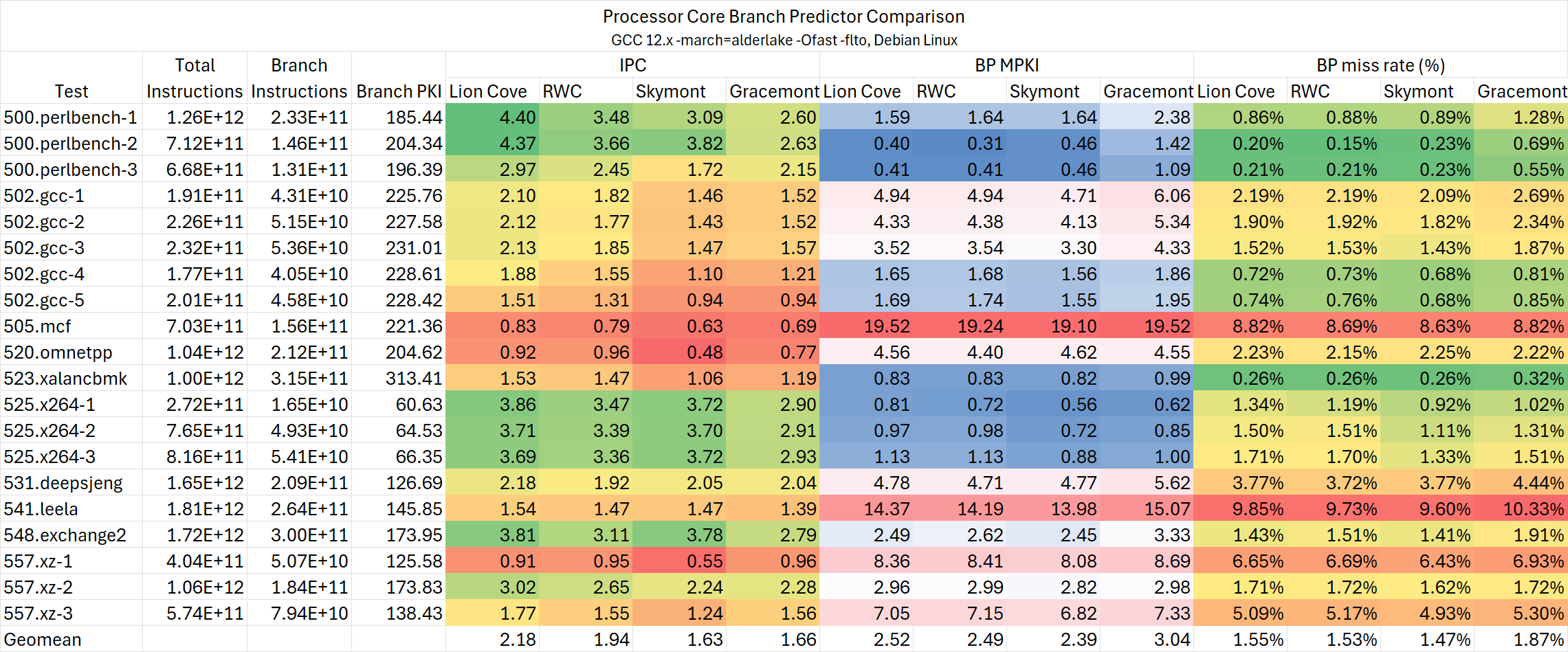
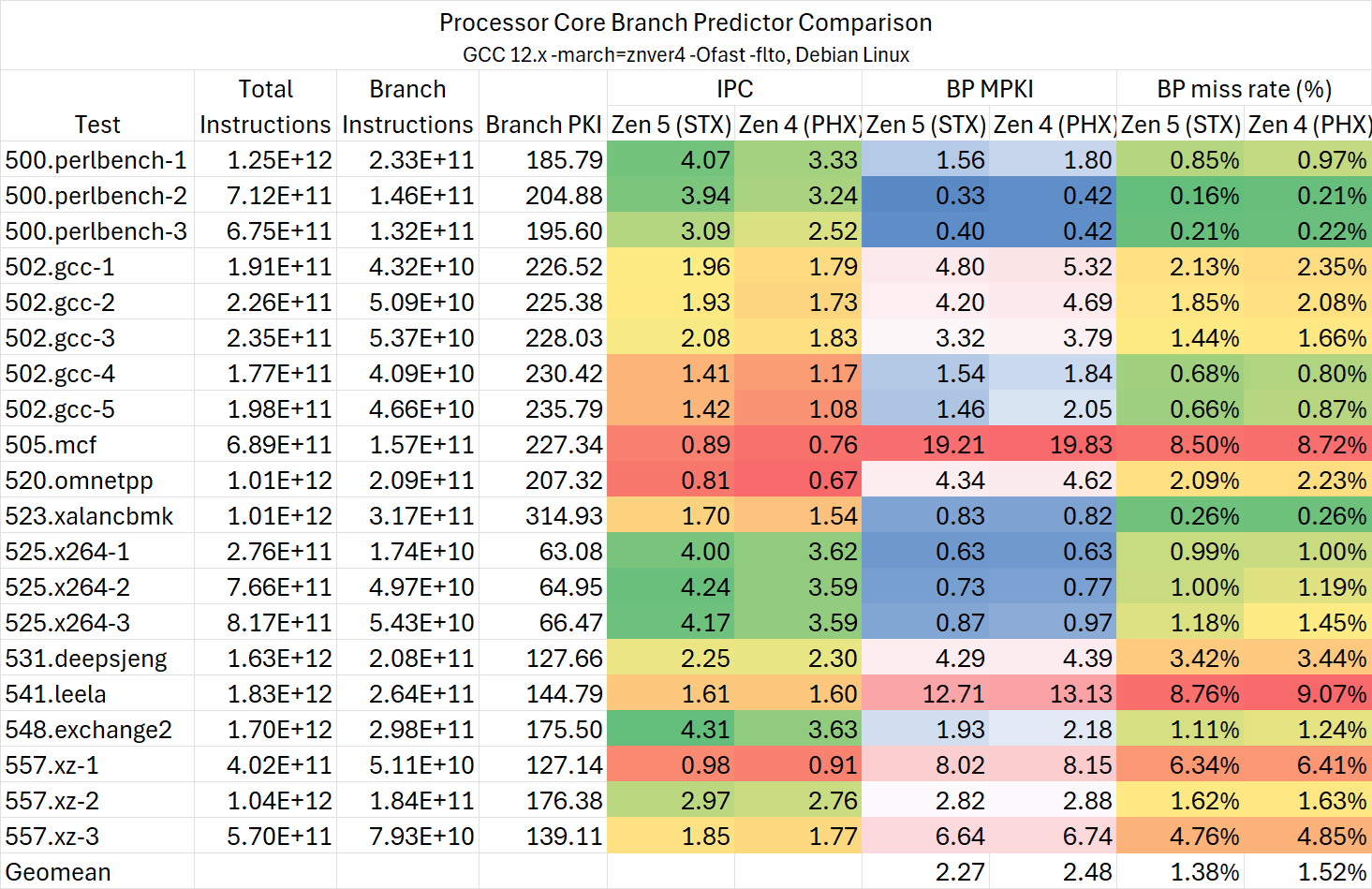
根据上述实测数据可以作出一些总结
- Lion Cove的分支预测准确度相比Redwood Cove略有下降,后者与Zen 4的水平接近;
- Skymont的分支预测准确度获得巨大的改进,超越Lion Cove/Redwood Cove/Zen 4;
- Zen 5的分支预测准确度依然稳坐头把交椅。
当我最初看到这个测试数据时,我整个人都是震惊的,并且是对于大、小核分别震惊一次。
很难想象Lion Cove在Golden Cove发布之后的3年间在分支预测这个对CPU来说最为重要的方面不仅没有任何的提升,反而还有倒退。虽然从前面的分支预测相关测试可以看出Lion Cove在这方面的调整并不完全是为了性能,但面对规模小得多的Zen 4与Skymont时依旧力不从心,让人有些开始怀疑Intel的大核团队到底还有没有人有能力在这方面作出改动。
另一方面,Skymont却又向我们展现了Intel出色的微架构迭代能力。在Gracemont发布的3年之后,仅靠与Zen 4相近的BTB规格便做到超越Zen 4的分支预测准确度。考虑到前文所述Atom微架构发展的种种趋势,我认为Atom在本代至少在某些方面已经展现出成为主力大核微架构的潜质。
不得不说在同一家公司内见到差距如此之大的两个团队,属实让人感到唏嘘。也许这就是Intel的特色吧。
内部结构
现代处理器内部为了实现更高的性能所设计的乱序执行结构众多,这里选取一部分比较关键的结构展示,以便直观感受这些微架构的规模与乱序执行能力。部分架构的测试在不太干净的系统环境进行,因此可能会有一些明显的波动,不过不影响大致结果。
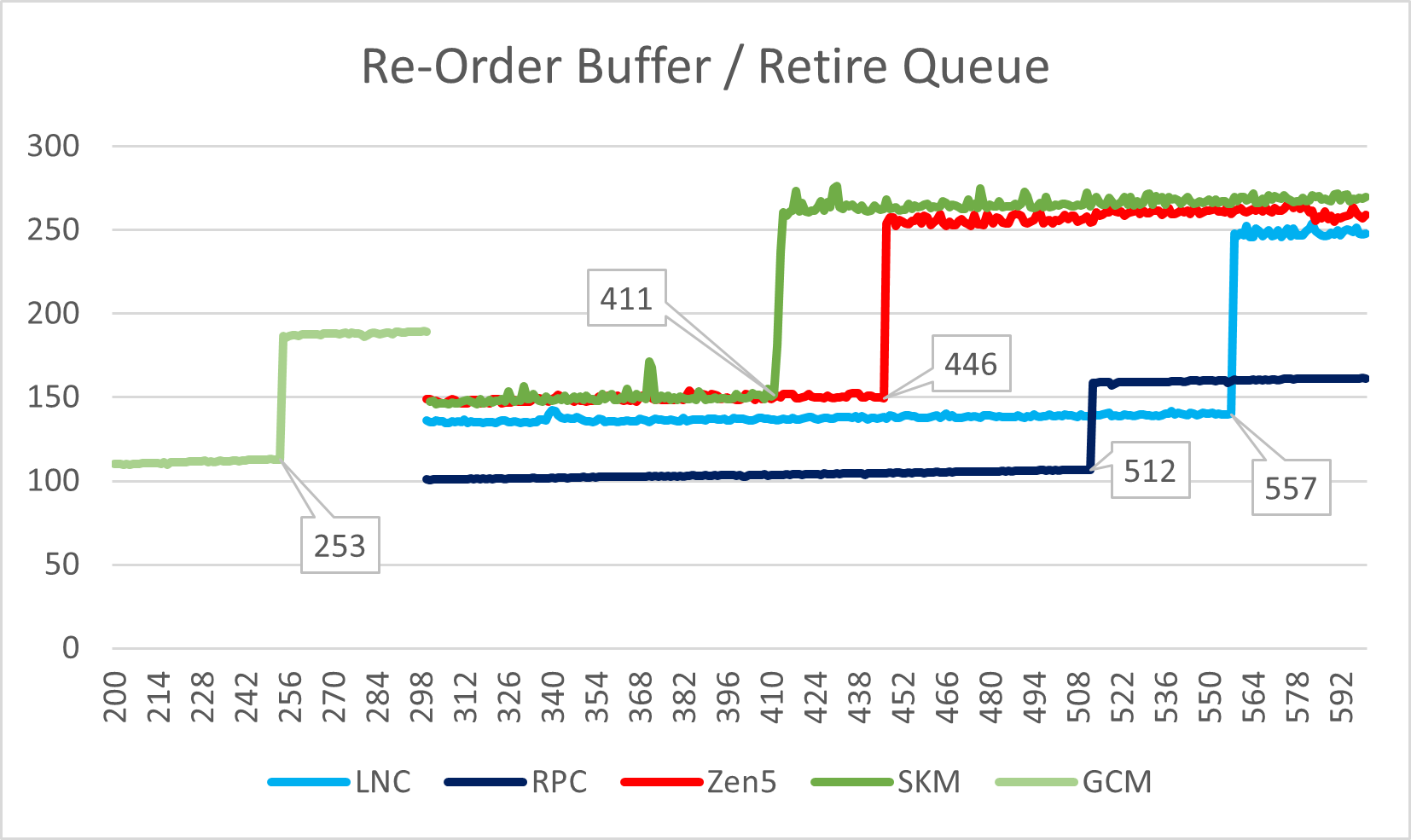
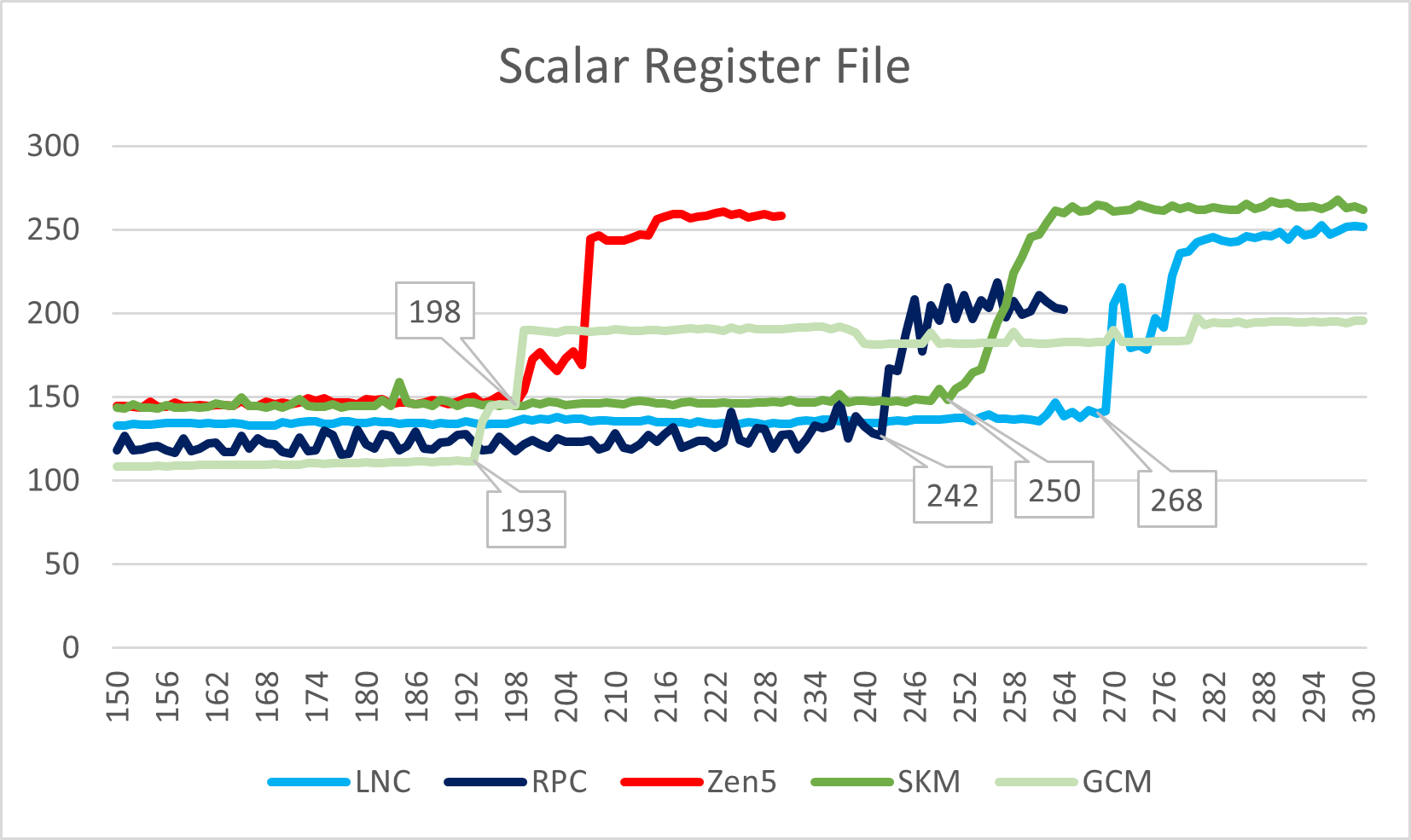
从上面两个测试中不难看出,Lion Cove进一步小幅度增加了ROB与整数寄存器的规格,而Skymont在这方面的规格已经增加到大核级别,接近甚至部分超越Zen 5。
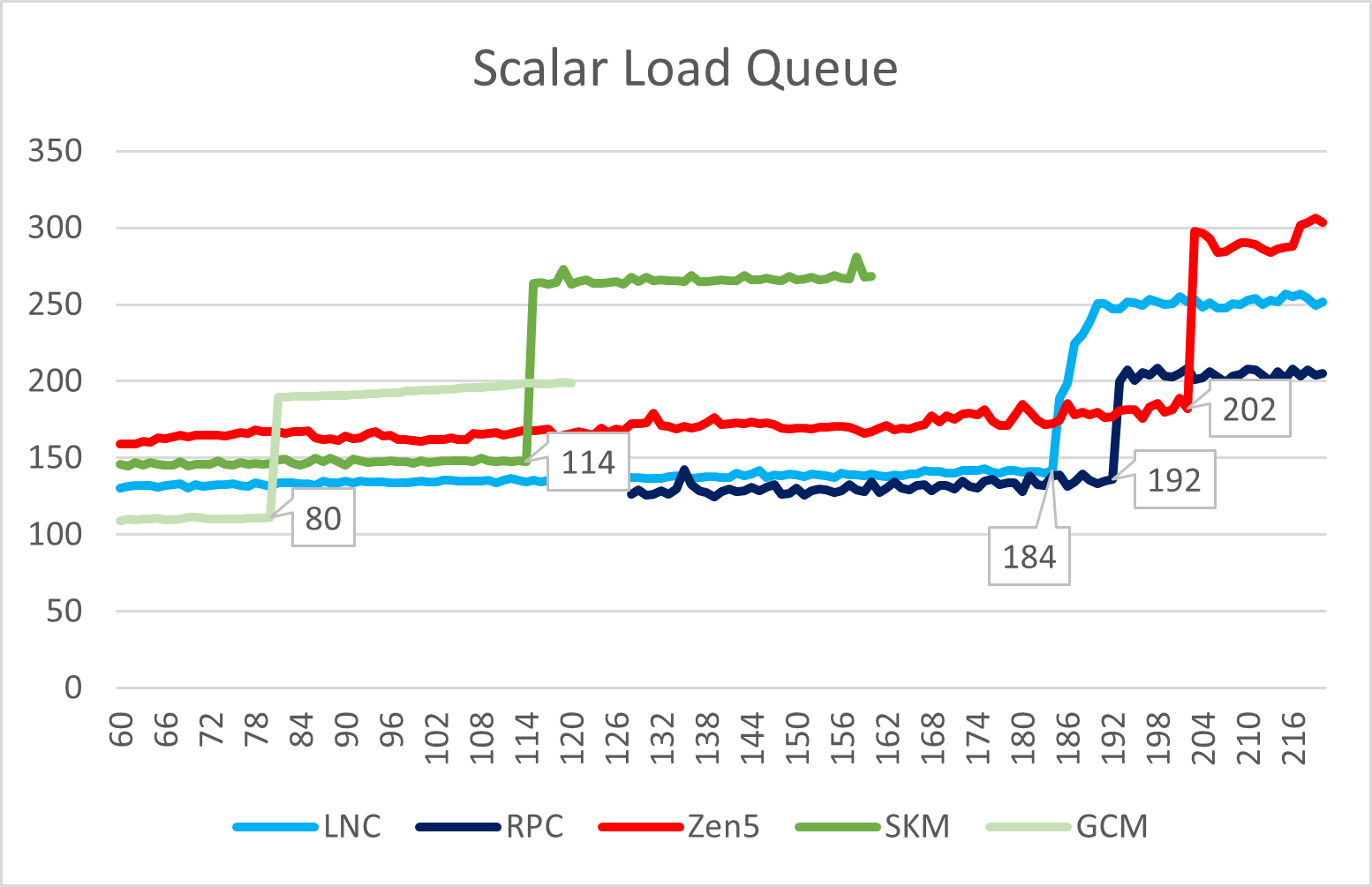
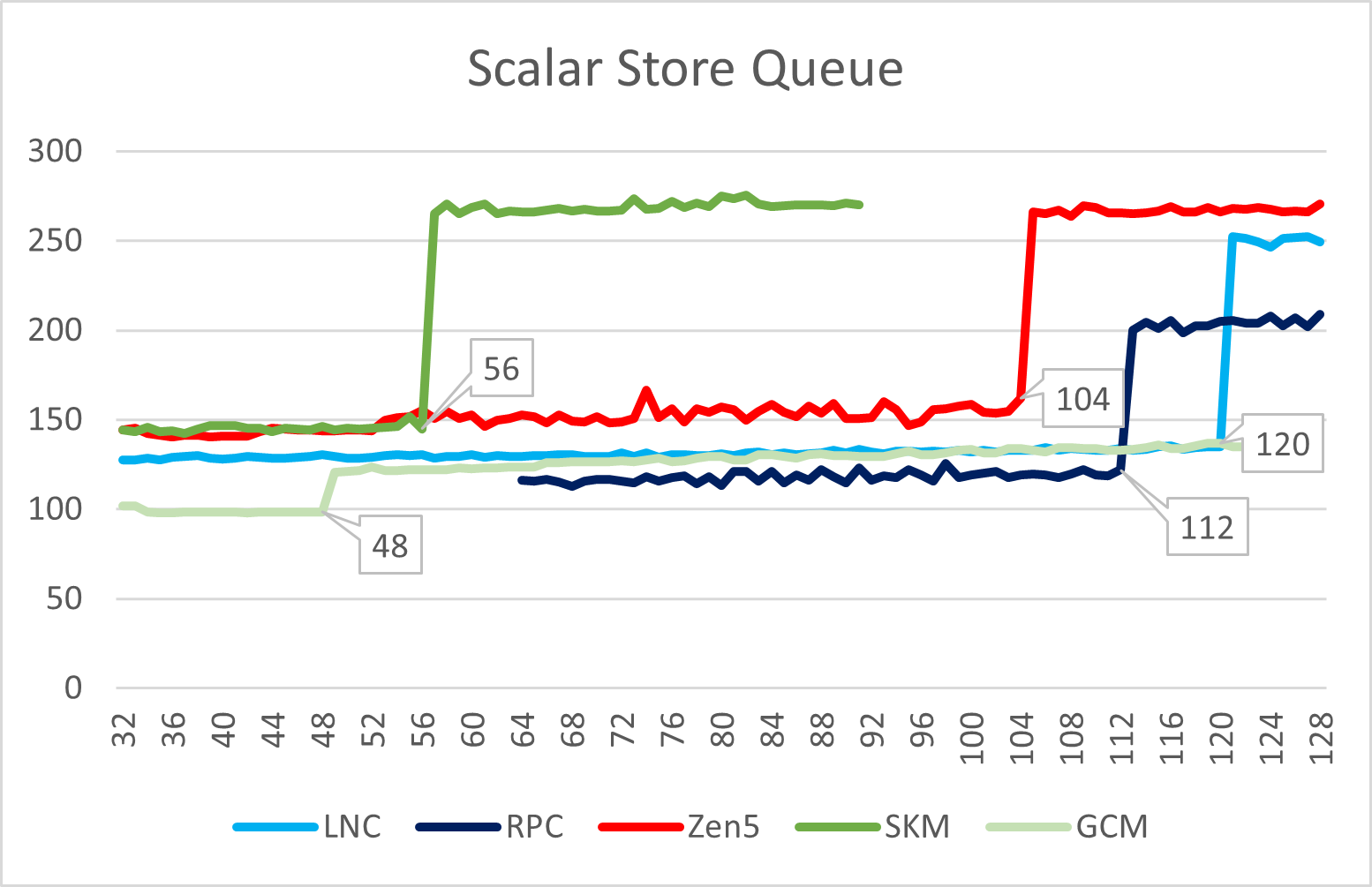
在Load/Store方面,Lion Cove的load queue略有缩减,而store queue略有提升;Skymont在这里则是暴露了自己仍然是一个小核心的本质,规模只是相比Gracemont略有提升,远小于大核。
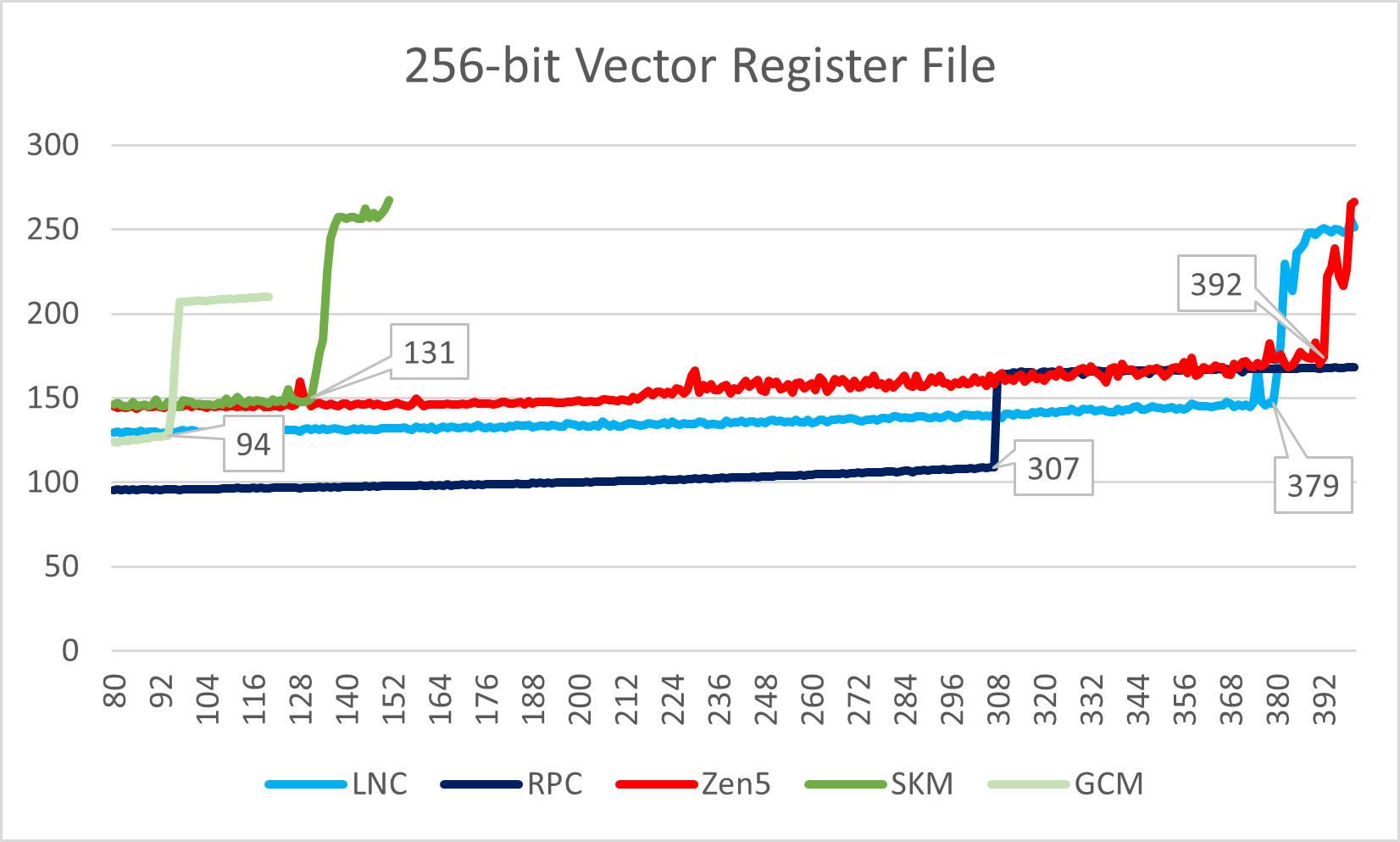
Lion Cove与Skymont在这里都迎来了非常大的提升,但本代向量寄存器容量被Zen 5夺得头筹。
向量寄存器是大/小核心差距最大的地方。这也不难理解,小核的设计目标是以标量/整数负载为主,AVX等指令集以维持软件兼容性为目的。此外,Skymont虽然加倍了向量吞吐,但它的原生向量寄存器位宽依然为128-bit,因此在执行128-bit向量代码时的等效寄存器容量时上述测试里的两倍;而原生256-bit向量寄存器的大核则不会有这种变化。
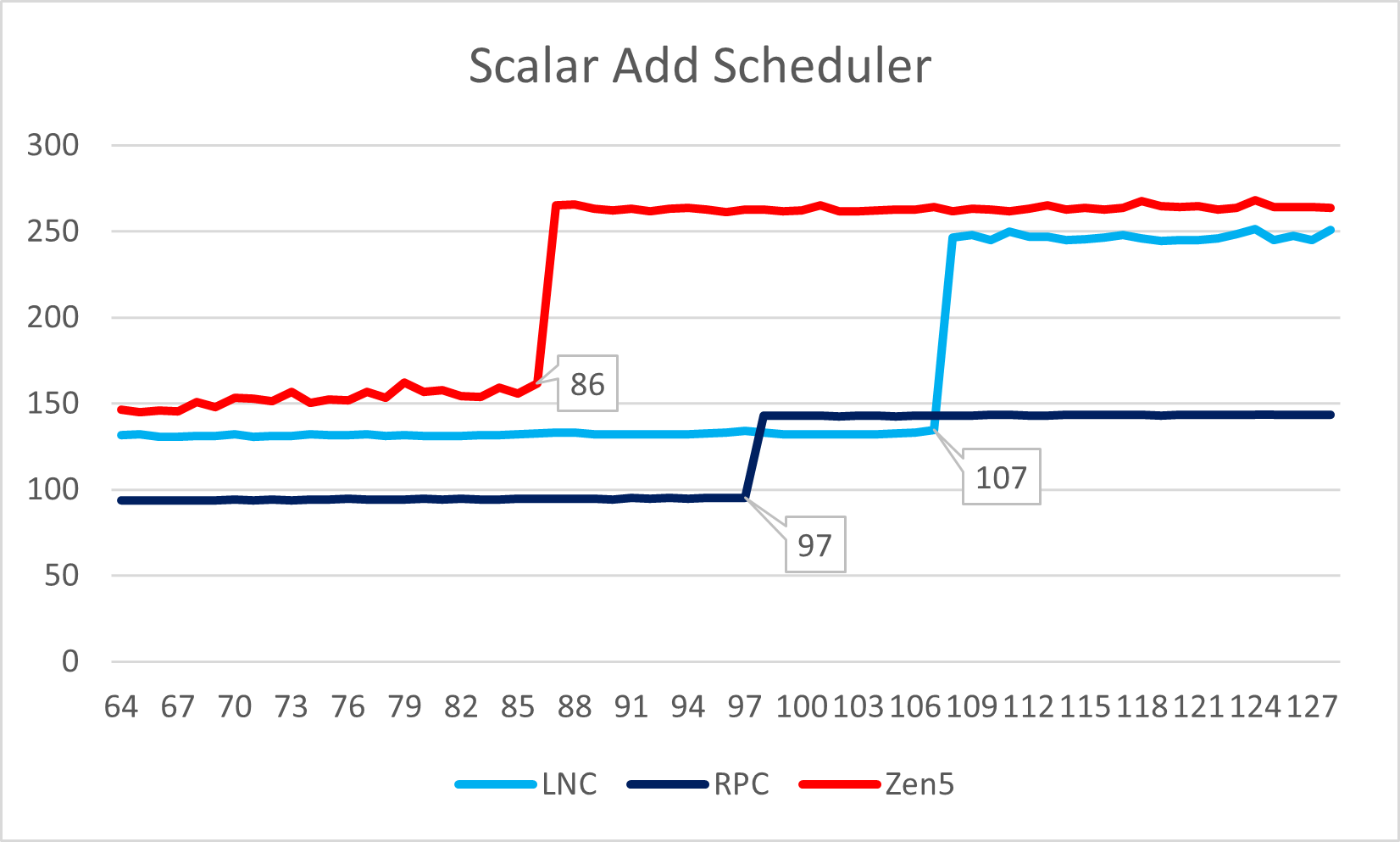
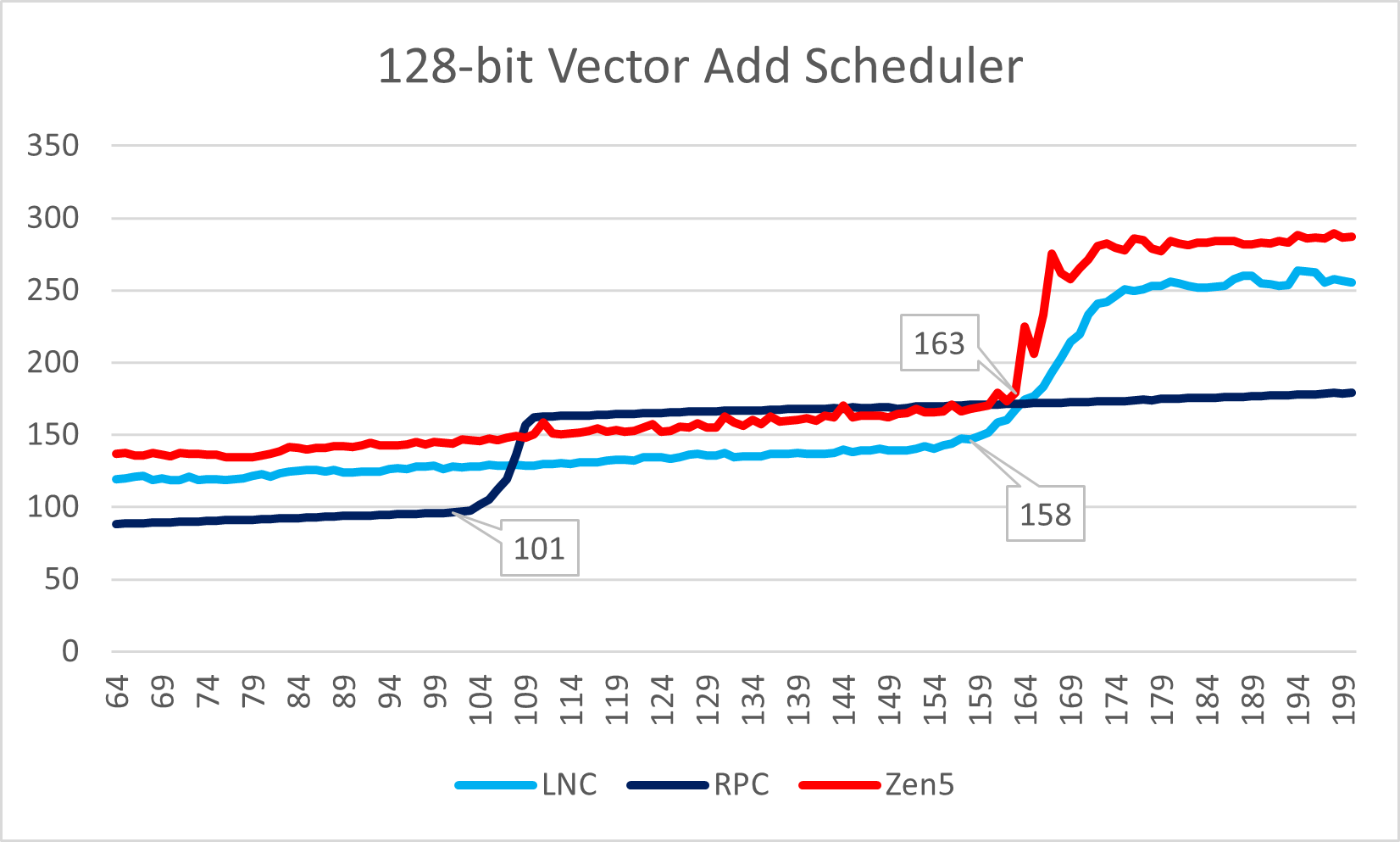
Lion Cove与Zen 5一样,相比各自的前代都大幅度修改了调度器的设计。
Lion Cove完全放弃了从P6时期沿用至Golden Cove的祖传scalar / vector统一调度器设计,将scalar与vector执行单元的调度器完全分离(Sunny Cove已经改过一次,将load / store拆分)。所以我们可以看到,前代Raptor Lake的scalar / vector指令观察到的调度器容量相近,但本代却各自可观察到不同容量。Zen 5则是Zen架构之后首次设计了scalar执行单元的统一调度器。在连续几代作出修改后,现在Intel与AMD两者的scalar部分的调度器设计基本趋同。
访存
相比常见的Intel H系列处理器,Lunar Lake的缓存规模比较保守:大核L3缓存只有12 MB,是Meteor Lake-H的一半,与Meteor Lake-U相当。但它也有自己的特色,那就是增加了一个8 MB的MSC缓存。我们运行一些内存延迟与带宽测试,来看看这些独特缓存结构的实际表现如何。
延迟
本次我们使用4K page观察随机访问不同容量缓冲区的延迟,以更好地模拟PC处理器日常使用场景,同时可以观察不同层级TLB的影响。
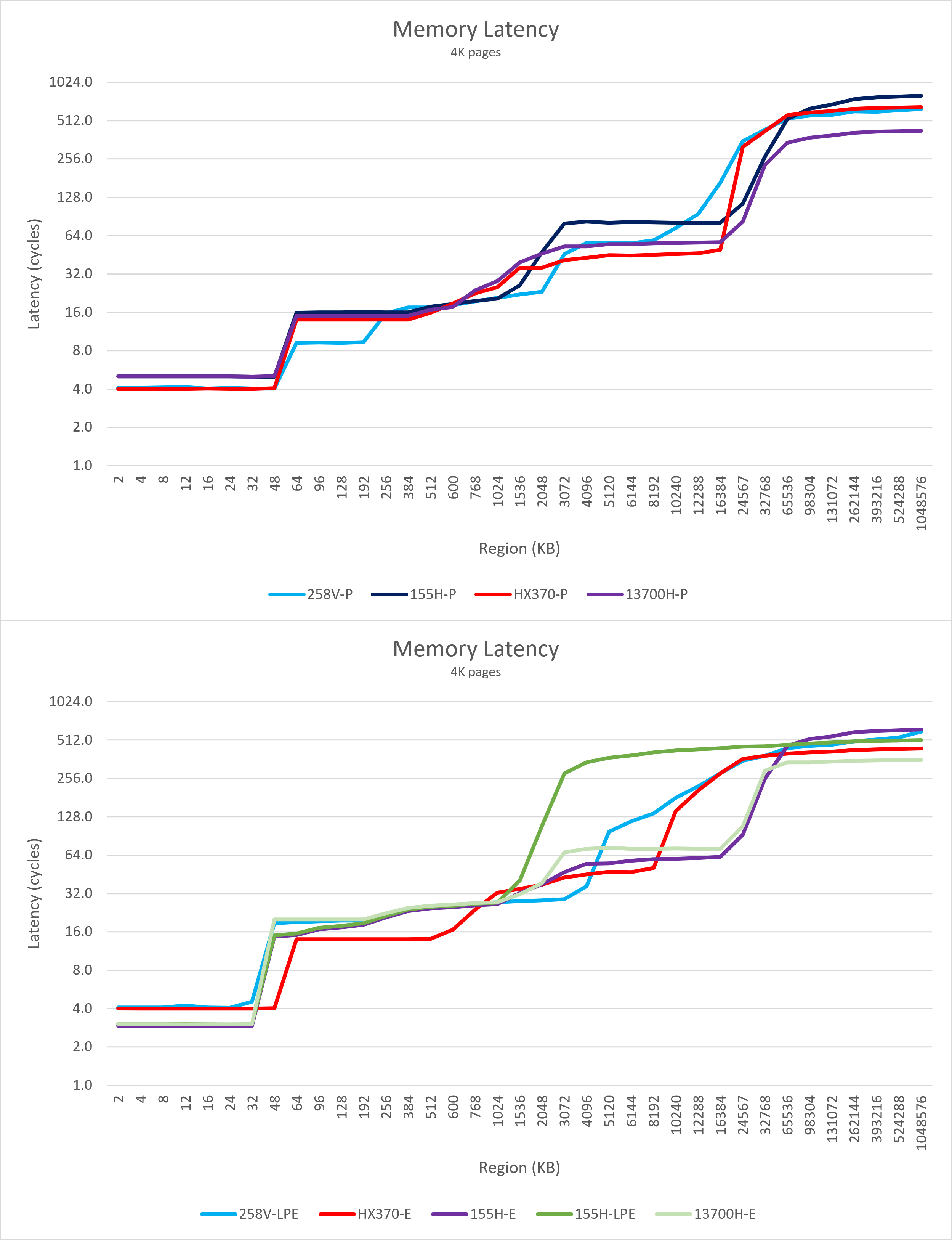
从大核心的延迟测试我们很容易观察到:
- Lion Cove的L1延迟下降到4周期,相比Redwood Cove减少一个周期,与Zen 5相同;
- Lion Cove在L1与L2之间新增的192K缓存显著降低了这一区域的访存延迟;
- Lion Cove的2.5 MB L2缓存在延迟曲线上非常接近Meteor Lake,容量更进一步;
- 在核心频率相同的情况下,Lion Cove的L3延迟远远低于Meteor Lake的Redwood Cove,从80周期下降到55周期,非常接近AMD的水平;
- 不过这并不是本代的提升,而是Meteor Lake的ring频率倒退导致;
- Meteor Lake的ring频率只有3.3 GHz,而Lunar Lake的L3 cache频率高达4.4 GHz(hwinfo Windows读数),在这方面Lunar Lake甚至要明显强于Arrow Lake;
- 通过对比Raptor Cove很容易发现Lion Cove与其L3延迟周期数相近;
- 虽然Lion Cove的L3肉眼可见的容量较小,但是由于L2较大,且8MB MSC可以被CPU访问,很好地填补了这一缺失部分。这使其L3容量以外的访存延迟上升的趋势放缓,实际等效缓存容量与Strix Point大核相比并不逊色,只是后段的延迟偏高,这可以通过合适的缓存交换策略来弥补;
- Lunar Lake内存延迟大幅度改善,相比Meteor Lake降低了大约180周期,从160ns降低到120ns附近,与Strix Point大致在同一水平。
而观察Skymont的延迟测试曲线:
- Skymont L1延迟上升到4周期,相比Gracemont增加一个周期,与大核来到同一水平;
- 这是一个非常重要的变化,与前文里提到的前端取指解码延迟上升相同,这一改变显著放松了缓存的时序,缓解Skymont的L1 cache / SRAM性能压力,提升极限频率;
- 但这也意味着核心需要掩盖的L1延迟显著增加,对核心乱序执行掩盖延迟的能力提出了更高的要求;
- Skymont L2缓存在容量翻倍的情况下延迟略有上升;
- 虽然Skymont LPE没有L3缓存,但其MSC缓存对小核也有非常明显的作用,使其L2缓存外的访存表现远好于Meteor Lake的LPE核心,等效容量与Strix Point的Zen 5c接近,访问延迟高出几十个周期。
单线程带宽
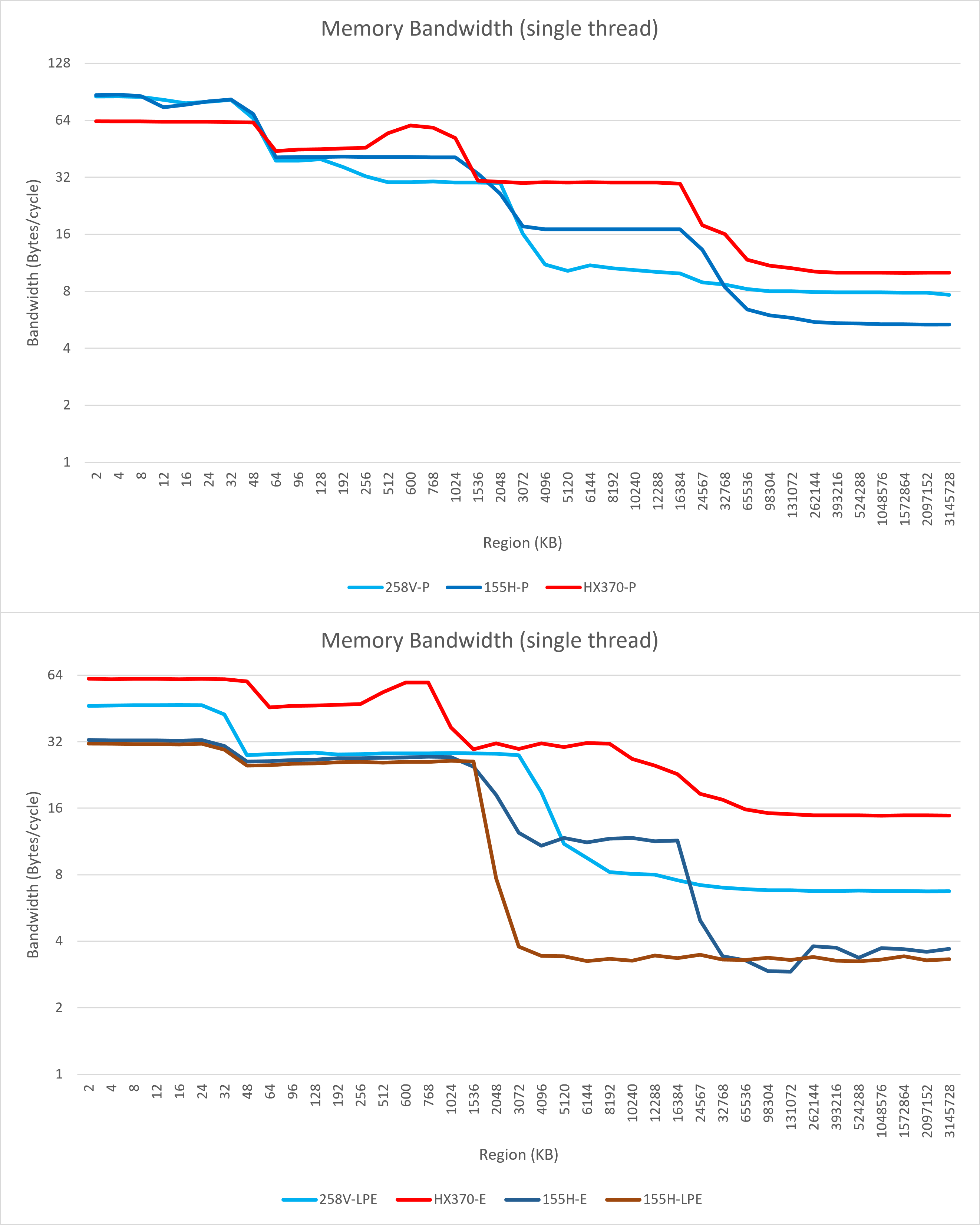
Lunar Lake在单线程内存带宽方面也有不少变化:
- 相比Meteor Lake的大核,Lunar Lake大核的L2与L3均出现了较大幅度的带宽下降;
这可能是Intel为了节能而特意为Lunar Lake上的Lion Cove进行的缩减,并不代表Arrow Lake等高性能Lion Cove核心的表现;- 2024/10/26更新:在Arrow Lake中我们也能观察到类似的现象。对于L2,个人推测是由于“L1.5”的加入使得Intel认为L2的带宽压力会下降,而对于L3则可能是因为更大的L2会使得L3的带宽压力下降;
- Lion Cove单线程内存读取带宽显著增加,不过从数值上看这并不意味着微架构层面发生了很大的改变,而是因为内存延迟大幅度降低使其prefetcher能够在相近的队列深度下显著提升带宽(参考Little’s Law)。
- Skymont将L1的带宽从32B/cycle提升到了48B/cycle,意味着其128-bit向量读取吞吐从2增加到了3。
- Skymont LPE单核读取内存的带宽翻倍,考虑到其访存延迟周期数与Meteor Lake LPE并没有太大区别,这代表着其prefetch队列更深。
多线程带宽
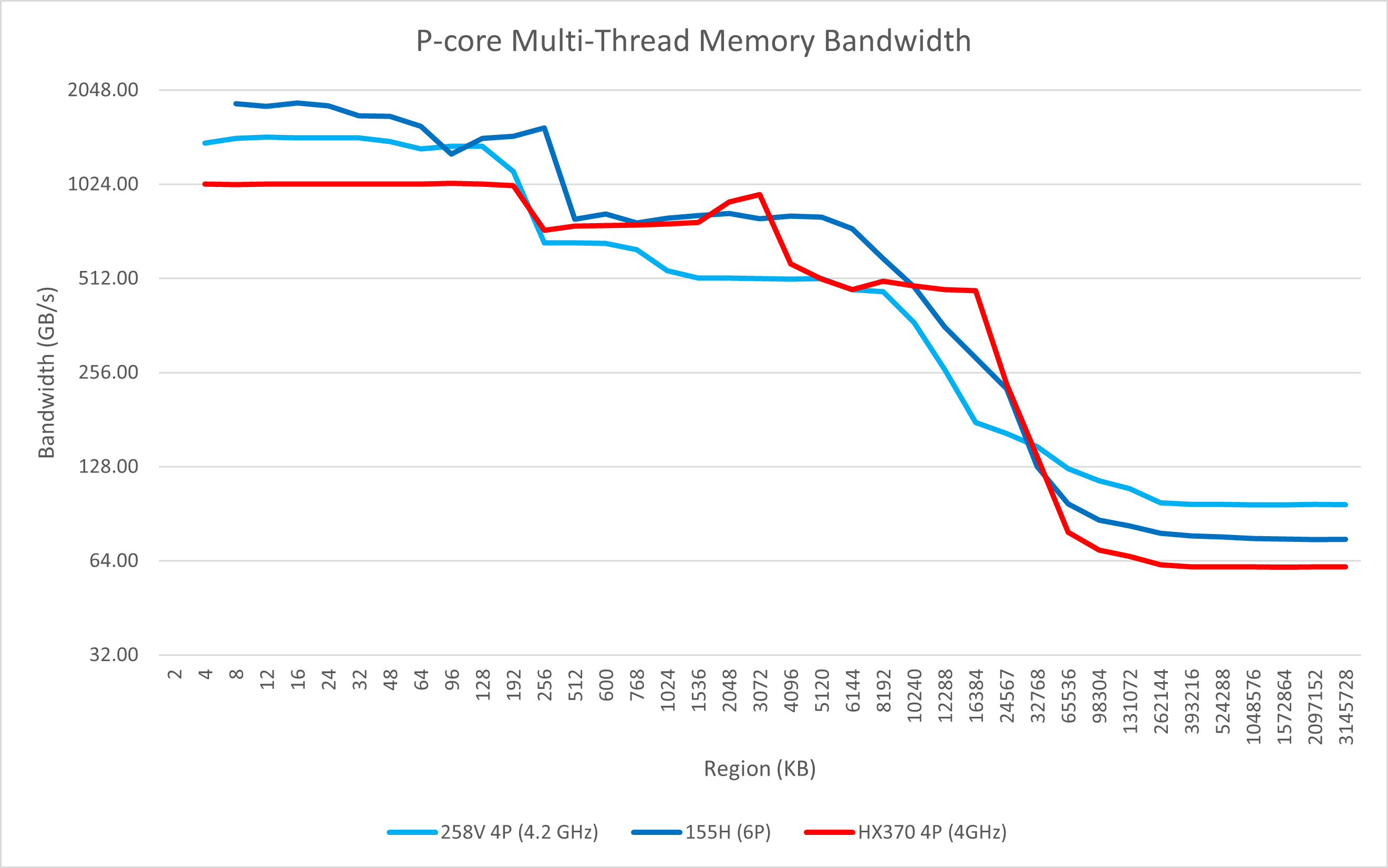
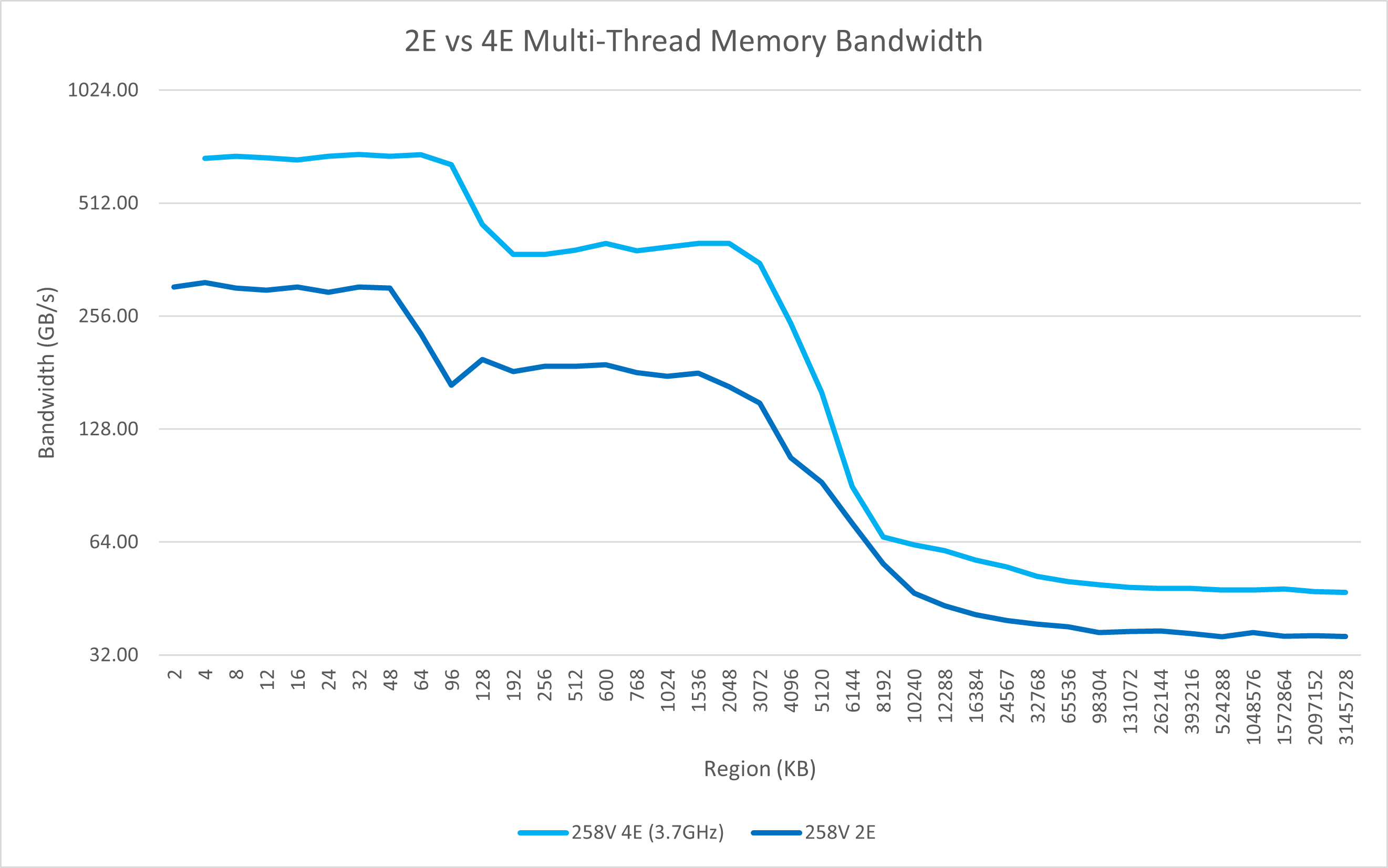
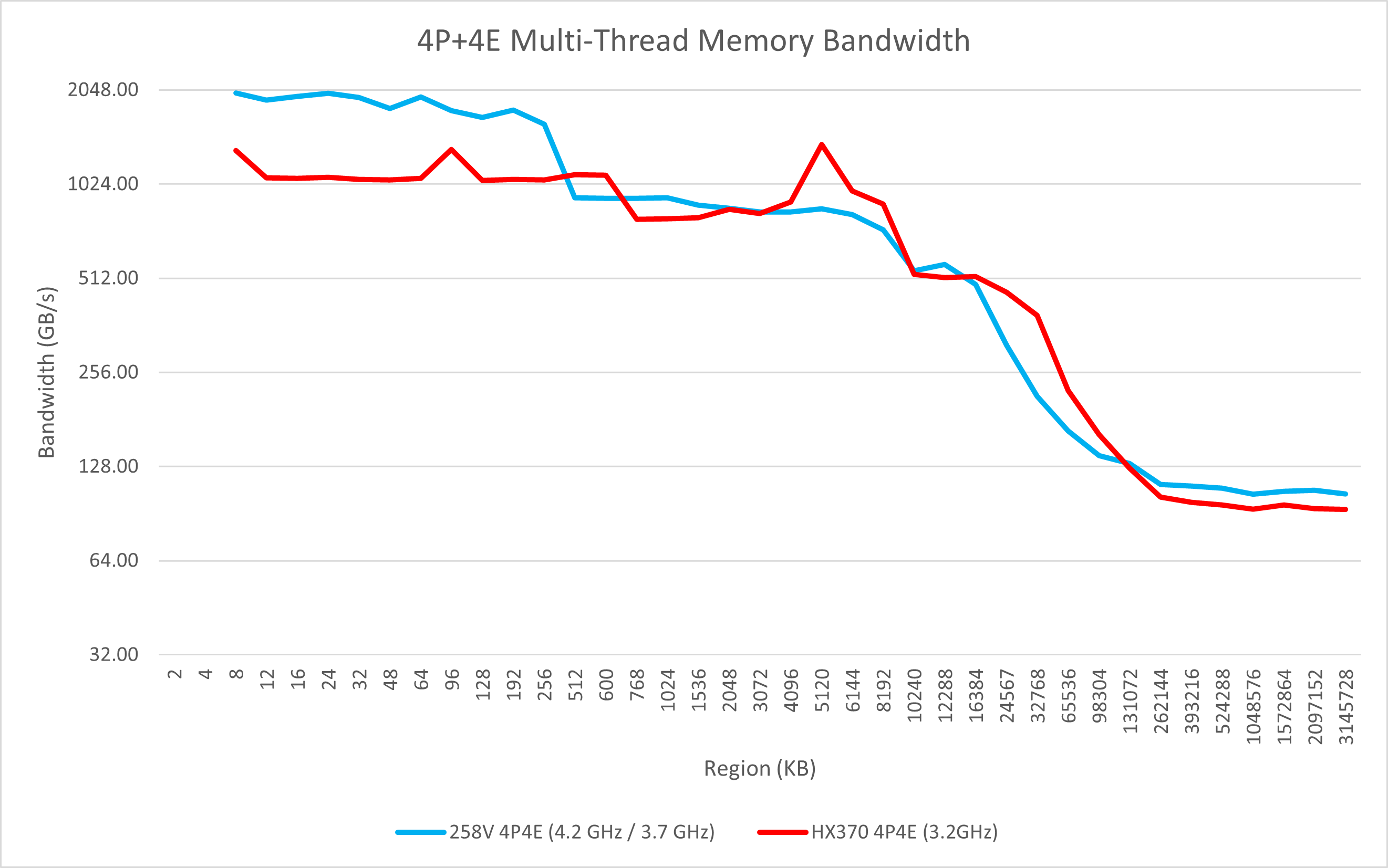
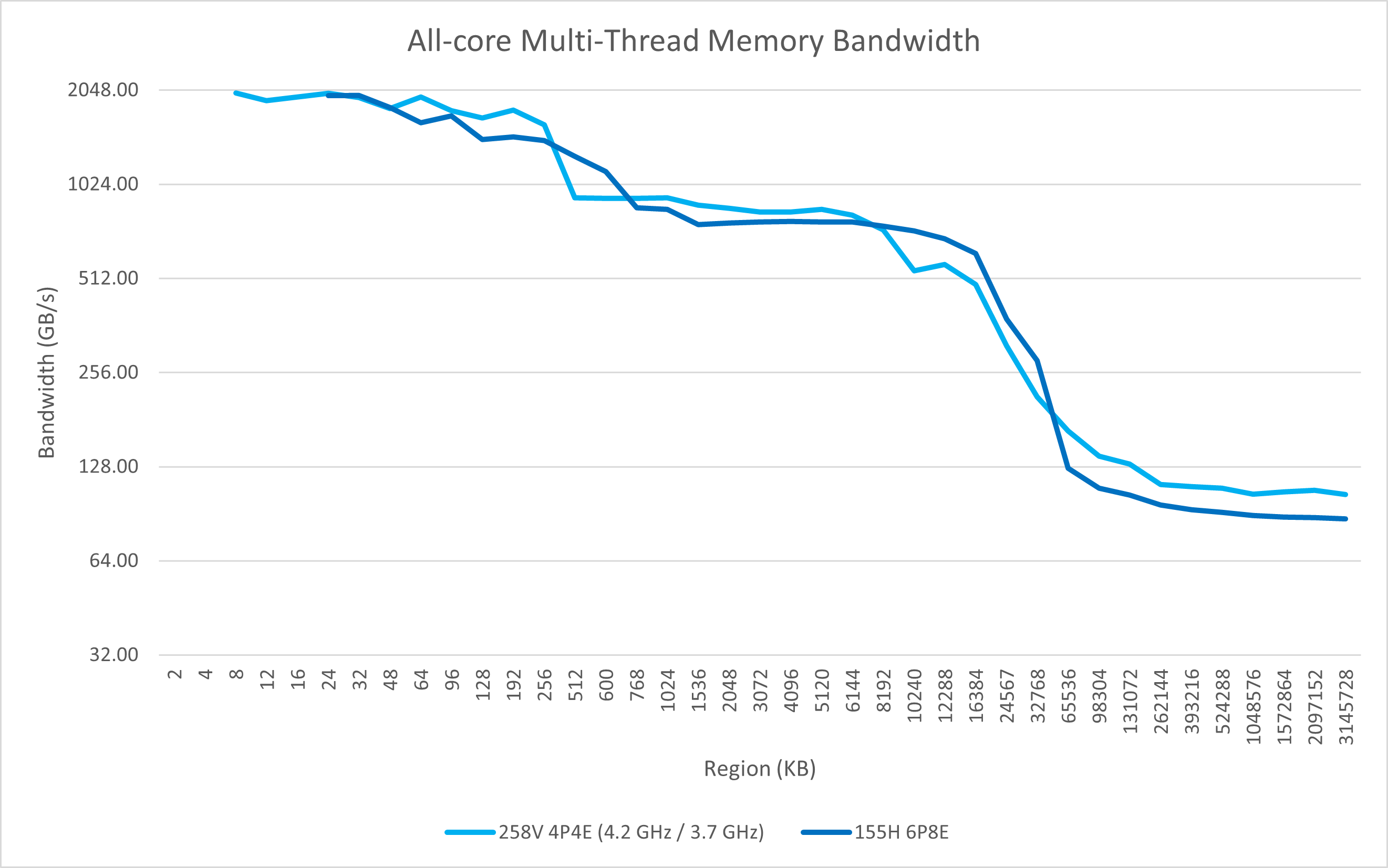
从多线程的测试中我们也可以看出Lunar Lake一些变化:
- 4个P核可以达到96 GB/s的内存读取带宽,比上代6个P核的76 GB/s还要强,远强于AMD单个CCX的61 GB/s;4个E核则有48 GB/s的带宽;
- 在全核心的测试里依然能观察到大核的L2/L3带宽缩减;
- 4个E核不再只有两倍于单核的L2读取带宽,而是完整的4倍读取带宽;
- 全核心带宽可达108 GB/s,远强于Meteor Lake的88 GB/s,也强于Strix Point的96 GB/s。这得益于Lunar Lake更高的理论带宽(128bit LPDDR5x-8533也就是136 GB/s)
总的来说,可以看出Lunar Lake在缓存方面作出了相当多的调整与改进。但我们看到的更多的是“调整与裁剪”而不是继续加大规模,这与其本身注重低功耗的平台特性相符。
除此之外,尽管在缓存带宽方面的缩水较为严重,Lion Cove在延迟方面的改进却相当大,而这正是对整数测试最重要的点,也是本文重点关注的对象。这一点也能体现在后面的SPEC CPU测试的部分子项成绩里。
GPU访存
虽然本文的主要重心是两种CPU核心的测试与对比,不过从GPU侧我们也可以进行一些观察,尤其是带宽方面可以充分检验SoC的真正实力
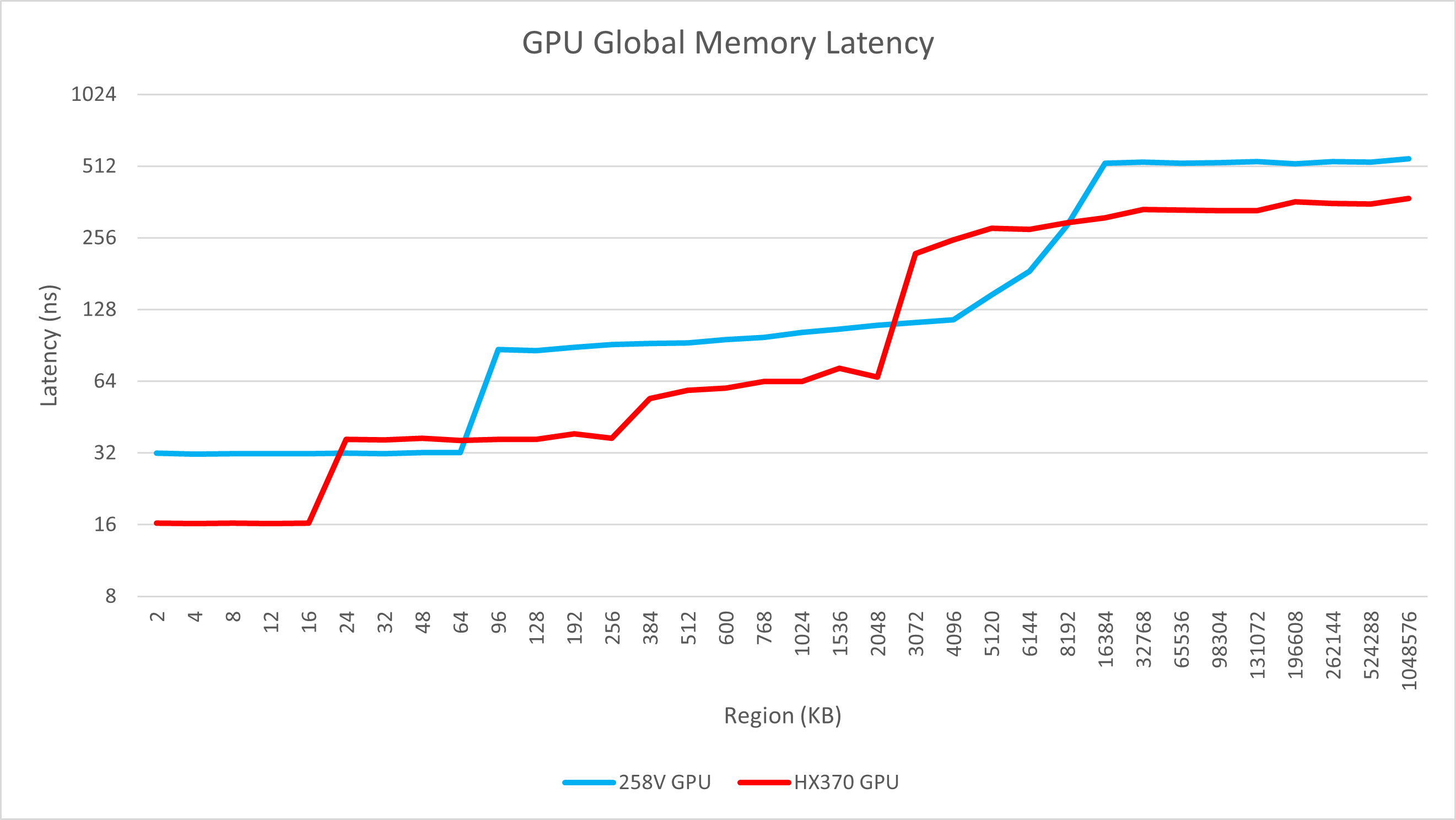
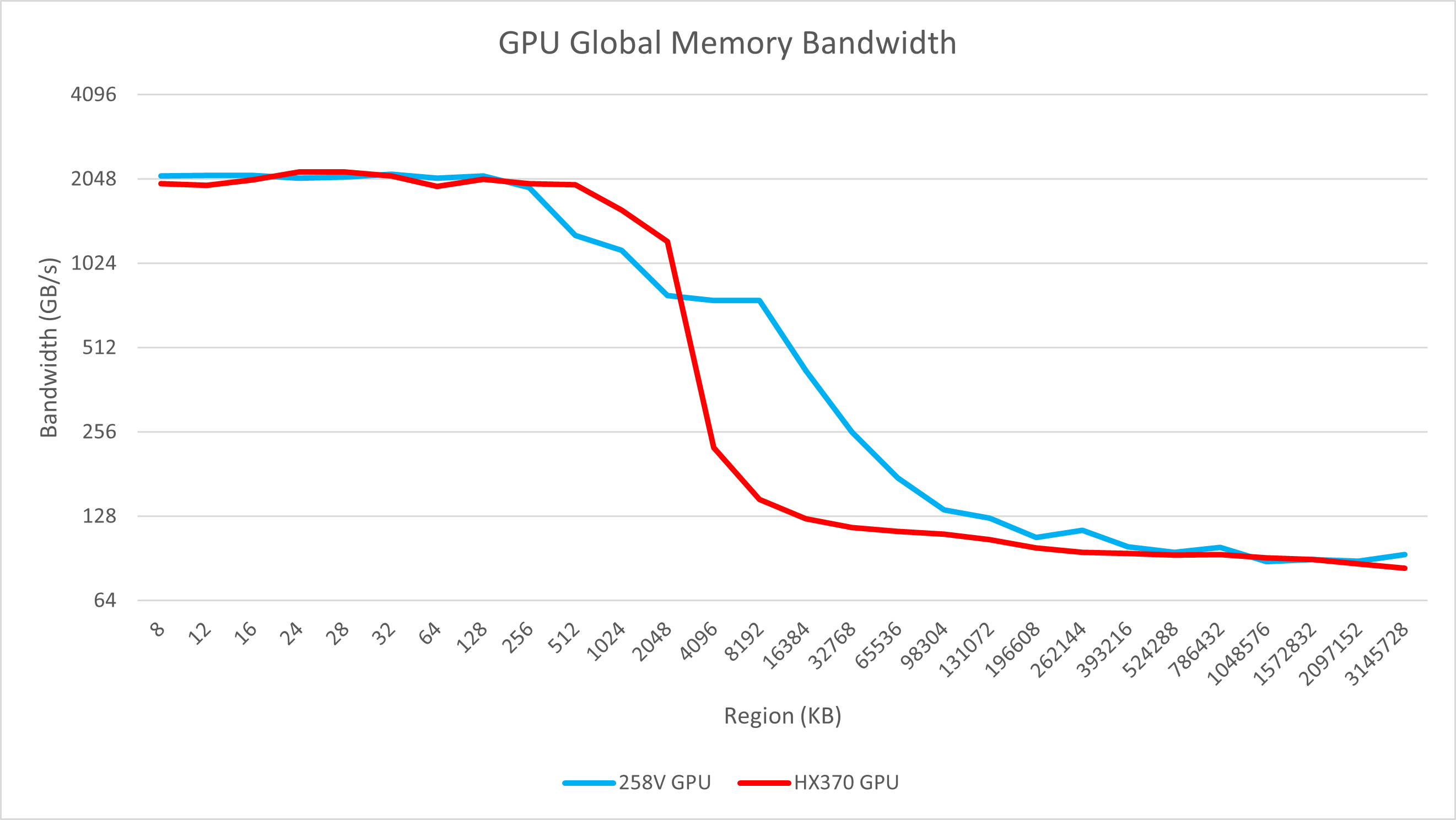
Lunar Lake的GPU频率较低,远不及HX 370 (2 GHz vs 2.9 GHz),因此其绝对延迟方面的劣势较大,甚至不少缓存区域的延迟差距超过了一倍以上。此外,其访问内存的延迟也有巨大的劣势。
但即便是频率较低的情况下,其L1缓存带宽依然毫不示弱,达到了与Strix Point相近的水平,说明同频下的带宽更高。L2带宽则显得略微乏力。
可以很容易观察到Lunar Lake的GPU末级缓存容量远高于Strix Point,其GPU独占8 MB L2,而相比之下Strix Point则只有2 MB。除此之外,可以很容易看出在8 MB的GPU L2之外,Lunar Lake依然可以在相当大的区域内维持带宽缓慢下降,说明SLC对GPU的访存也有一定的作用。这足以见得Intel在GPU方面的投入之大,当然实际疗效如何还需要看游戏测试,本文不多加分析。
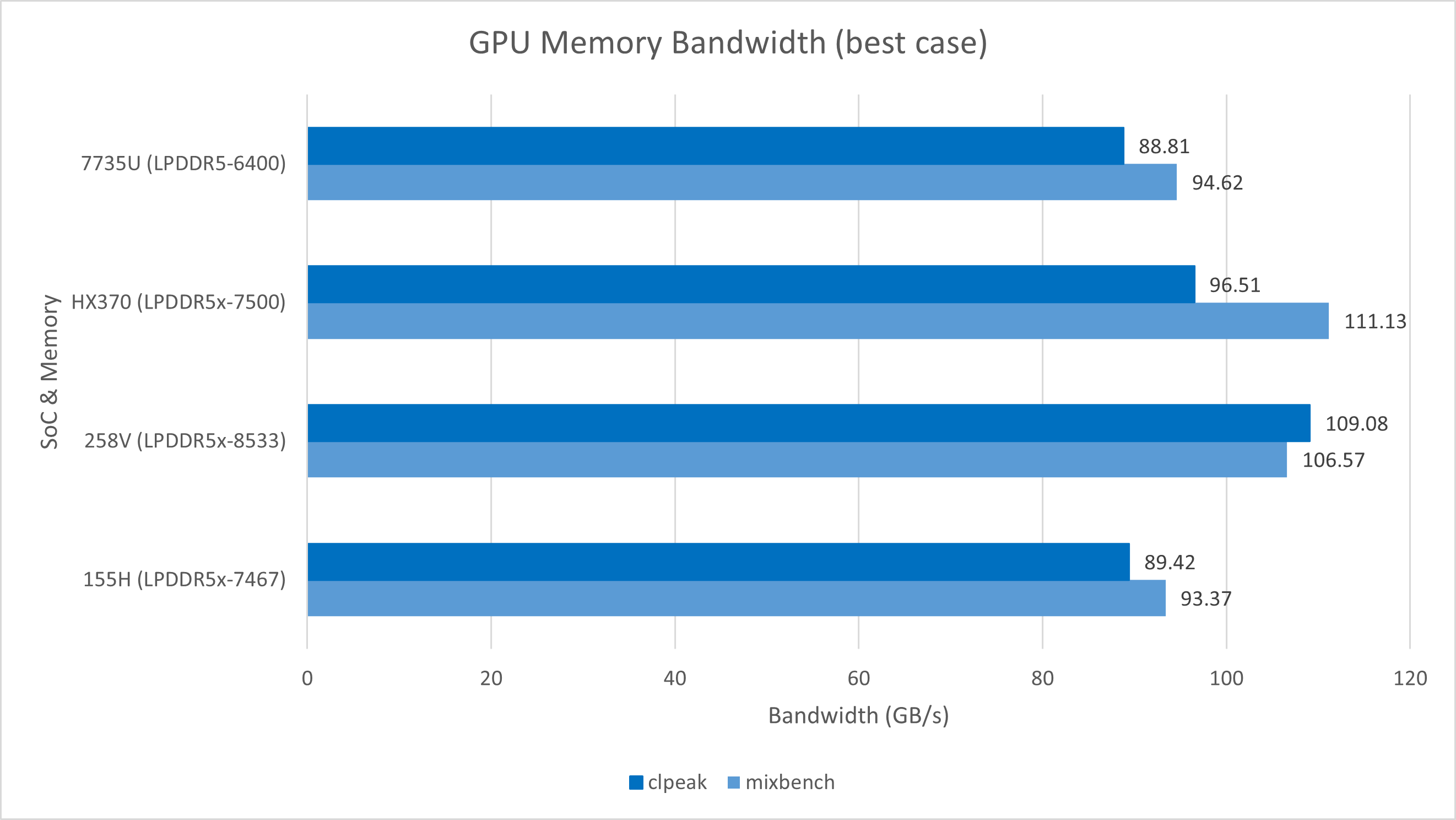
Lunar Lake的LPDDR5x-8533内存在带宽方面相比前代提升较大,测试中的峰值达到了109 GB/s左右。不过Intel GPU在实际测试的带宽方面相比同样内存规格的AMD处理器依然略显逊色。
多核心互联
与AMD、Apple、高通Oryon类似,这一代Intel的小核也不再与大核位于同一个L3 cache domain内,也就是说Lunar Lake的小核是一个类似Meteor Lake LPE的核心。这样做的好处是小核心单独工作时不需要带着整个大核缓存一起唤醒,可以降低低功耗下的静态功耗;坏处是小核不再能享受大缓存带来的性能提升,并且当核心分布于不同cluster时,缓存一致性通常需要在SoC fabric上处理,而这样做通常显著慢于cluster内部。
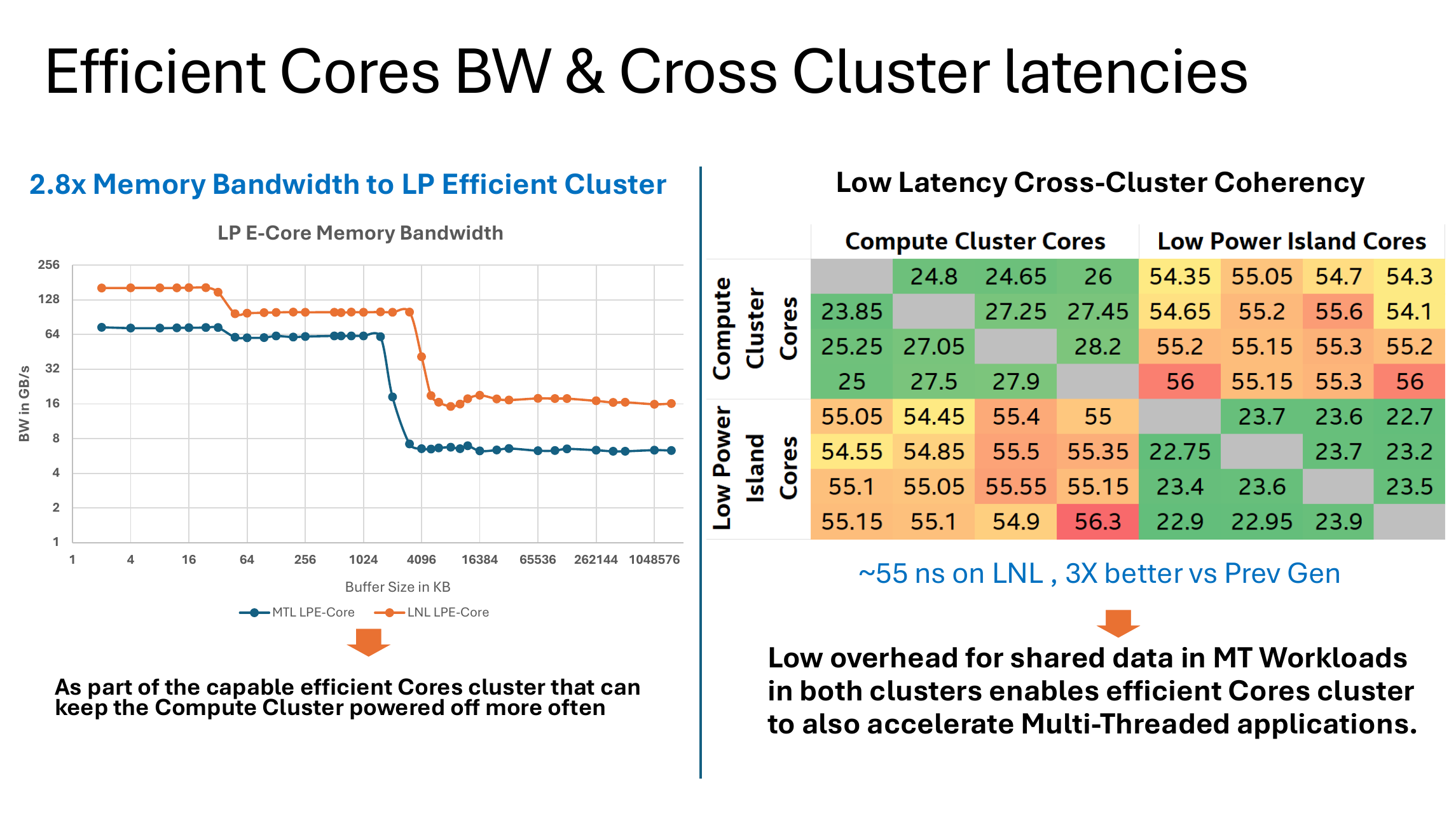
Intel在Hot Chips 2024上展示了这样一组数据,从结果上看似乎是每次都将cache line分配在测试的两个核心之一附近的best case测试的场景。而我们这次针对Lunar Lake也使用与之前相同的程序测试worst case(也就是每一次核心同步都使用最初分配的cache line进行同步),并与此前相同测试程序测试出Strix Point、Apple Silicon的延迟进行对比。
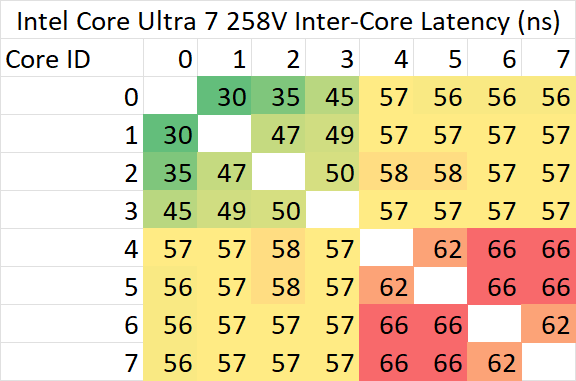

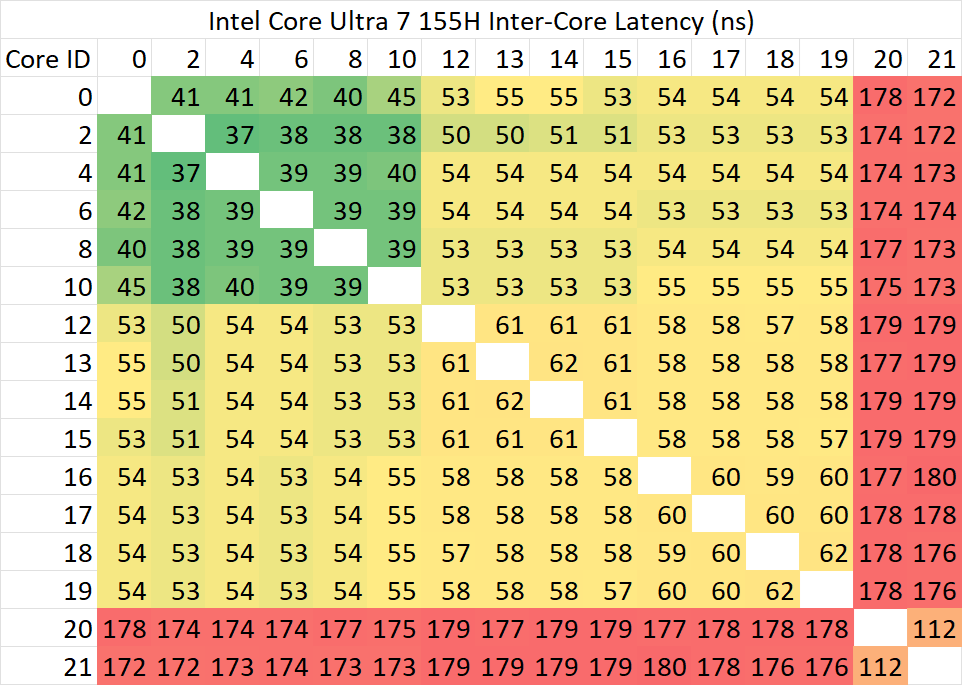


可以看到,非常令人惊讶的是,Lunar Lake的大小核一致性延迟并没有前面提到的其他SoC那样的问题——在测试缓存一致性时,所有核心仿佛位于同一个cluster。除此之外可以观察到这些细节:
- P核之间的最低延迟相比Meteor Lake大幅度下降,回到13700H相近水平;
- 即便Lunar Lake的L3 cache频率相比Meteor Lake大幅度提升,基本回到13700H的水平,其P核之间每间隔一个节点的延迟增量却反而大幅度提高:从13700H (Raptor Lake) / 155H (Meteor Lake) 的延迟几乎稳定不变改为每跨越一个节点就稳定增加大约5ns;
- 这一趋势延续到P-E的延迟,整体相比延迟最高的P-P还要多出>5ns;
- E-E的延迟的趋势与155H(Meteor Lake)相近,都要高于P-P/P-E延迟;
考虑到Lunar Lake的ring/L3频率并无异常,可以根据这些现象作出以下几点推测
- 多核心互联一致性不再传统地与L3绑定,而是分离出来作为一个独立的网络运行;
- 这个互联的频率/性能显著低于此前SoC的ring频率,但是功耗表现可能更佳;
- 小核心尽管共享同一块L2数据缓存,其在这个一致性网络上却表现出两两一组的设计;
- 尽管官方公布的测试结果里P/E核心类似两个CCX,但与一般多CCX设计不同的是,Lunar Lake小核进行同步时并不会将cache line拷贝到自己的L2缓存。这点与此前ring上的小核有一定的相似之处,与N305等纯小核的多cluster atom略有不同;
- 也许可以理解成小核依然跟大核挂在同一个ring上,但是被禁止填充L3。
Lunar Lake这样做的好处很多,可以说是两全其美:既没有双cluster超高互联延迟的问题,又能一定程度避免小核心带起太多的高性能组件产生太高的静态功耗影响低功耗能效。
代价则是一定程度上牺牲大核之间的互联性能,因为跨越节点的潜在互联代价变大,也就是核心数量上的扩展性会变差。Lunar Lake在ring频率不存在明显缺陷的情况下,仅在4大核节点内就有50ns的worst case延迟,在5-6节点内就已经能出现将近70ns的worst case延迟。按照这个趋势,如果扩展到更多的核心数则会产生更严重的问题。因此也不太能根据Lunar Lake的表现去指导Strix Point或者Snapdragon X Elite这类12核心产品的设计。
当然,由于Intel在Hot Chips上公布的细节有限,上述这些内容许多都仅仅只是猜测。但可以肯定的是,我们从Lunar Lake的测试中可以观测到一个比Apple Silicon更加优雅、更适合低功耗使用场景的少量核心多cluster互联设计。
性能测试
本次还是照例分别对大/小核进行SPEC CPU 2017/Geekbench单线程性能测试,并适当选取一些内存配置相近的前代产品、本代竞品进行对比。SPEC CPU数据已与本文同步更新到排行榜。
SPEC CPU 2017
考虑到移动端散热局限性和SPEC CPU长时间高压运行带来的潜在频率不稳定性,本次对大核心选取默频与定频4.2 GHz分别进行测试。除此之外,为了直观对比各个微架构的同频性能,本文也会提供3 GHz附近的Perf / GHz数据。
需要注意的是,本次测试的HX 370与155H均为散热能力较弱的ZenBook系列,因此默频成绩可能会偏低。Lunar Lake为散热相对较好的模具,可以稳定单核4.8 GHz。
默频性能
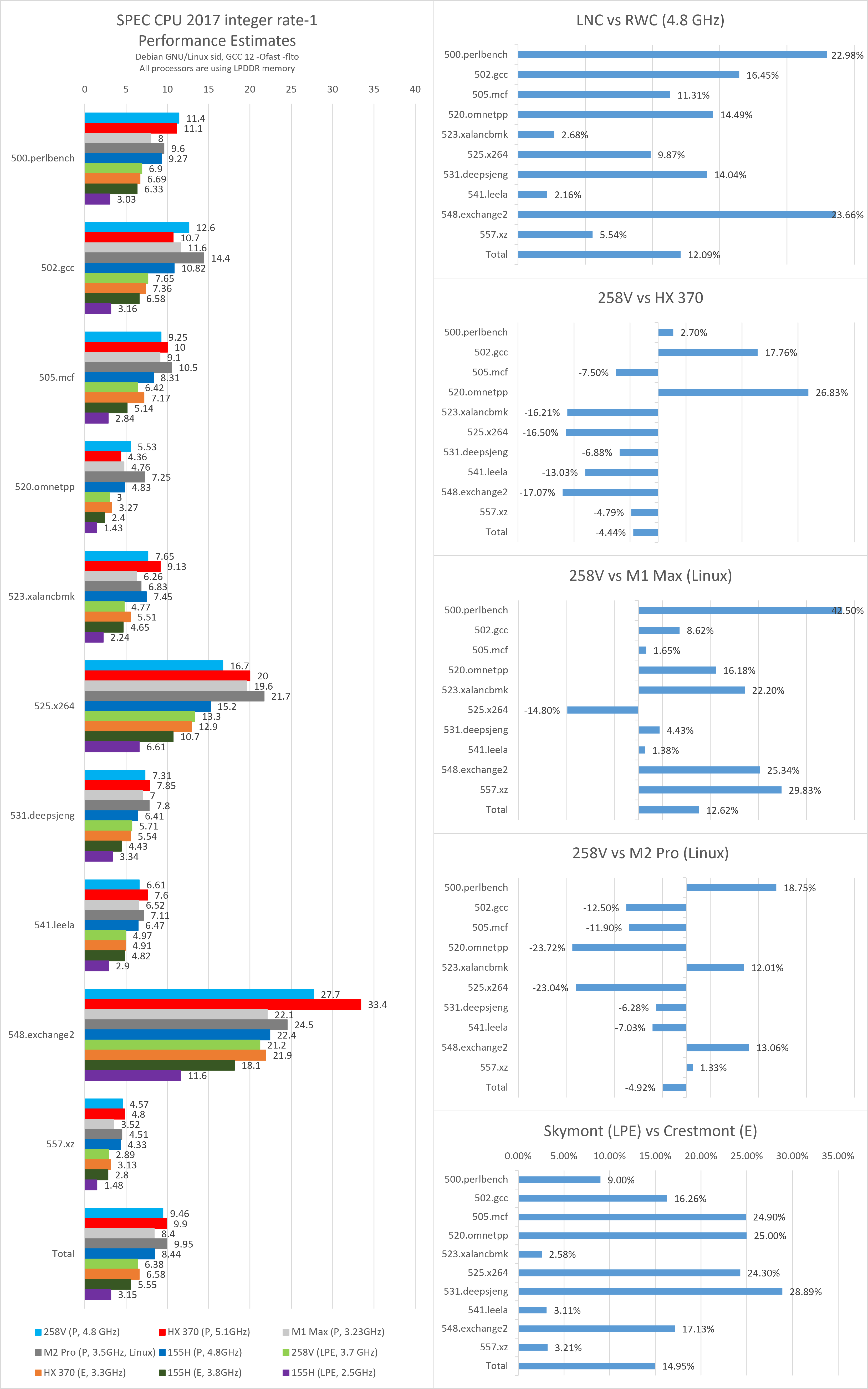
258V的Lion Cove @ 4.8 GHz在这些测试里,
- 相比前代Meteor Lake的Redwood Cove(同频)提升约12%;
- 相比HX 370的Zen 5 @ 5.1 GHz落后约4.4%;
- 相比M1 Max (Linux) @ 3.23 GHz领先约12.6%;
- 相比M2 Pro (Linux) @ 3.5 GHz落后约4.9%。
258V的Skymont LP E @ 3.7 GHz在这些测试里,
- 相比Meteor Lake ring上的Crestmont E核(3.8 GHz)提升约15%;
- 相比Meteor Lake的Crestmont LP E @ 2.5 GHz核心性能提高一倍;
- 与HX 370的Zen5c @ 3.3 GHz核心性能差距大约在3%左右。
大核同频性能
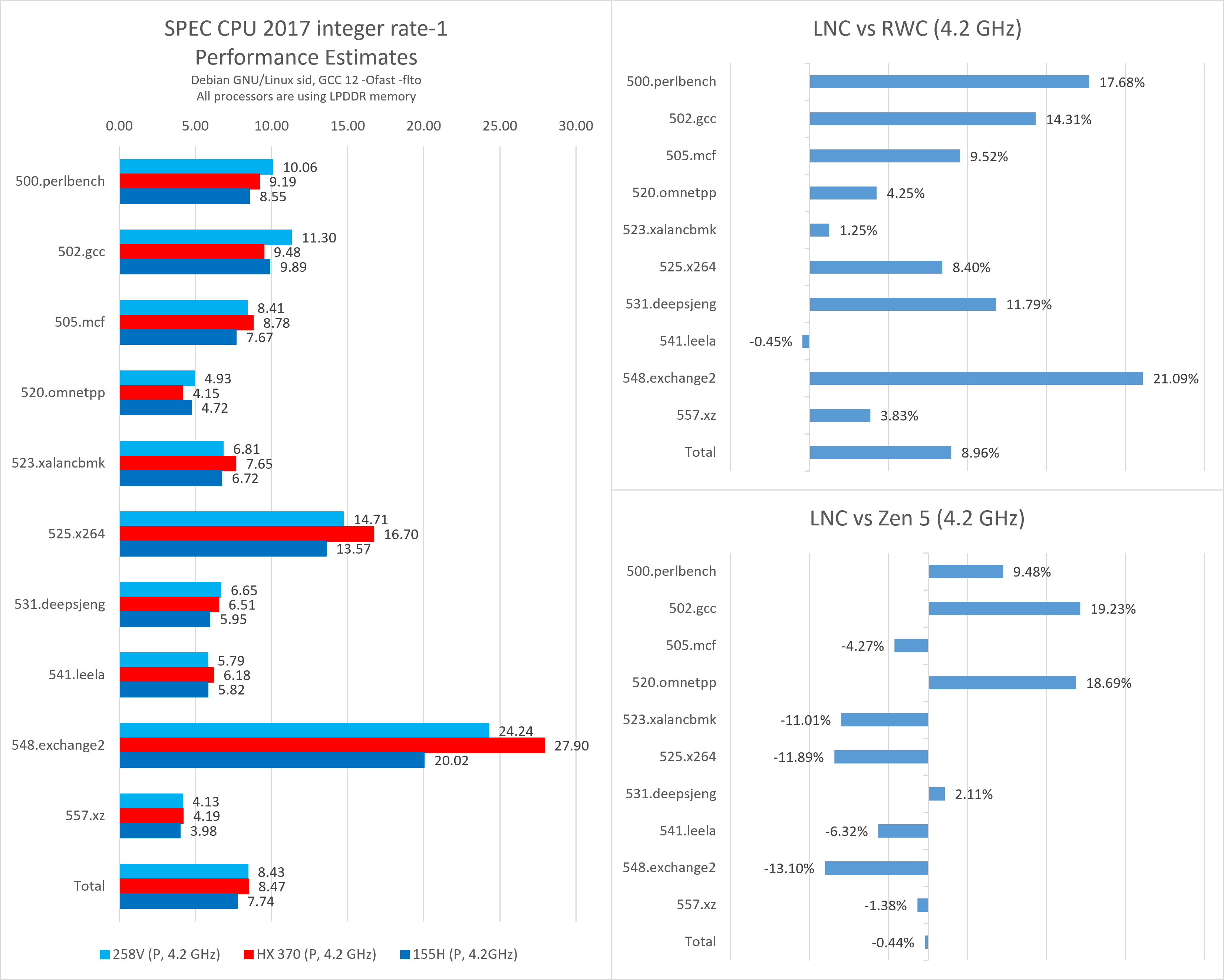
在4.2 GHz的同频测试中,
- Lion Cove (Lunar Lake)相比Redwood Cove的提升幅度下降到8.96%;
- 从子项分数变化的趋势看,可能是Meteor Lake测试机散热不佳与Meteor Lake Ring频率偏低共同作用导致其默频测试性能较差;
- Lion Cove提升较大的子项为perlbench与exchange2,这是SPEC整数测试里指令吞吐瓶颈最大的两项,也是从6宽提升到8宽理论上最容易获得提升的两项;
- 提升最小乃至倒退的子项是xalancbmk与leela,前者对缓存延迟较为敏感,后者是较为难以分支预测成功的测试,对流水线长度、前后端延迟较为敏感;
- 这说明Lion Cove在吞吐方面进步明显,在前后端整体延迟方面进步不大;
- Lion Cove (Lunar Lake)与Zen 5 (APU)的同频综合性能非常接近;
- 由于缺乏具体的PMC数据,以下只能根据以往的profiling经验进行一些粗略的猜测;
- 优势项目为gcc、omnetpp与perlbench;
- 16 MB L3缓存的AMD平台在这些测试中一直表现不佳,意味着Intel大核心在本代依然有更好的prefetcher,可以在相近的总缓存容量下获得更好的性能;
- 除此之外新增的192 KB L1缓存和增大的2.5 MB L2缓存也使Lion Cove在更多的情况下有访存优势。
- 劣势项目为xalancbmk、x264与exchange2;
- xalancbmk对缓存延迟比较敏感,而Lunar Lake的L3较小且延迟相比Zen 5略高,MSC延迟较大等因素可能导致其并不能相比Meteor Lake获得大幅度提升;
- x264对SIMD整数性能有一定要求,而Lion Cove虽然相比Redwood Cove降低了延迟,但与Zen 5相比依然差距明显;
- Intel前几代大核在exchange2测试中bad speculation占比较高,本代分支预测提升不大的情况下合理怀疑其分支预测是导致性能差距的主要因素之一。
低频PPC
在 3 GHz附近进行测试,并计算各个处理器的Perf / GHz数据,可以得到下面的结果。为了进一步抹平缓存容量带来的差距,下面这张图表里也额外提供了“非内存/缓存敏感”的子项综合分数(525/531/541/548的geomean)。
当然,小核心相对更保守、更节能的prefetch机制,更小的乱序结构带来的更弱的延迟掩盖能力也会影响其在内存、缓存敏感的测试里使用相同缓存、内存配置时的性能表现,因此“内存/缓存敏感”子项的性能差异并不完全由缓存容量或者内存延迟差异导致。
除此之外需要注意的是,此处的Skymont使用了uncore降频的数据(本文的能效测试部分有详细的解释),因此相比前面3.7 GHz的数据会有明显偏高的访存开销。
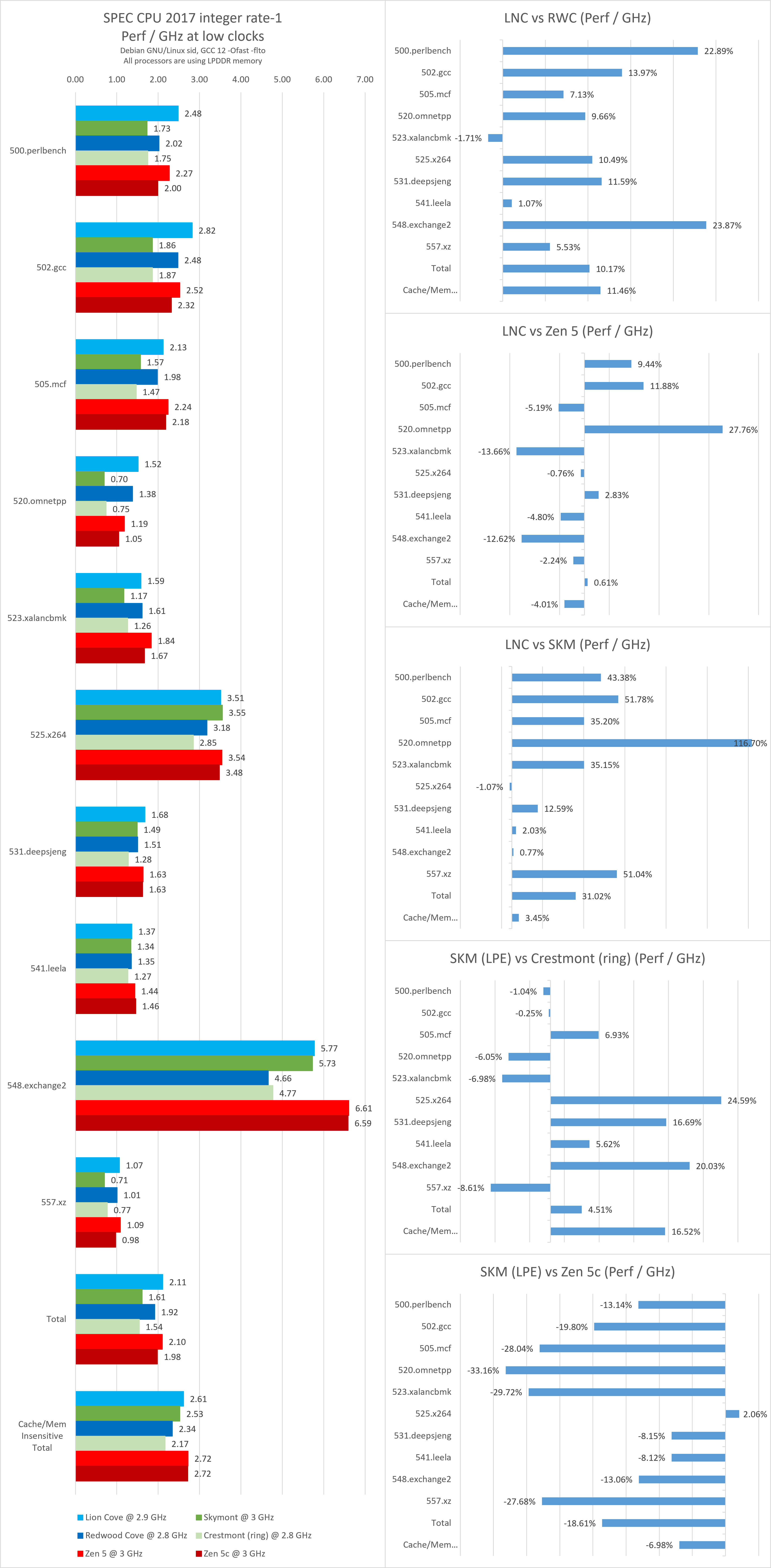
在这项测试中,我们更注重观察小核的表现。很容易看出Skymont LPE的表现受到内存、缓存性能的严重拖累:
- 在缓存/内存不敏感的4个子项里,Skymont的IPC与Lion Cove同频性能相差无几;
- 这些子项里Skymont相比Crestmont的性能提升也最为明显(+16.5%),超过了Redwood Cove;
- 与Zen 5c的性能差异也体现出类似的趋势。
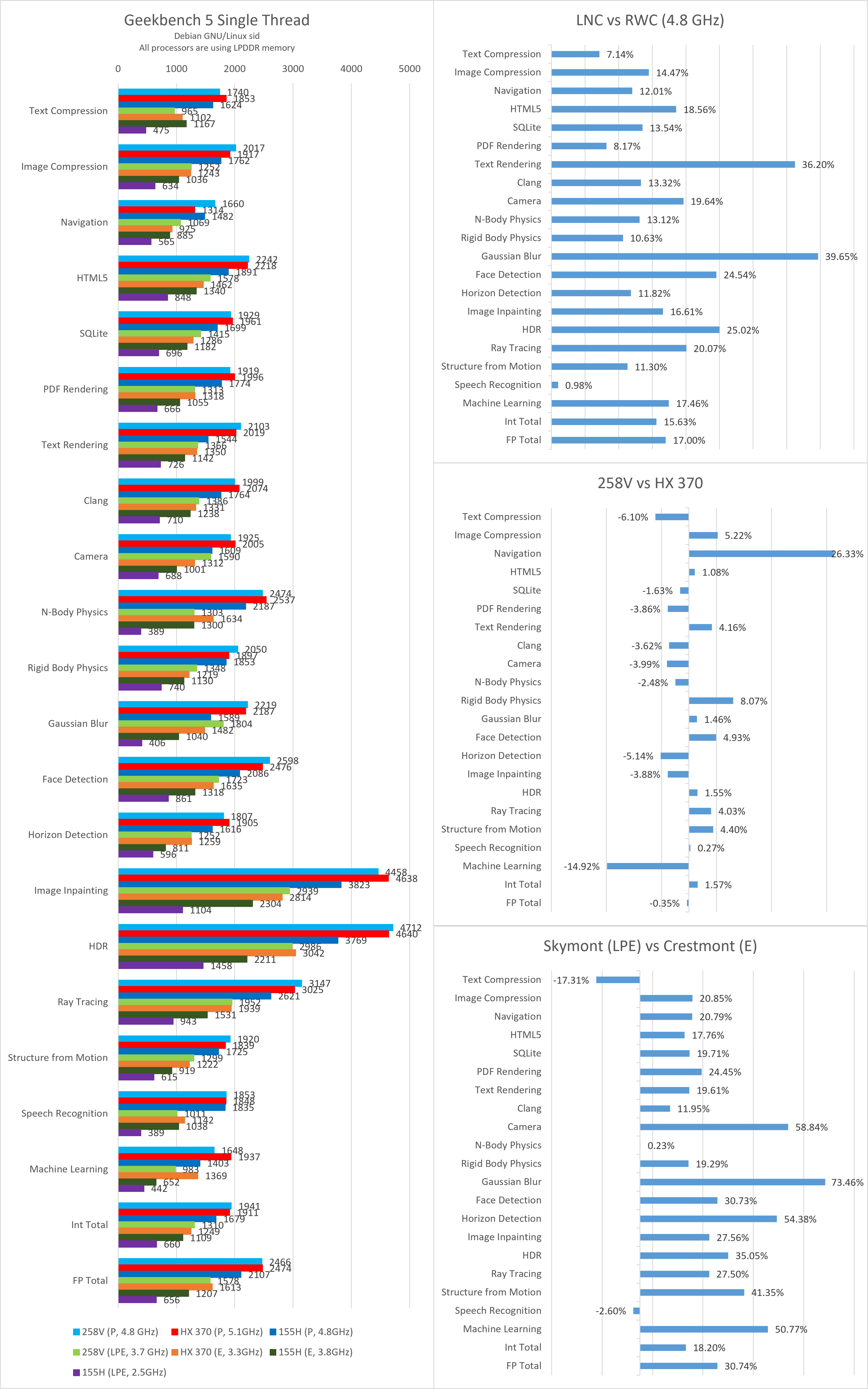
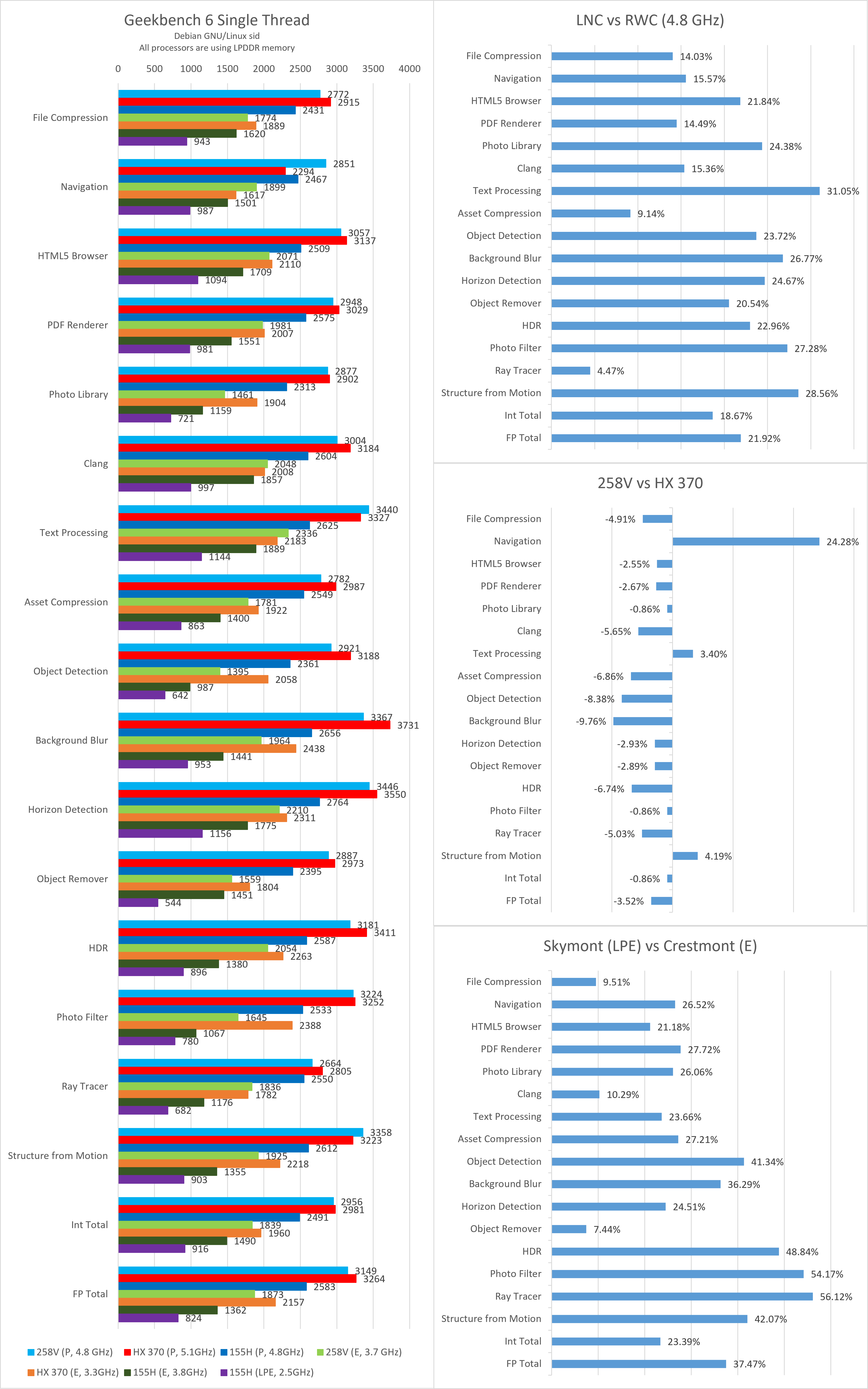
Geekbench
相比于SPEC CPU 2017,Geekbench对缓存与内存的压力小得多,并且非常偏向于高指令吞吐而不是流水线延迟敏感。可以看到无论是大核还是小核,在这些测试里的平均提升都要远大于SPEC CPU 2017。这里由于篇幅所限,我们不做过多的分析。
能效测试
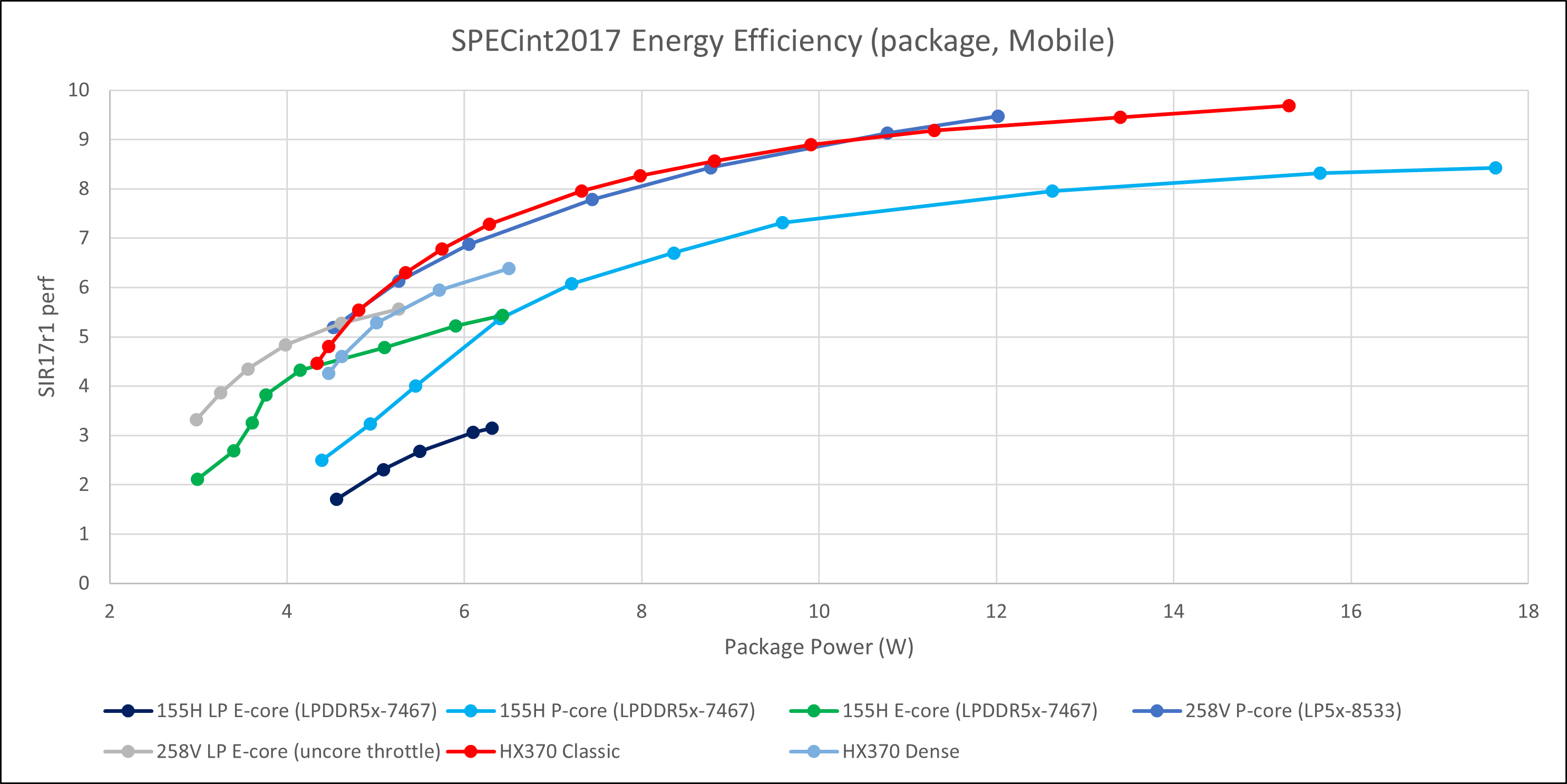
新平台的能效测试是一件非常困难的事情,更困难的是对比多个新平台。尤其是对于Lunar Lake这种连供电结构都发生了很大改变的平台,很难确保传感器读数与其它平台具备可比性。
在此基础上,Linux目前对Lunar Lake电源管理的支持较差,idle时会有接近2W左右的package功耗读数。这一点倒是意外地与Strix Point很类似,后者可以观察到一个2.5W左右的idle package读数,通过读取pm table可以看到其中SoC uncore功耗大约1W+。
因此,受限于测试的局限性,本文所提到的Package能效数据仅用作粗略参考,且不针对其进行细致分析。我们会将分析的重点放在Intel IA / AMD VDDCR功耗曲线上。
单线程能效
使用Linux的RAPL接口记录Lunar Lake运行SPEC CPU 2017的功耗,我们可以得到Package功耗与IA功耗的读数。
Package功耗
IA / VDDCR 功耗
此前测试AMD新品时没有时间折腾这个,这是因为AMD处理器常规的MSR / RAPL接口并不能读取到核心VDD的数据,必须自行使用MMIO读取SMU / pm table才能做到。最近也终于抽了点时间把Strix Point的pm table给dump下来解析。不过需要注意一点,那就是从pm table里读取到的是一个瞬时值,会显著受到读取它这一操作本身的影响,因此测得的数值会略微偏高,不如RAPL这种单増energy counter准确。本文我们使用cpupower工具通过CPPC接口将所有不参与测试的核心锁定在较低频率,以尽可能减少影响。
Intel在Linux下的RAPL接口相对比较完善,IA功耗可以与Package功耗一并采集。
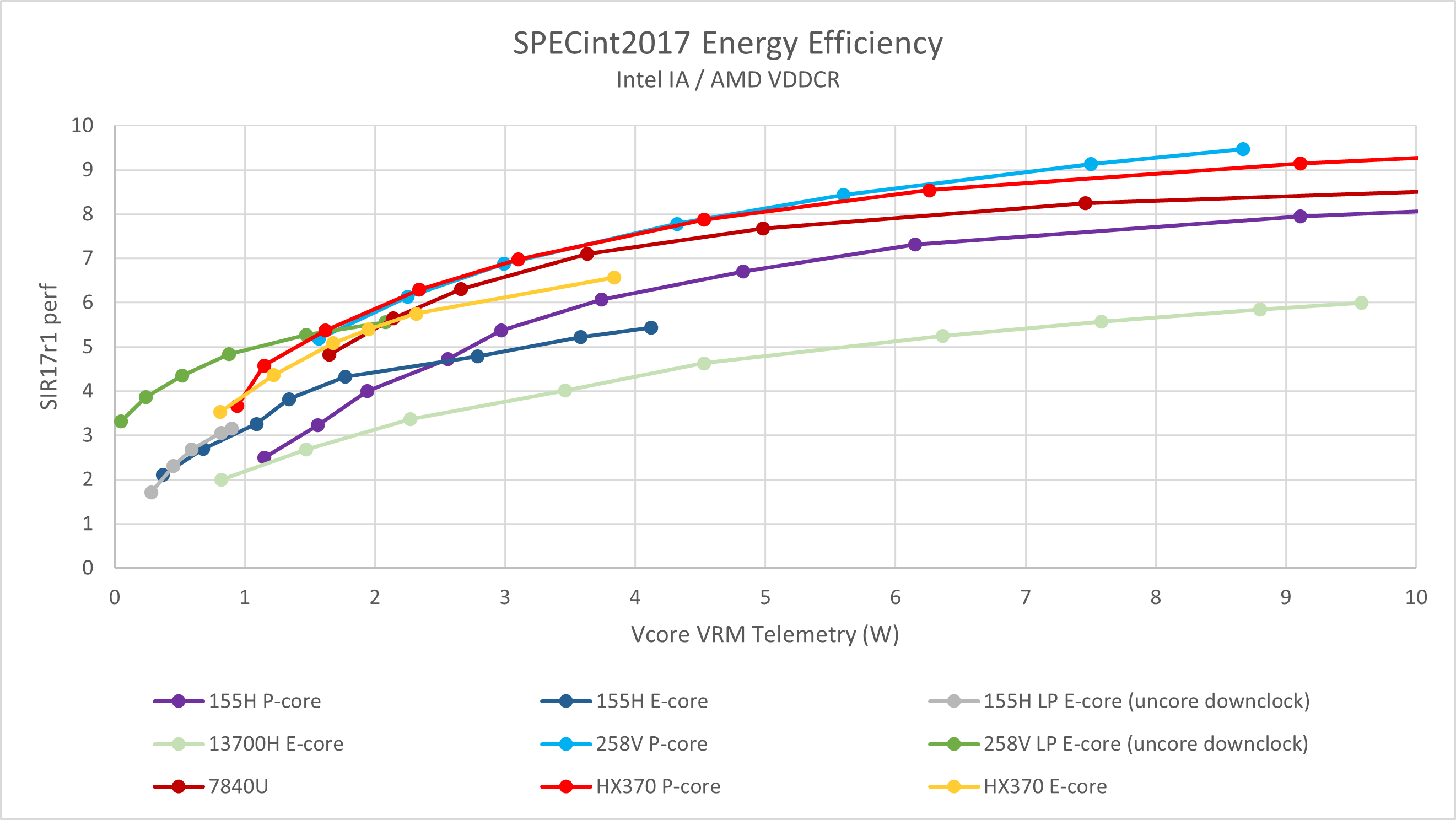
排除SoC uncore影响之后,我们能更好地观测核心能效,并且在不同代的SoC之间对比。
- Lion Cove在4.6 GHz以上相比移动端Zen 5有2-3%的能效优势,4.6 GHz以下与移动端Zen 5相比能效几乎完全相同;
- Skymont LPE在其覆盖的整个功耗范围内性能基本全程遥遥领先所有其他核心,甚至2 GHz下的IA功耗读数只有0.05W;
- 考虑到Intel过去曾经将小核的L2缓存使用uncore FIVR进行供电,我们目前暂时无法确认Lunar Lake RAPL IA功耗读数覆盖小核多少范围以及与其它核心的可比性,因此这一组数据仅供参考。
- 上一代Meteor Lake两种不同工艺制造的Crestmont核心在低功耗下的IA功耗读数接近,也就是说所谓的“Intel 4”工艺的能效在这一区间约等于TSMC N6水平。
- 同样的功耗下,使用TSMC N3B制造的Skymont的性能大约领先前代Crestmont 50%-125%左右。
从结果上看,不论是看Package功耗还是看核心本体功耗,Lion Cove的能效曲线都与Zen 5几乎重合,相比前代Intel大核心进步明显。但这个表现并不那么令人满意,主要考虑到以下因素
- 领先一个大节点(N3B vs N4P)
- 使用类似Apple Silicon的更有利于低功耗的PMIC供电(vs 传统VRM)
- 极限性能、IPC等关键指标并没有明显优势
在这样的情况下,一个优秀的微架构设计理应做到明显优于竞品的功耗表现,例如Apple M3/M4的单线程能效和性能就远比Strix Point要强。但Lion Cove的表现却只是做到了M2的性能与M1的能效。
另一边的Skymont相比上一代ring上的Crestmont略有性能/能效提升,低功耗下提升更为明显。
需要注意的是,目前版本的Linux下Lunar Lake的uncore频率跟随大核频率变化(Windows无此问题),这导致单独给小核跑负载时内存性能偏低,影响测试成绩。在测试极限性能时我们可以在大核上跑一个main() {for (;;){}} 实现测出最佳内存性能时的小核表现,但测试能效时由于大核必须完全闲置,我们只能测试uncore降频的能效曲线。
考虑到小核本身的现实世界用途是低功耗,这样测试倒也不是没有道理。不过当uncore频率表现正常时(例如Windows下),小核能效曲线末端并不会出现与大核能效倒挂的现象。
无论如何,这都代表Intel一雪前耻,为Windows高端笔记本用户带来了不输AMD的单线程高负载能效与显著优于AMD的低负载功耗。
多线程能效
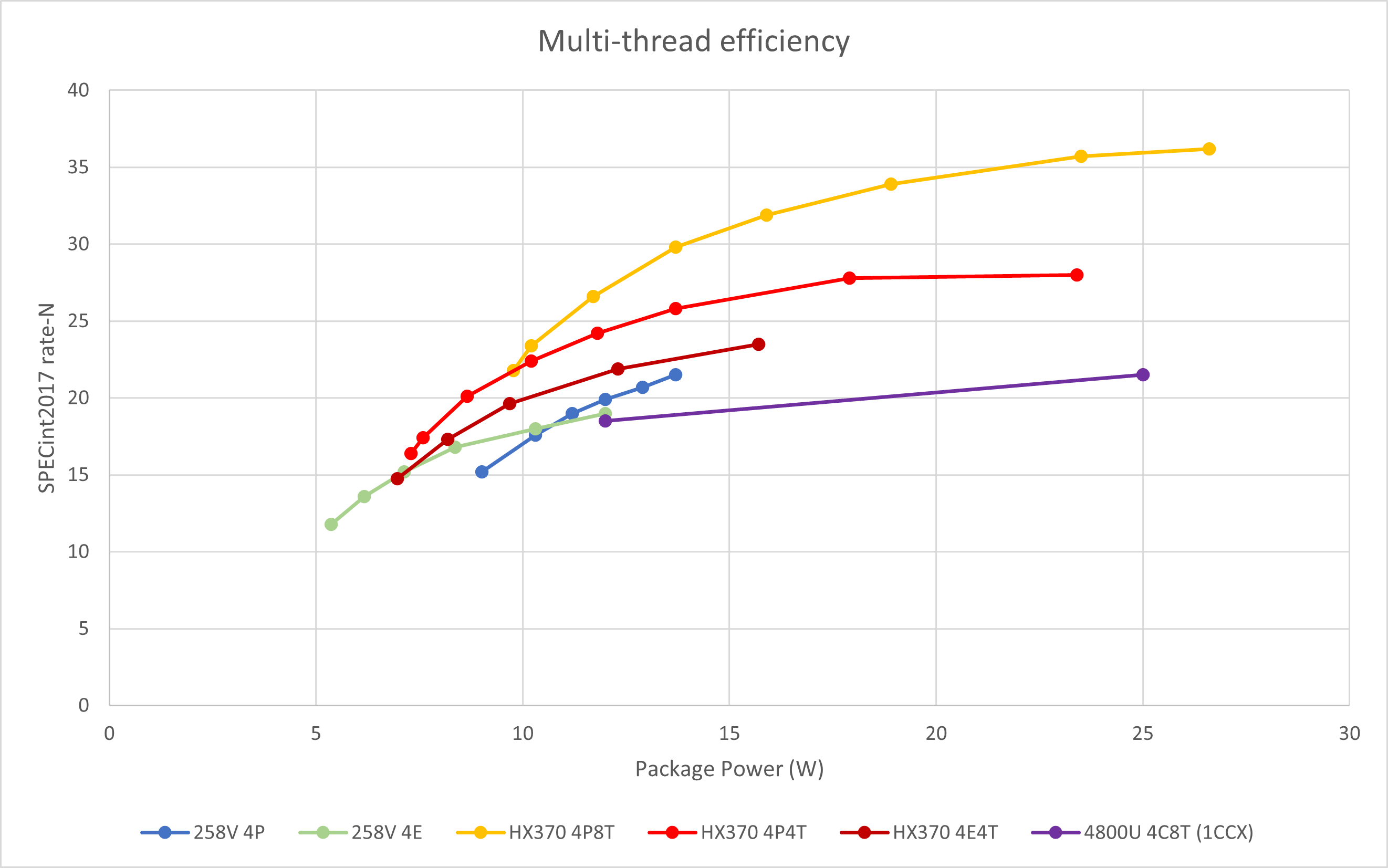
在高功耗段,Lunar Lake的多线程性能与能效明显不那么好看。特别是Lion Cove在全功耗段都表现出非常差的性能与能效:由于测试平台的局限性,全核频率大约只能稳定在3.8 GHz左右;而在这个频率下,4个Lion Cove核心也只能发挥同频单核的2.7倍性能。在这个范围内哪怕是不使用SMT的4核心Zen 5甚至Zen 5c也能大幅度超越规模相近的Lion Cove。
Skymont LPE在低功耗下的表现则是亮点。虽然图中Strix Point的曲线范围没有完全覆盖,但可以看出4个小核在低功耗下能效超越Zen 5的趋势。4核心Skymont LPE在高功耗段与4核心Zen 2 (Renoir)的表现相近。
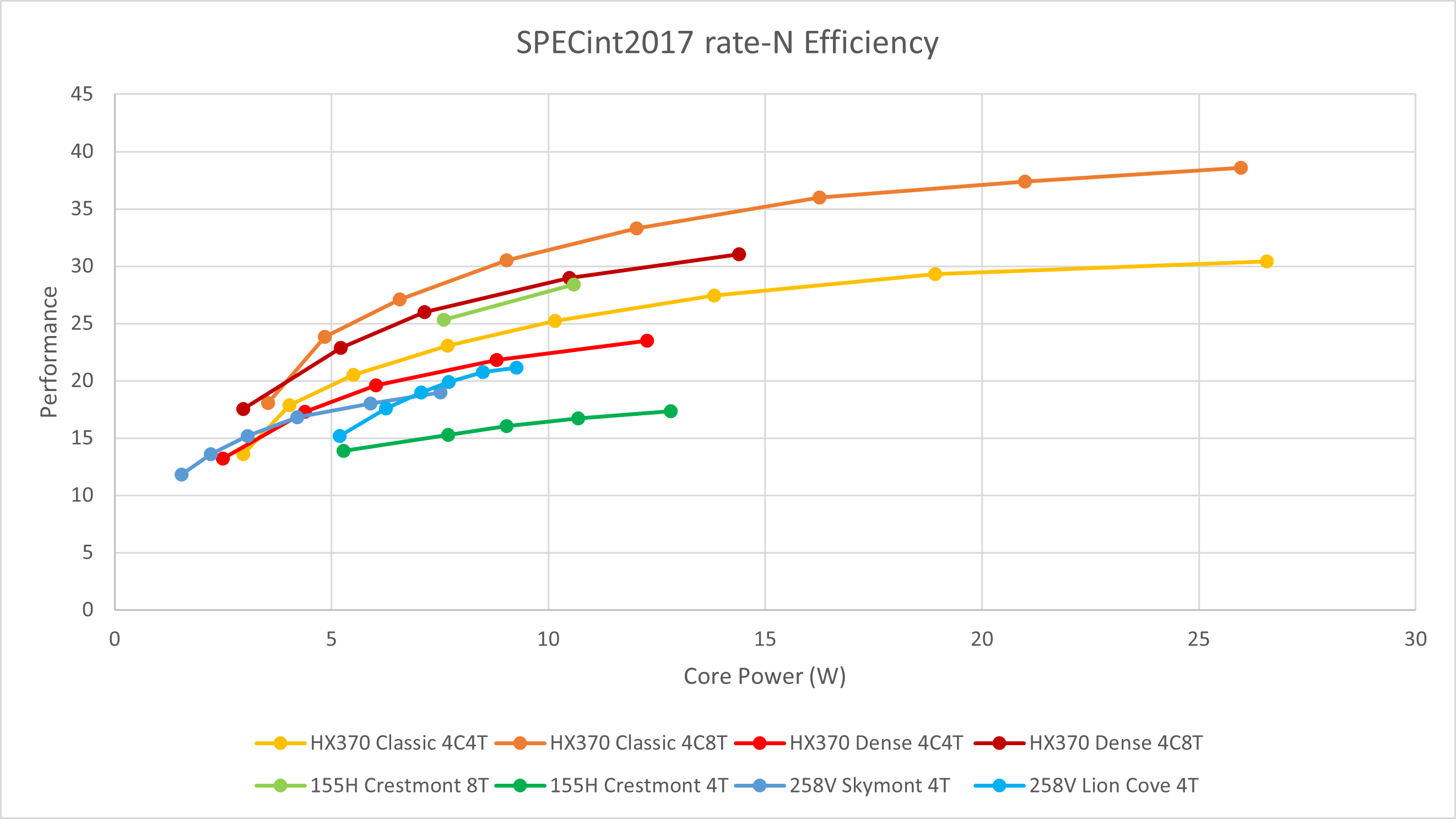
而当我们把目光转向仅限核心的功耗,则可以观察到更有效的数据。这里我们引入前代Meteor Lake的Crestmont核心的数据,并且将HX370的数据替换为Zen 5c核心进行对比
- Zen 5c 4核8线程的能效略优于2模块8线程的Crestmont。考虑到单个Zen 5c核心不含L2仅仅只有2 mm²左右的面积而Crestmont为1 mm²且后者有3倍大的L3缓存,这体现了Zen 5c核心不俗的PPA指标;
- Lion Cove依然表现的相当惨淡,多线程性能甚至不如关闭SMT测试的Zen 5c核心;
- 同样是单模块4核心4线程的情况下,Skymont LP E在8W附近相比Crestmont多线程性能提升20%左右。这对于LP E核心来说是相当难得的,毕竟少了24 MB L3缓存,替换为性能较低的8 MB SLC缓存;
- Skymont与不开启SMT的4核心4线程Zen 5c相比各有千秋,在4W以上略逊于Zen 5c,4W以下则略强一些。作为一个缓存更弱、核心本体面积更小的核心,它在这里展现出了一些PPA优势。
当然,Skymont的制程优势也不能忽略,也许使用同为3nm的Turin dense来进行对比更为合适(可惜这个多半玩不到)。
很显然这样一颗SoC是为了低功耗日常负载而非高性能生产力工作而设计,整体表现也符合它的定位。相比之下Strix Point更适合与Arrow Lake-H进行比较。
多线程Scaling
上面Lion Cove惨淡的多线程表现让我非常好奇,因此我顺便收集了Lunar Lake同频的单/多线程性能数据。
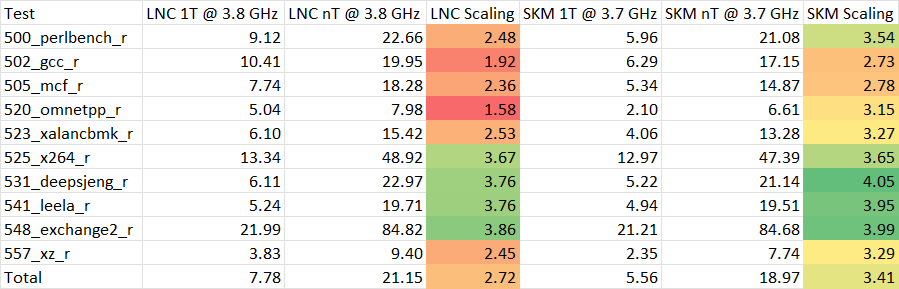
我们可以很容易看出,凡是对内存、缓存访问负载压力较重的测试项里,Lion Cove多线程均体现出了相当差的scaling,尽管它与Skymont相比拥有更强的缓存结构和内存带宽资源。从前文中的测试我们也可以看出,Lion Cove访存的带宽和延迟等并不存在明显问题。
这一现象可能可以归结为早期BIOS固件、系统支持不成熟,也可能是本身设计使然,有待后续进一步测试。
待机功耗
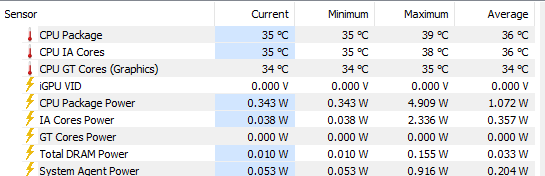
Lunar Lake除了高负载的能效改进巨大之外,其低负载下的待机功耗也非常优秀。上图是Lunar Lake在Windows桌面静置时的hwinfo功耗读数。
从上面的这些测试结论里我们可以看出,Lunar Lake无论是大核、小核的高负载能效,还是静置下的待机功耗,都是非常优秀的水准。可以预期的是Lunar Lake会成为x86的续航王者,并且很长一段时间内不会被超越。
总结与评价
在这样一个新的产品出现时,我们自然也要分别评价产品本身以及对Intel本代产品、未来发展的整体看法。
Lunar Lake
如果要用一句话来概括Lunar Lake,那么我会说它是高端Windows笔记本PC的强心剂。在Intel多年饱受高功耗、低续航困扰,且Intel以外的竞品如AMD、高通等进军高端笔记本多年也并不顺利的情况下,Lunar Lake的出现为Windows高端轻薄本重新带来了生机。
毫无疑问,如果你对Windows/Linux PC阵营类似MacBook Air定位的产品感兴趣,那么我会向你推荐Lunar Lake高端轻薄本。如果你对多线程性能有任何需求,Lunar Lake则没有Arrow Lake合适,尽管日常体验方面它的表现确实会更好。
不幸的是,尽管有这样一个定位清晰、表现优秀的产品,Intel的市场部门似乎依然永远无法停止他们那厚颜无耻的整活行为。尽管Lunar Lake定位类似iPad、MacBook Air的低功耗移动设备,他们依然试图使用Lunar Lake去碰瓷其他高性能平台的性能,以便把不懂电脑的小白忽悠去买不适合他们的机器。在Intel Lunar Lake Tech Day和Hot Chips 2024之后,我还在Twitter评论区公开赞扬Intel展示的数据与我所实际测得的数据高度一致,比隔壁AMD整天只知道AI AI AI要有干货得多;谁又能想到9月3日的Lunar Lake正式发布会上我能看到如此震撼人心的内容。
Intel在9月3日发布的宣传材料以及媒体通稿里至少有以下几点明显的问题:
- Intel声称Lunar Lake的DRAM延迟是90ns,比前代Meteor Lake、竞品Strix Point分别低40%和30%;
这是一个非常无耻的偷梁换柱行为,甚至与Intel自己此前Hot Chips的数据相矛盾,专门忽悠电脑小白。
Intel在footnote里提到90ns的延迟使用AIDA64测得,但Meteor Lake、Strix Point的数字来自第三方,使用的是别的工具。真实的内存延迟水平如Intel的Hot Chips PPT与本文所测得,Lunar Lake相比Strix Point并无明显优势,相比Meteor Lake有提升但也只是低了25%左右。 - Intel声称Lunar Lake的SPEC int 单线程整数性能比Strix Point高21%(相比X1E78100提升+33% vs +61%)
Intel在其网站页面上并未给出竞争对手的详细的编译器参数和测试报告,而不提供编译器参数细节的SPEC测试可以基本被认定为无法复现的无效测试,其成绩操作空间极大。
这项测试的结论也与本文严重不符。本文的测试里使用不偏向于任何一方的编译器参数和系统环境时,两者同频性能非常接近。 - Intel声称Lunar Lake“相比前代最高3倍的Performance Per Thread”
实际上是做了类似ARM服务器喜欢做的事情:通过消灭超线程来“大幅度提升” “每线程性能”,而不是老老实实与前代同等规模处理器,比如关闭到4+4无SMT的Meteor Lake,进行对比。想不到2024年的Intel也会堕落到玩这种文字游戏。 - Intel声称Lunar Lake在Geekbench AI CPU测试里的性能大幅度领先Strix Point
实际上Intel使用性能最好的OpenVINO CPU模式测试Lunar Lake,使用性能较差的ONNX CPU模式测试Strix Point。当二者使用相同模式时(OpenVINO CPU推理也支持AMD处理器),Strix Point比Lunar Lake的性能大约高出60%甚至更高(取决于功耗墙) - Intel使用的Strix Point测试机正好是我目前使用的这一台华硕Zenbook S16 OLED(也就是灵耀16 Air),而这是市面上能找到的性能、散热与供电效率最差的Strix Point机型,没有之一。
这不仅影响功耗墙和多核性能上限,也会影响同功耗下的效能与单核性能。譬如,同为HX 370的散热良好机型,其运行Cinebench单线程可以稳定在5.15 GHz,而Zenbook在长时间高负载的单线程应用里会降频到4.8 GHz附近。而哪怕固定在28W的功耗墙下,Zenbook的多线程跑分与核显游戏性能也远远落后于其余所有Strix Point机型。
华硕在这一台机器上为了极致的厚度牺牲性能和效率可以理解,我正是看中这一点才选择购买这个型号。但这是一个相对小众的昂贵产品,其余任何Strix Point机型并不是这样。因此Intel的营销材料里所有与HX 370相关的性能测试都是故意找的完全没有任何普遍参考价值的极端案例。
前阵子看到有网友开玩笑说Intel的核心技术是营销,当时我还不怎么当真。但在看了Intel对Lunar Lake的营销里这么多神奇操作之后,我也不得不思考这样的说法是否真的有一定的道理,毕竟Intel最近刚刚宣布大裁员,其搅混水的营销能力却丝毫未曾减弱。
Intel
对于整个Intel来说,Lunar Lake虽然表现出色,但它所展示的并不完全是一个好的兆头,反而让我们看到了一丝隐忧:
- Lunar Lake的能效与续航用了非常大的代价才得以实现(先进工艺+高级封装+定制PMIC),并牺牲了绝对性能。这使其脱离一部分对性能有需求但又不追求极致轻薄续航的主流、价格敏感型用户;
- Intel未来数年没有接替Raptor Lake H45的廉价产品路线图。现今13500H的竞争力和毛利率已经非常惨淡,竞争对手又会连续多年更新主流价位的廉价SoC型号;
- Lion Cove作为Intel的主力大核微架构,虽然是全新的微架构设计并且有不少亮点,但依然能看到Intel与Apple、AMD等厂商的微架构设计实力差距大到甚至连领先一代工艺都补不回来;
- Skymont小核虽然进步巨大,但是性能与大核架构的差距依然客观存在,且作为一个相对偏科的选手暂时难以完全扛起大梁。坊间传闻还经常有Intel内斗导致Atom团队拿不到高性能核心的项目的故事。
虽然这些与Lunar Lake产品本身的表现没有任何关系,并不能作为对产品本身的批评,但它也确实是这个产品折射出的一些现实问题。
不管Intel的未来如何,这都不能否认Lunar Lake作为一款高端产品的整体表现非常优秀。而性能更强的Lion Cove、Skymont核心也将会跟随着Arrow Lake走入我们的视野,期待后续的测试可以让这些新的微架构发挥它们最强的性能。
您好,我是数码博主维生素P,请问是否可以授权转载这篇文章?
您好,我是数码博主维生素P,请问是否可以授权转载此文章到知乎专栏等其他个人平台呢?标题会标注转载,并且在开头第一段可以按照您的要求标准一段转载说明的文字。
可以,只要清晰注明来源即可。
真棒
您好。我看到您说zen5移动端的那个package功耗是假的,那么您认为lunar lake这个package功耗是真实的吗?
以我本人的业余测试条件和能力并不能证实或者证伪功耗读数,需要更专业的竞品分析环境才能做到精准的功耗测试。不过如我在正文中提到,Lunar Lake的package功耗在Linux下也是偏高的,这是由于测试时的Linux版本尚未完善支持电源管理,有许多外围IP的电源管理固件等没有正确加载。
相对而言本测试里的IA/VDDCR核心功耗读数会更有意义,不过整体参考价值依然比较有限,知乎有人详细讲过各种功耗测试手段可能存在的一系列问题。总之这一块的分析都仅供参考,只能粗略说明一个大致的相对关系。
当二者使用相同模式时(OpenVINO CPU推理也支持AMD处理器),Strix Point比Lunar Lake的性能大约高出60%甚至更高(取决于功耗墙)
— 应该是核心数和avx512指令集的区别导致的。
也不完全是,首先Zen 5移动端的AVX512-VNNI吞吐与AVX-VNNI相同,不像桌面有两倍的吞吐。其次Lunar Lake同样核心数且同功耗下跑各种多线程应用的性能也不是那么的占优,可能需要具体测试才好判断原因。
你好,我能询问一下跑多线程的时候hx370的频率分别是多少?
Package Power 和 Core Power 两个图里的Zen 5各有8个点,前者从上到下是28W默频、4000/3600/3300/3000/2600/2200/2000 MHz,后者是28W默频、4200/3800/3400/3000/2600/2200/1600
Zen5c有5个点,Package Power是3300/3000/2600/2200/1800,Core Power是3300/3000/2600/2200/1600。
除此之外Package Power的测试里用的是znver4的数据,Core Power用的是znver3,且两次测试的时间间隔较久,后者是前不久才补上的。因此可能会有细微的分数差距。
大佬,和你之前测的这张7735U的单线程能效图对比,是不是可以说LNL在5W以内的单线程能效是不如7735U的?
https://pic3.zhimg.com/100/v2-e0061653e6a81969c758cca62e3f6968_r.jpg
抱歉,刚刚附的图错了不完整,是这张
https://pic1.zhimg.com/v2-cf1268b7ea199d540d3ff49a54557628_r.png
使用正式支持Lunar Lake之后的Linux应该不会,现在是因为电源管理不完善所以package功耗偏高(Strix Point也有类似的问题)。如果只看Core Power那么Lion Cove比7735U强。
谢谢
LNL在文中提到的package功耗是不是包含了内存功耗,实际CPU部分的功耗会更低?
Intel的RAPL接口可以读出DRAM功耗并且我有收集。由于本文主要是进行整数测试,对内存的压力较小,实际DRAM功耗读数从未超过package功耗的1%,因此在review过相关数据后我选择将其忽略不计了。
纯CPU部分的功耗可以参考IA/VDDCR的那张图。
大佬做过含7735U数据的IA/VDDCR图表吗,想看一下纯CPU能效下的新王旧王对比
纯看核心功耗的话Rembrandt跟后面几代并没有什么明显的优势,他的优势主要是相比Phoenix的SoC uncore电源管理。
掌机用这个U是不是非常好
Ecore实际执行的是2C/Cluster 直接服务器设计ip填充,另外一切以电源岛分区为核心降低不必要的功率支出 ~~主导LNL项目处理器电源设计工程师
英特尔这个每线程性能的营销说法真是厚颜无耻,很难想象这是一家有着悠久历史的大企业能干出的事,简直侮辱消费者的智商,也难怪会请杨笠这种完全不沾边的人作为代言,这家公司实在是烂透了。
大佬,这个zen5c相比zen5面积小了不少,但是实际能效似乎并没有相比zen5有显著优势,感觉amd的这个c核心更多是成本考虑而非能效考虑。
请教:
1、Lion Cove,几级BTB分别多大(个人了解有限,从测试图无法直接推出来)?
2、SPEC2017是否有Qualcomm OYUN的分数,我这边有WoA平台,是否方便提供APP或binary?
从microbenchmark中可以观测到的BTB最大容量相比Raptor Cove变化不大,但是在不同跳转距离上的观察到的有差异。考虑到每一级BTB都是越密集存储的分支数量越多,推测是带有一些压缩,实际表项容量会小于观测到的值。
L0: 32 (稀疏) – 256 (密集)
L1: 1K (稀疏) – 8K (密集)
L2: 3K (稀疏) – 12K (密集)
关于Oryon之前我也解释过,自从Windows 11 22H2之后Windows / WSL2经常能观察到非常明显的性能regression,例如此前我测试Lunar Lake在WSL2里甚至表现不如7840U,Strix Point在WSL2里不如7735U。因此Oryon我打算等什么时候有可以安装原生Linux的成熟方案之后再去做评估,可能等那个4.3GHz频率的devkit可以买到之后我会去买一个测试。
明白了,thx~
你好,请问这代strix point大小核之间的延迟问题有希望得到解决吗
据我最近了解AMD现在根本没把Strix平台的ccx延迟这个问题当一个bug看待。
可是180ns这个级别已经是内存的延迟时间了吧,为什么桌面端可以通过agesa修复但是只有四大核的移动端反而不重视😂
对于N3B领先N4P一个大节点这观点恕不苟同。原因为下:
1. INTC最后一代使用HD library的core架构为Nahalem,从Sandy bridge开始一律使用HP library,直至现在。与此同时过去13年,Intel从mobile到DT再到server平台的library皆为一致,故不存在Lunar lake使用HD而Arrow lake-S使用HP的可能性。而根据TSMC官方PPT,N3B HP的logic density仅为N5的1.56x,意味着理论值只有140MTr/mm^2。根据历史数据,从Sadny bridge开始core+L2&L3的average density从未突破HP的80%,故此LNC的density不可能高于112MTr/mm^2,低于Zen 5的120-130MTr/mm^2
2.同代制程的情况下HD在0.85v内功耗一般比HP低10-15%。而N4P相较于初代N5低22%,N3则是低25到30%,意味着最理想的情况下N3B HP只能在0.85v内持平N4P HD,最差情况下则是功耗高13%。这也是为何阁下的测试结果现实LNC在4.5w内IA power持平Zen 5,而更高的功耗段开始优于Zen 5的原因。
最后是我对Lion Cove的看法。基于marketing的原因,INTC在Lion Cove依旧选择确保1.1v+性能的设计,在这种先天劣势的情况下Lion Cove依旧可以在0.65-0.85v有着不亚于Zen 5的表现,足以证明大核团队的设计能力。而局限大核在PPA和能耗比更进一步的根源则在于INTC marketing对于极限高频的执着。我是认为MSDT CPU需要回到10年前那个ST voltage 1.2v, all core voltage只有1.0v出头的年代,从CFL-S开始连all core都动辄1.2v甚至1.3v可以说是埋下了13/14代出现缩缸事件的伏笔。
1. 这全部是你基于过去产品的推测而非任何官方信息,而Intel恰好在本代发过一张PPT讲他们的研发流程改变
2. 作为 >5GHz 的高性能产品,无论是LNC还是Zen 5全都是高度定制化的DTCO节点,早就不能用PPT上ARM Cortex测试片的数据来加减乘除对比完事。
哪怕是同一个核心设计在不同的产品上也会有可以调整的空间(Vt/工艺角等等)。就比如号称同样的tsmc节点,AMD的移动端同频的电压和动态功耗明显高于桌面端(当然是指排除缓存敏感测试),面对同样是N4P的桌面Zen 5全频段高负载能效优势你又准备怎么解释呢?这些对外人来说都是糊涂账,算不明白的。除非你能拿到两家芯片厂商各自内部的一手数据,或者经由专业的竞品分析实验室的分析结论,否则这一切都是靠猜。至于258V高频相比HX370的那点性能/能效优势,实际上还不如两片HX370之间的体质差距大。
单纯从Strix Point和Lunar Lake这两个产品里只能看出Intel Lion Cove团队用了更多的研发成本和生产成本,用到更多的tsmc先进技术却只做出了跟AMD用老一代技术差不多的东西,跟同为N3B的Apple产品差距20%+,是无可否认的工程实力差距明显。
感谢阁下看完我的长篇大论。但阁下的观点依旧难以认同。
1.Intel的那张PPT写的是简化database,实际上的意思就是指架构和工艺decouple,目的就是为了外包。如果在架构和自家工艺高度coupling的情况下,32/22/14/10这过去4代都突破不了HP library 80%这个数字,请问Intel弃用自家EDA而改用业界通用的EDA去layout电路的情况下,是怎么做到比以往更高的effective density?如果能在不严重牺牲频率的情况下提高effective density,我相信Intel这家极其重视利润的企业早就做了。不过就算退一步当作Lion Cove有能力突破80%这个数字好了,X86的极限也不可能突破90%,而140MTr/mm^2的90%也就不过126MTr/mm^2,和Zen 5的120-130MTr/mm^2之间的差距能大到足以被称为完整节点的差距吗?当然,如果阁下要反驳的是Lunar lake和Arrow lake的Lion Cove用的library不一样,那我也确实拿不出证据,毕竟Arrow lake的die shot还无法公布。只不过连AMD都没有选择弄两个版本的Zen 5 classic,我想不到INTC会选择做这种要额外成本举措的理由。至于Arrow lake和Lunar lake用的都是HD library的可能性则为0,因为在ARL-S上用接近200MTr/mm^2的N3B HD在散热上没有半点可行性,250w下的散热压力相当于RPL-S的500w+。
2.Zen 5无疑在全段落下都有着比Zen 4更高的PPW,但这是用规模换来的。即使以Intel恶名昭彰的RKL-S为例,14nm版的Sunny cove在同性能的情况下1.35v内全段落PPW优于CML-S上的末代Skylake,而CML-S上的第5代14nm已经打磨到极致了,显然RKL-S能在能耗比上压制同核心数量的CML-S靠的就是额外的规模。在Lion Cove和Zen 5同为8wide,且IPC极其接近的情况下,阁下会认为Lion Cove的规模明显大于Zen 5吗?阁下上述的观点能成立的前提实际就是基于我上面提出的条件,只有在Lion Cove的核心规模明显大于Zen 5,才能说Lion Cove吃到足足一个完整节点的红利。至于N3B的M3大核就是典型有规模优势的例子,不但有着10wide vs 8wide的优势,而且用的是HD library,在0.85v内有着绝对的优势。
3.我不否认阁下提出两家工艺角等等有差异的可能性,像是INTC有可能会选择用更低的良率换来更高的性能。问题在于当账面数字的差不多的时候,为什么会认为Lion cove能获得的实际收益更大,而Zen 5获得的收益更小呢?像DTCO的问题,假设Zen 4的DTCO只能获得额外10%的功耗降幅,难道Lion cove的DTCO就能获得20%甚至是30%的收益吗?这种假设是不公平的。如果阁下觉得我的数字全都是猜的,那么阁下对于Lion cove和Zen 5工艺上的PPW差距就不是猜测吗?对于Lion cove和Zen 5之间的transistor count差异不也是猜测吗?那为何就能草率地得出两者之间有着完整节点级别的工艺差距呢?如果要猜至少都等比例地去猜,要是觉得猜不准,不谈工艺也是可以的。根据历史数据和账面数据去对比,就已经是主观意识介入最少的对比法了,总比猜没办法参考的东西的误差来得更少。
最后,我不否认Lunar Lake在成本控制上劣于Strix point,正如我先前的观点,N3B既没有相较于N4P有着客观的PPW提升,INTC也未能利用到N3B的density优势去塞下规模明显更大的核心去间接提升PPW,和AMD一起用N4P是更为明智的抉择。只不过为什么INTC要更贵而性能优势不明显的N3B这个问题我是能回答的,因为Lion cove是2021年就用N3B设计好的东西,正如当年流出的roadmap,原定是23年就要HVM。结果N3B delay半年,临时移植到N4P要额外的成本,时间上也不允许,还不如继续用N3B。所以真的是工程实力上的差距吗?我只能说这是结果论而已。像TSMC这种近几年都准时的代工厂在N3B能翻车半年就是难以预料的事情,而这种情况充其量也只能说是营运团队的风险管理问题,不是架构设计师应该要考虑的问题。
1. 减少coupling意味着有更大的可能可以针对特定的产品单独做physical design,无论是面向不同节点还是面向同一节点不同性能/功耗取向的设计。
这一条主要是反驳你说“因为sandy bridge之后所有的产品都是使用相同HP library设计的所以Lion Cove在Lunar Lake上也一定用的N3B HP”。并且在最早的规划里Lunar Lake的Lion Cove和Arrow Lake本身就有所不同(LNL的核心叫LNC+),后者只是因为MTL SoC项目进度不理想导致落后LNL,实际上按照正常进度是要比LNL更早的。
我不知道你看了我文章里的多少内容,从很多细节可以看出LNL的LNC+本来就是专门针对低功耗的设计(比如L3带宽的削减),而且这很明显是RTL级别的微架构差异而不是Zen5c那种单纯physical target改变,因为相比Meteor Lake(以及Arrow Lake PPT数据)的指标出现regression。那么既然连RTL都有了单独的低功耗优化,自然可以推测physical design也要针对低功耗做优化而非生搬硬套Arrow Lake设计,因此你推测LNL的LNC继续遵循Intel P-core的惯例采用N3B HP忽略了无论LNC还是LNL本身就不是一个惯例的产品的事实。
相对应的,AMD也并没有官宣过Zen 5采用原版N4P HD,更像是基于N4P HD做高性能的DTCO,从它本身的实测表现来看相比各种ARM处理器就是在很大程度上牺牲密度和低电压下的能效换取高性能的(减去SRAM之后核心部分的密度也就只有100MTr/mm2附近,远远没有达到N4P标称的逻辑密度。本代CCD上面的面积比例偏向于核心膨胀SRAM微缩)。在没有更多细节公布的情况下两家这方面都是黑盒,单纯用N3B HP vs N4P HD来论证两家工艺实际表现接近我完全不认同。
2. rename宽度只是规模的一部分,事实上对于SPEC int来说6-wide以上很难起到什么实质性的作用,IPC更多还是看流水线各个部分的延迟以及访存的延迟(周期数)而非吞吐,这一点多年前已经有不少ARM处理器验证过了,本代x86处理器从6-wide提升到8-wide普遍也没什么特别大的IPC提升。绝大多数情况下的瓶颈都在别处,哪怕是吞吐最高的子项IPC也不会超过5,对于大部分子项来说只有不到一半的pipeline slot会被实际的指令填满。而你说的“同为8-wide且IPC接近”的后者(IPC接近)是微架构各种参数综合导致的一个结果,而非反过来论证规模相近的论据。
Lion Cove的很多微架构内部结构都比Zen 5要明显大出一截,比如我文章里写的(again, 不知道你有没有看过)ROB,整数寄存器,整数调度器全部比Zen 5大了25%以上,意味着遇到后端stall时可以比Zen 5多buffer 25%以上的指令,这一点对于cache/memory latency sensitive应用来说极其重要;还多了一层L1.5和相比Zen 5巨大的L2对一部分cache latency sensitive的子项会有比较大的帮助。这些都是明显有助于提升SPECint性能的微架构层面的规格优势,也是Intel要么利用更大的核心面积要么利用N3B密度优势实现的规格优势。
二者规模更接近的反倒是浮点部分,但是Lion Cove在这方面也不是完全没有规模优势,比如它128/256-bit粒度的向量load要比AMD高出50%,而Zen 5只有采用AVX-512才能完全利用上向量load带宽(strix point还把它砍掉了),在SPECfp或者Cinebench之类的测试里更细粒度的向量load store表现要远比粗粒度的更好。
3. N3B进度翻车并不代表拖累了Intel的进度,因为Apple去年就推出了从A17 Pro到规模巨大的M3 Max的完整N3B产品线,而同期Intel连Arrow Lake所依赖的Meteor Lake SoC平台都还有几百个bug没修完,基于它的平台开发的下一代N3B产品更是无从谈起。按照最早的规划Arrow Lake比Lunar Lake发售早至少小半年,结果因为Intel自己的原因活活拖到今年Q4。Lunar Lake反而是照常按照最早的PPT在走正常的进度,因此实际上你看到的Lunar Lake已经是SoC升级一代、核心半代refresh后的产品。
礙於篇幅和严重分歧的关系,工艺的东西就不再坚持争论了。以下只针对阁下有一项明显错误的见解作回覆。
很遗憾阁下依旧没有发现自己在L3部分的出错,反倒将错误的测试结果是用作反驳的证据。当阁下在Lion cove cluster上都能测出40-50ns级别的core to core latency我就确信L3是降频了(尽管阁下说没有降频,但我认为更像是侦测软件出错了)。像Andreas Schilling和笔吧评测室测出来的core to core latency都是和INTC在hotchips上的那张PPT吻合,P/E cluster内皆低于30ns,而跨cluster为55-60ns。因此我从并没有信纳阁下L3这部分的数据。再加上chips and cheese测出来的数据则是Lion cove只有ST read only的情况下L3 bandwidth下降,但read+modify+write完整的情况下则是略高于Redwood cove,MT则是所以条件下全段落高于Redwood cove,因此这种部分ST bandwidth下降的情况是否只属于Lunar lake平台我是表示怀疑的态度。
core to core latency 我用他们测试的工具(nviennot/core-to-core-latency)可以复现跟他们一样的数据,因此硬件肯定是ok的。不过这个工具是每次先启动新线程再分配cache line的best case,而我展示的数据一直是worse case数据,与以前的anandtech比较类似,具体区别我记得anandtech有讲过。
ST带宽我确实是测的read-only,但是即便看这一部分也足以说明Lunar Lake与Arrow Lake的区别,因为read-only带宽是一部分场景非常重要的指标(这个等Arrow Lake发布之后我可能会简单再发点数据提一嘴)。
好像在hot chips QA问cache coherency的那个问题提了一嘴这个SOC中用了snoop tag技术的,不确定小核是否用了这个技术,一些别的博客认为小核是用了的,但是您的逆向结果是没有2333
Intel PPT的X Elite续航也有问题(用的是整机功耗倒数第二差的无畏Pro 15,日常使用整机功耗比Surface Laptop 7高了至少2W)
上面講 HP, HD 的部分, LNL 因為目標明確 而且重點的確是在ldle to low usage 的狀況下, 二選一時會選HD 的Library 應該是基本的, 甚至很可能會回去 IBM, DEC, Intel 火拼時代 利用工程師能力優勢 特定電路搞手刻, 這對於選 N3B 來說也是更合理的選擇 充分利用 N3B 的可能性, ARM 的 Business Model 和 Intel 本質上差距太大, 這甚至會直接影響某些Logic 的演算法選擇
放棄SMT 對於部份手刻流程應該是有幫助的
博主分析挺好的,有些测试项的测试工具找不到仓库,博主能开源吗,我想自己也去尝试一下。
大部分的微架构测试是用的 https://github.com/clamchowder/Microbenchmarks/ 里面有一个AsmGen项目生成测试代码。我只在测试范围上做出了一些修改适应这些微架构的实际结构大小范围。
感谢博主分享,我在尝试修改
博主,我找了部分测试项的代码,这里涉及的测试工具博主有开源计划没,我想到ARM平台上也去尝试测试一下