简单举例讲一下Linux的调度器是如何顾此失彼,以及一些硬件厂商的贡献者和维护者不在乎feature是否真的工作,造成用户困扰的。
(2024/12/04 更新) AMD发布了kernel patch修复这个问题
又到了久违的Linux内核闲聊时间,一看发现距离上一篇跟LACP有关的吐槽竟然已经过去了4年。这也并不意外,毕竟如果不是迫不得已,我对Linux内核的兴趣只能说是低到不能再低。然而Linux在令人失望这方面从来没让人失望过——时隔多年自己亲手翻阅理解代码并debug的时刻再次到来。
背景
不关注硬件的朋友看到本文的标题可能是一脸懵逼:普通人显然既不知道什么是ITMT调度器,也不知道什么是多簇处理器。那么在正式开始之前我们先交代一些背景。
ITMT调度器
从2016年Intel推出Broadwell-E以来,桌面处理器迎来一个新的时代:只有一部分核心能运行在最高的频率。因此,在操作系统内核对线程进行调度的时候,优先使用这些更快的核心能带来更好的应用性能。Intel将这项技术称之为“Intel Turbo Boost Max Technology 3.0”(ITMT),其在Linux内核中也使用了ITMT这个简称。2019年的AMD Zen 2处理器带来了相似的技术,官方标注的最高频率只有特定的两个核心可以达到,AMD将其称之为“偏好核心 (preferred cores)”。而AMD近期针对Linux内核也终于添加了偏好核心调度支持,使用了与Intel相同的ITMT调度器。
多簇处理器
现代多核处理器由于核心数量较多、互联设计较为复杂,并非都是理想的SMP处理器:在不同的层级上都对核心可能存在分簇的设计,使得一部分核心之间共享局部资源且距离更近,与其它核心分离且距离更远,一组共享局部资源的核心称之为一个核心簇。这样的设计在ARM SoC进入大小核时代后常见,x86桌面处理器则是以AMD推土机、Zen等微架构为代表。
问题场景
本次我遇到的问题,则是在我几乎所有的基于AMD处理器的Linux系统上,ITMT调度器都无法正常工作:按照ITMT调度器原本的设计,单线程应用会优先使用性能最强的核心,只有当这一部分核心负载较高时才会使用其它的核心;然而现实中的表现更像是“随机选核”,调度显得毫无章法。
如果只是在普通的AMD桌面处理器上,我也许完全不会在意这个问题,因为性能最强与最弱的核心之间差距不过5%左右。然而,当我给引入大小核的最新移动端处理器HX 370安装Linux后,我终于无法再这么忍耐下去:Linux似乎更喜欢小核,几乎任何情况下都会优先使用小核心而非大核心。而HX 370大核的频率比小核高出50%,且缓存大一倍,性能差距明显,ITMT调度器不再是桌面处理器那种可有可无的优化。
这并非我一个人遇到的问题:在Geekbench 6 Browser中搜索“HX 370 Linux”可以发现,这款处理器几乎所有Linux下的测试结果都只有2000分左右,而Linux下正常的Zen 5 @ 5GHz的性能在3100分附近。
因此我决定一探究竟,尝试自行解决这个问题。
现象
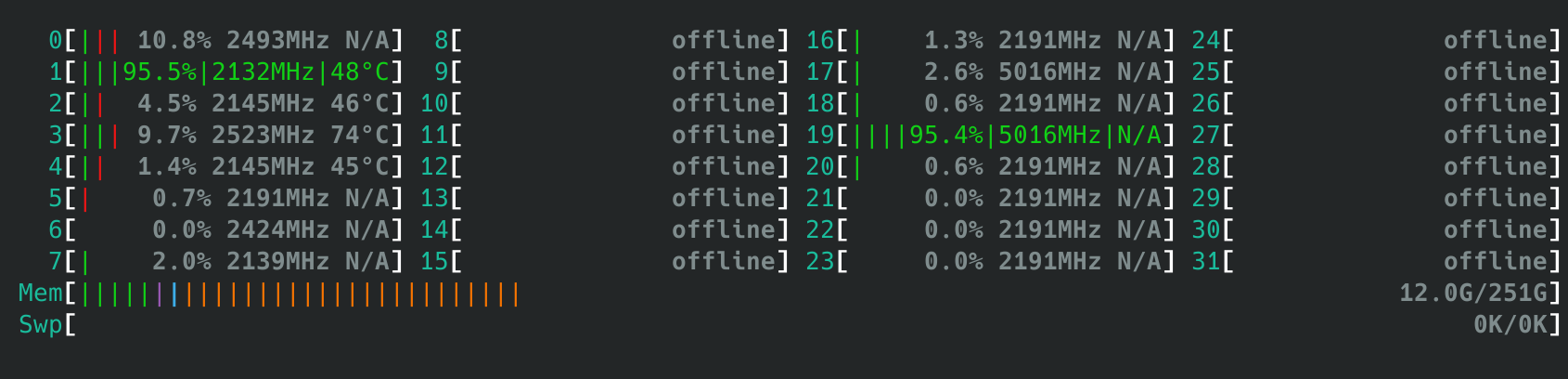
首先我们对故障表现进行更为详细的观察。以我的7970X为例,在6.10内核上查看它的核心拓扑和偏好核心优先级如下:
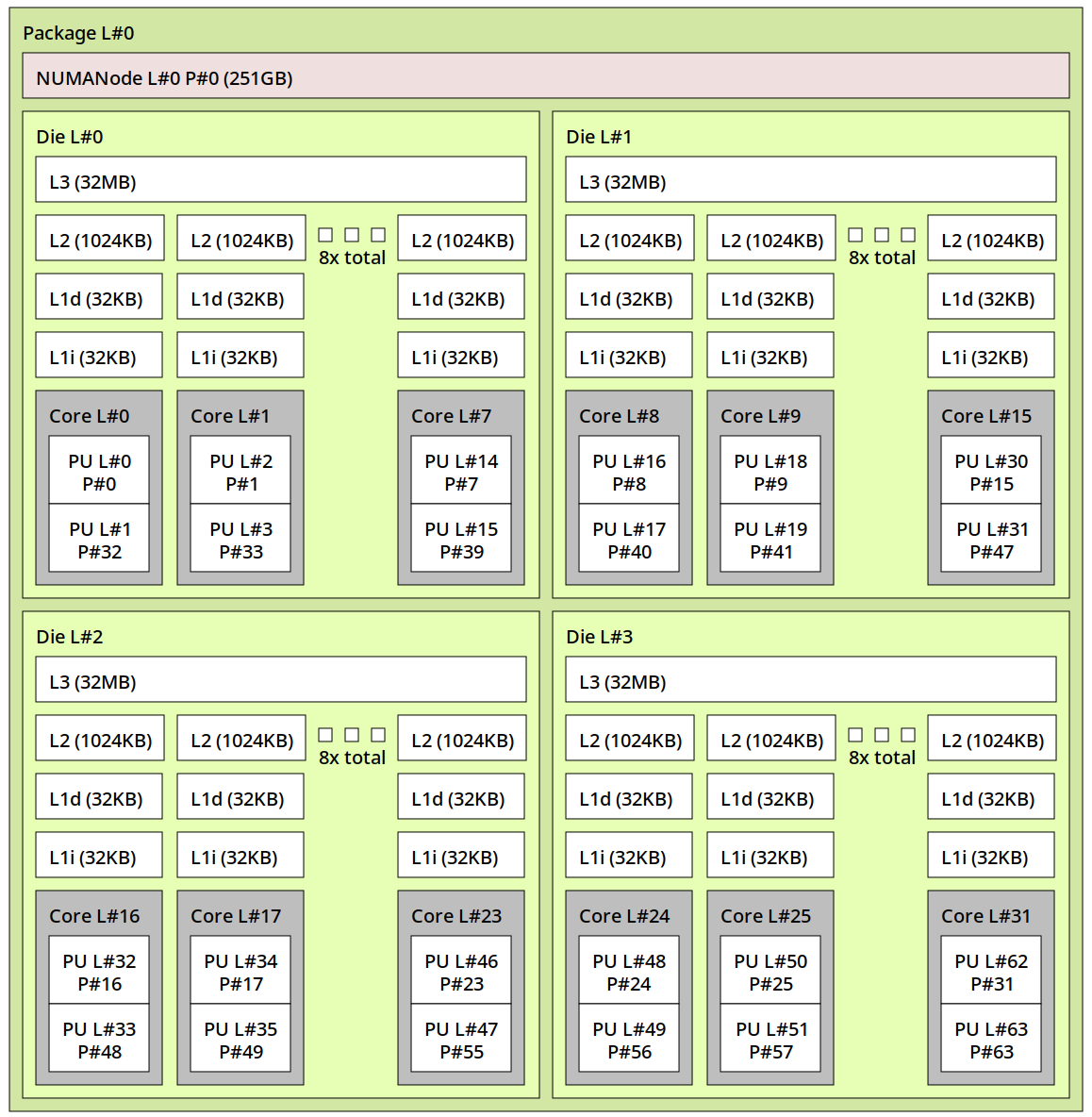
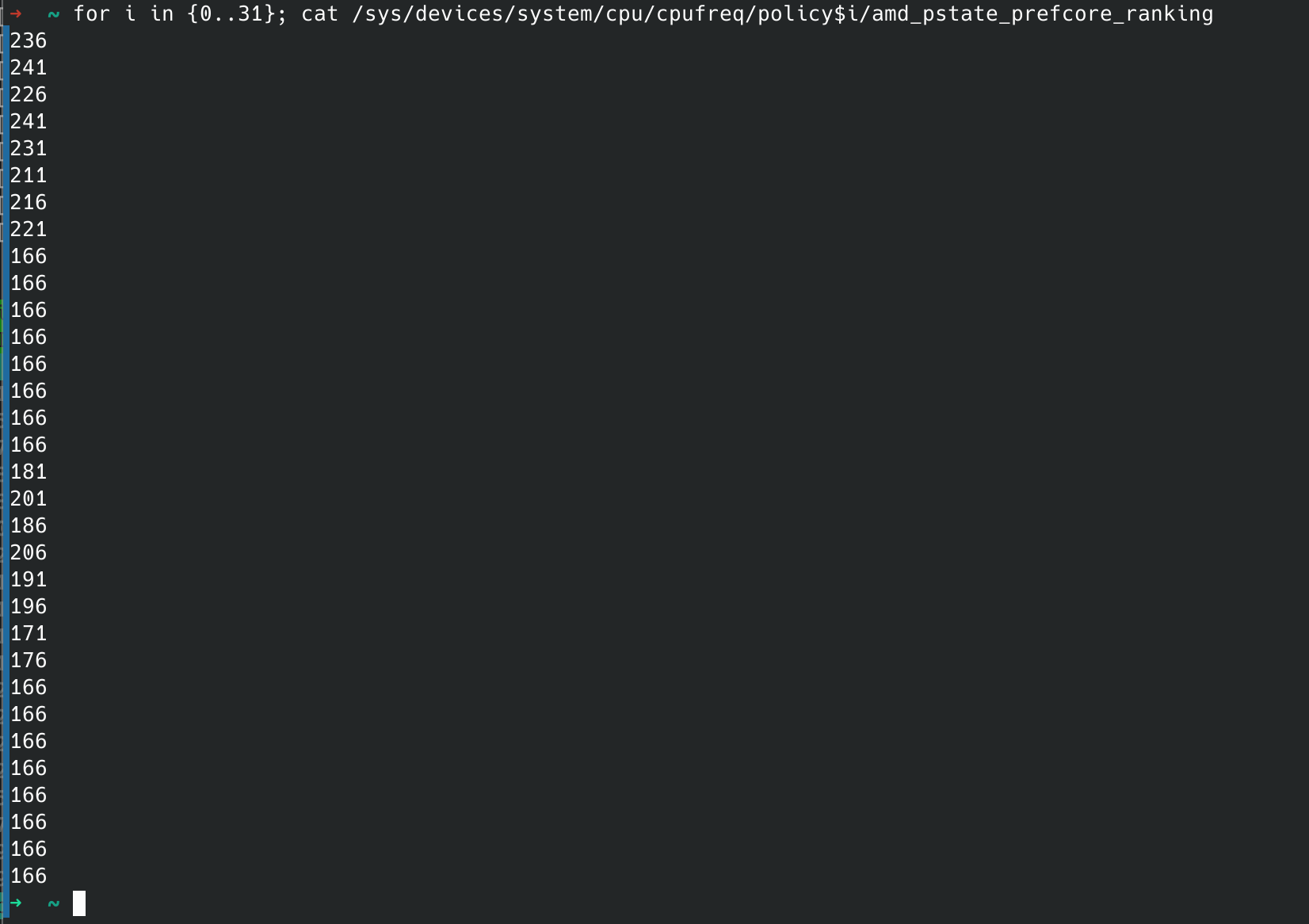
7970X总共有32个核心,由4个簇/CCX组成,每个簇8核,也就是核心0-7属于CCX0,8-15属于CCX1,16-23属于CCX2,24-31属于CCX3。
从prefcore ranking中可以看到核心1、3是排名最高的核心,其次是0、4、2、7、6、5这些CCX0的核心,在这之后是8个CCX2上的核心,最后CCX1、CCX3上的核心都是相同优先级的最慢的核心。
通过一个简单的负载 “7z b -mmtX” (其中X为线程数量)我们可以简单测试单进程多线程应用的调度行为。正常情况下,单、双线程负载应该优先在CPU 1、3之间调度运行,4线程负载在0、1、3、4核心上运行,8线程负载占用核心0-7,16线程负载占用核心0-7与16-23。
然而实际观察到的却是完全不符合预期的行为:
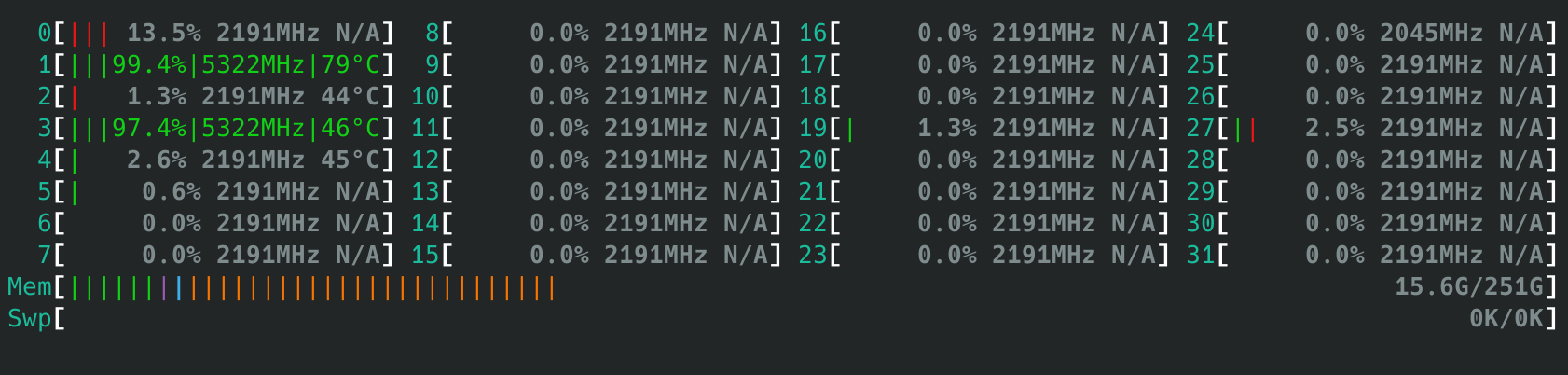
- 默认情况下,单线程应用随机在不同核心之间切换
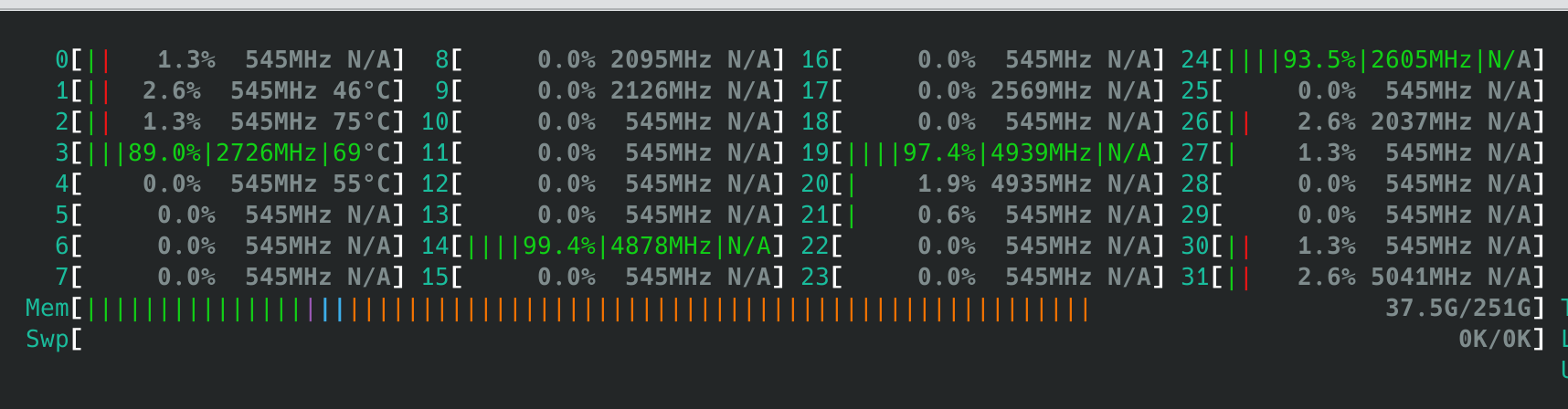
- 多线程应用均匀分布在不同CCX之间,例如4线程的测试会如下图在每个CCX上分配一个线程
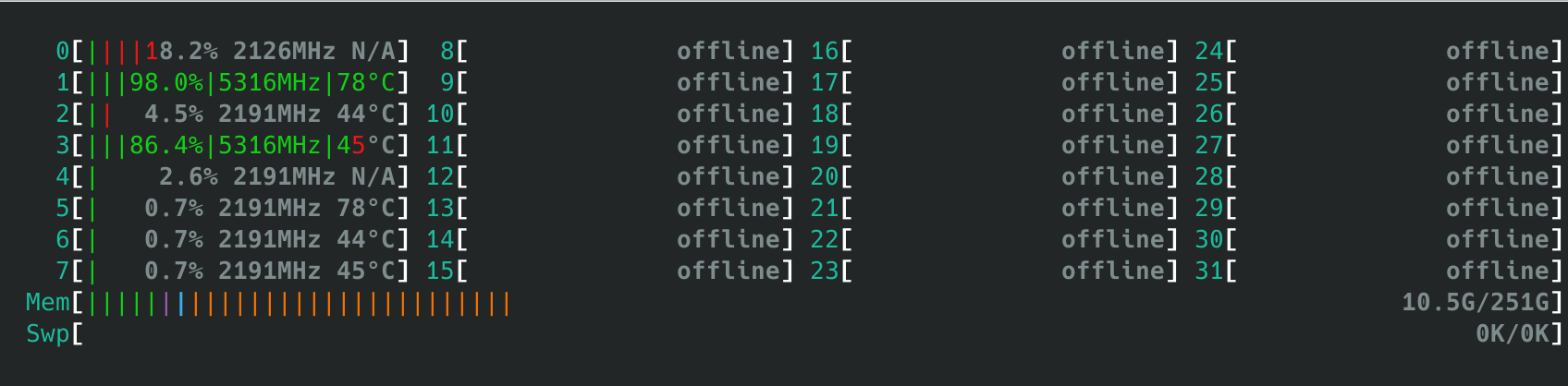
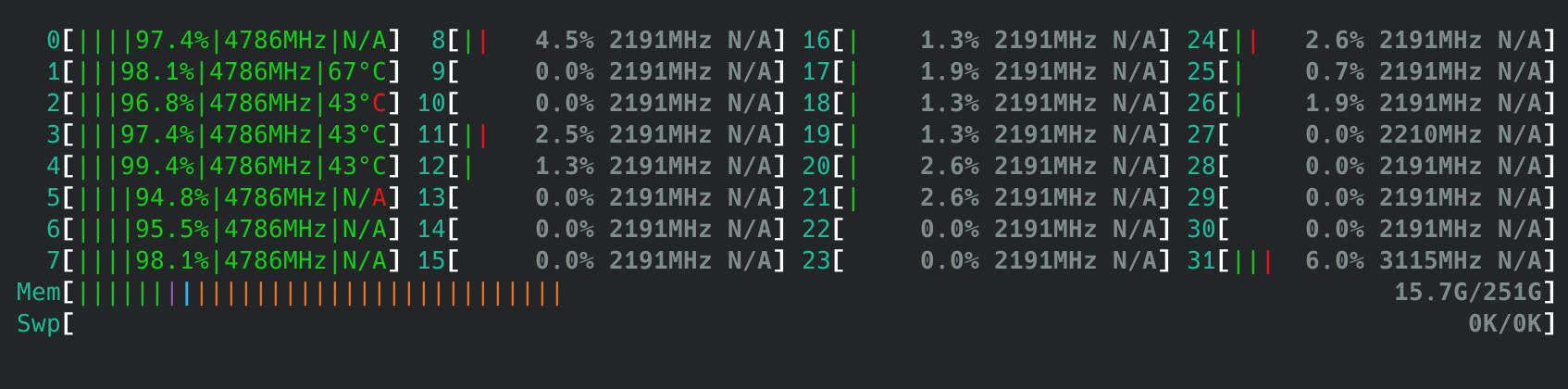
- 当我们关闭后3个CCX,仅保留CPU 0-7时,运行双线程调度器能正确选择性能最高的两个核心
- 进一步观察,如果我们启用CCX0与CCX2,也就是CPU 0-7, 16-23,那么运行单线程测试时会观察到调度器随机选择CPU 1/3/19,而双线程测试则是固定两个CCD各自调度一个线程到其中性能最高的核心上
- 最后,我们在一台Lunar Lake笔记本电脑上运行这个测试,发现尽管小核脱离了大核的核心簇,它却并没有相同的问题:任何线程数的测试都会优先使用大核运行。因此这是AMD专属的问题。
分析
显然,尽管Linux 6.10已经支持且默认启用了AMD平台的偏好核心调度,且ITMT调度器工作正常(kernel.sched_itmt_enabled为1),但在7970X上它并没有完全表现出预期行为。此前9950X、7950X3D、以及HX 370也可以观察到类似的行为。
但同时我们通过关闭部分CCX测试又可以看出,ITMT在单个CCX内部可以正确选择性能最高的核心,只是在ITMT调度逻辑介入之前有一个更优先的逻辑是将线程均匀分配在不同的CCX上,且对调度器而言每个CCX都是对称的。
查阅Linux源码,arch/x86/kernel/smpboot.c 的 build_sched_topology() 函数定义了x86平台调度器拓扑,其中每一级拓扑都有一组对应的mask来描述核心之间的关系和一些相关的flags,也被称作“调度域 (scheduler domain)”:
- 单核多线程的SMT域(cpu_smt_mask),描述哪些SMT线程之间是共享同一个核心的关系
带有SD_SHARE_CPUCAPACITY、SD_SHARE_LLC这两个flag - L2 cluster域(cpu_clustergroup_mask),描述哪些核心之间是共享同一个L2的关系,主要应用于Intel atom小核心等;
带有SD_CLUSTER、SD_SHARE_LLC这两个flag。当ITMT可用时,带有SD_ASYM_PACKING这个flag - 共享LLC域(cpu_coregroup_mask),描述哪些核心之间是共享同一个LLC(通常也就是L3缓存)的关系,主要用于AMD Zen的CCX。
带有SD_SHARE_LLC flag。当ITMT可用时,带有SD_ASYM_PACKING这个flag。 - Package域(cpu_cpu_mask),描述CPU里的所有核心。
当判断X86_FEATURE_HYBRID_CPU与ITMT同时可用时,带有SD_ASYM_PACKING这个flag。
通过阅读Linux CFS的源码,我们可以看出它的调度算法会尽可能将负载平衡地分配在不同的LLC domain内,在Ryzen SoC上则是表现为倾向于将负载分配至尽可能多的CCX。
另一方面,ITMT对调度器的影响,则是intel-pstate或amd-pstate驱动通过平台固件读取核心优先级后调用sched_set_itmt_core_prio(int prio, int core_cpu)完成设置,使得sched_asym_prefer可以通过arch_asym_cpu_priority判断两个核心谁更优先。而调度器在判断sched_asym_prefer之前,会首先使用sched_use_asym_prio()判断当前的调度域是否包含SD_ASYM_PACKING flags。这一调度逻辑在LLC相关逻辑之前,所以理论上不应该受到CCX/LLC的影响。
但到这里可能看出了一些不对劲:前面我们提到了,L2、L3调度域内都包含SD_ASYM_PACKING flag,而在我们最关注的package这个层级,却需要X86_FEATURE_HYBRID_CPU作为前提条件才会被赋予这个flag。而X86_FEATURE_HYBRID_CPU是Intel的CPUID里的定义,与AMD并不兼容。
解决方案
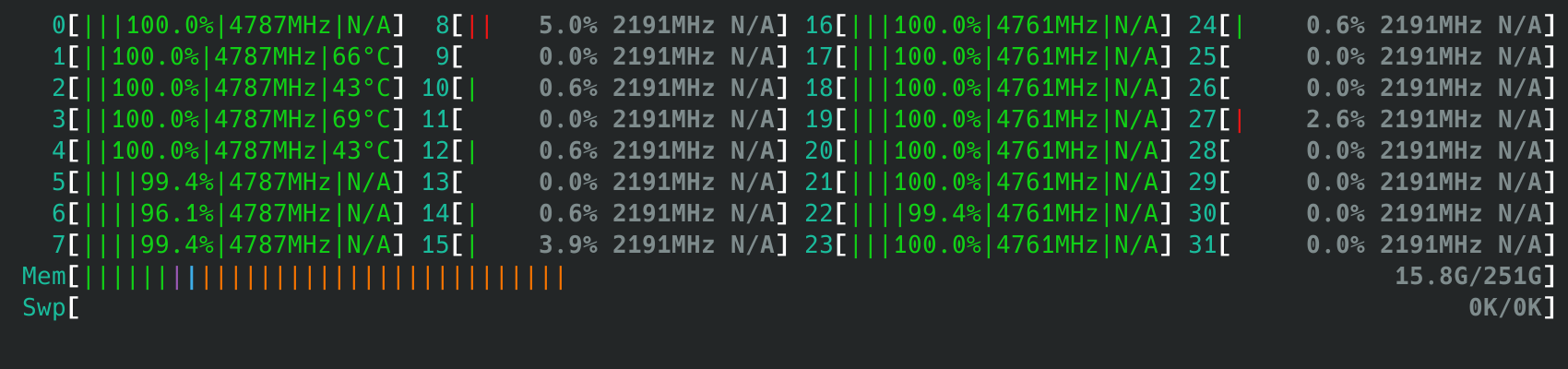
既然我们已经找到了最根源的问题所在,那么接下来只需要作出对应的修改即可。作为测试,我们可以使用比较暴力的方法来修改,那就是直接去掉这个判断,先无脑给整个package加上SD_ASYM_PACKING。

经过修改后,我们再运行相同的测试,可以发现偏好核心调度已经完全按照预期进行,问题解决。
简单搜索后,我们可以发现目前已经有内核补丁尝试在这一位置针对Strix Point处理器修复这一问题,但由于补丁里判断了X86_FEATURE_HETERO_CORE_TOPOLOGY,这只能解决Strix Point的大小核调度失效,无法解决普通多CCX处理器的偏好核心调度问题。并且这一补丁合集过大,导致从8月底一直review到现在还没有进入主线。
如果是正式地发patch修复这个问题,可以考虑在x86_die_flag()里面加入针对AMD CPU的判断,对于AMD CPU则直接返回x86_sched_itmt_flags(),不作判断。当然,本人在多次目睹Linux社区协作的低效率之后,是一定不想亲自参与修复这种小问题的,所以这种简单的问题还是等有心人去修吧。
结语
正如前文所述,ITMT调度器于2016年初次被引入到Linux。当时的处理器非常简单,家用处理器普遍只有完全对称的2-4核心,而ITMT服务的Broadwell-E处理器也是10核心封顶,且共享同一个三级缓存LLC。
8年过去,Linux支持的硬件从理想的SMP变成了无比复杂的妖魔鬼怪:大小核、非对称处理器、多个CCX/LLC、单package多NUMA,可不同厂商的硬件却依然在共用这么一个CFS调度器。这使Linux的调度器变得无比复杂,需要考虑的情况越来越多,最终变成了没有人能完全理解的屎山,顾此失彼出现遗漏的可能性也越来越多。
这次虽然是一个debug几分钟就能发现的小问题,但也折射出背后的软件工程弊病:
- AMD的Linux内核工程师并没有充分理解ITMT调度器背后的工作原理,只是仿照Intel的代码去配置ITMT,却没有发现背后非常明显的问题;
- AMD的Linux内核工程师并没有充分测试这个补丁。不仅是这一个补丁没有测试,后续的各种补丁的测试状况都非常存疑;
- 针对7900X3D/7950X3D切换CPPC核心优先级的补丁,在当前状况下连最基本的优先使用特定CCX都无法工作。
- 此前针对HX 370大小核调度的一系列补丁(识别大小核等),经过我的测试也会因为本文的问题导致作用不明。
- Linux本身对新硬件的支持度非常存疑,AMD平台于2019年中引入CPPC preferred cores,Windows同步支持,而Linux直到2023年底才有人想起来这一个问题。
- Linux本身强求单一代码一统天下,然而事实上桌面处理器与服务器处理器所需的调度算法根本无法一概而论,且这样导致单一调度器设计过于复杂。
其结果,就是5年来Linux AMD高端处理器用户获得的性能相比Windows用户一直有所欠缺,单核性能比理想值至少低了5-10%左右,且游戏等应用会有比Windows严重得多的跨CCX同步问题。
只能期望以后处理器厂商能更早地将功能提交到Linux,以及更完善的测试吧。另外,Linux本身是否也已经到达了一个临界点,需要一些改变呢?
哈喽,这边想要交换友链可以吗
https://aiccrop.com/friends/
名称:CircleCrop Blog
网址:https://aiccrop.com/
头像:https://aiccrop.com/api/head/
简介:舟遥遥以轻飏,风飘飘而吹衣。
已加
在高通 X Elite ARM PC 上也看到了类似的问题,即使打了 cpufreq 补丁,也未必会调度到能 Boost 的两个 Core Cluster(一共有三个,第一个 Cluster 没有 Boost),导致跑 SPEC 出来的结果误差很大(~15%)。
在 9950X 用 Ubuntu 24.10 的 Linux 6.11 内核后,似乎调度是正确的:轮流从两个 CCD 中取出 prefcore_ranking 最高的核心来调度。或许 6.11 做了什么修复?目前还没找到对应的 commit。
我仔细阅读了一下博客,大概理解了问题:在 9950X 这种对称的架构上,在 Die 级别上做负载均衡没啥问题,因为都是同构的核心,然后 Die 内再按照 prefcore_ranking 顺序来调度;但是对于 Strix Point,不同的 Die 对应的是不同的核,此时应该优先去选更高性能的那个 Die,而不是 Zen 5 和 Zen 5c 来回分配。
其实在9950X上这个也是不符合预期的,因为9950X只是接近对称并非完全对称:只有CCD0里的其中两个核心可以达到单核5.75GHz的最高频率,CCD1只能全员5.5GHz。如果随机选一个的话,就会导致有概率单核负载比理想频率低了0.2GHz。
优先跨越CCD做负载均衡更适合epyc,所有核心都可以达到相同的最高频率。
确实,这也能解释我跑 SPEC 的时候为什么平均频率在 5.5-5.6 GHz 了。只能说 AMD 还是对 Client 不太上心。
一个小细节。从6.6开始,内核应该在用EEVDF而不是CFS了。
Hello,
First of all, thanks for this analysis. Threads hopping between all domains have always seemed wrong. Now we know the root cause.
I’m curious, did you run any benchmarks comparing the default with your patched kernel?
Btw this is a classic case of AMD’s approach to the software side of their business. AMD – the software company.
Didn’t do any serious benchmarks and only some observations so far, and I believe the new behavior isn’t universally beneficial especially for a lot of cloud native / server benchmarks (i.e. good parallelism w/o frequent communication between threads)
One thing I did notice is that this patch massively improved my gaming experience on Threadripper 7970X if I don’t do some sort of tinkering like setting WINE_CPU_TOPOLOGY.
Any chance you could test again with Linux kernel 6.17 and see if things have improved much?
It’s been fixed for a while now, IIRC 6.14+ are okay. Also backported to 6.12.x