自从大语言模型开始流行以来,一直在AI领域深耕细作的NVIDIA直接获得了大量订单,导致产品供不应求,人们也一直在寻找更便宜的方案。这给了我们评估许多其它方案的机会,例如我前些时尝试搭建的W7900方案就是一个可行的替代。
碰巧的是,Apple刚好在LLM大火的时间点前后接连发布M1 / M2 Ultra,最大带来了128 / 192 GB且带宽高达800 GB/s的内存。考虑到本地运行LLM最大的瓶颈是显存容量和显存带宽,两者似乎是一拍即合,在数码媒体的渲染下创造了多个类似“Mac Studio > 6 * RTX 4090”的名场面。
事实真的是如此吗?经过实际测试,我发现尽管Apple Silicon可以将超大显存装进常规轻薄笔记本电脑,但在运行LLM方面存在各种妥协,使得苹果平台并没有比NVIDIA方案的性价比更高。
devil’s in the details
本文我们使用一组实测数据来介绍目前的现状。
测试硬件如下:
- Apple Mac Mini (M4 Pro)
- 14 CPU核心
- 20 GPU核心
- 16 ANE核心
- LPDDR5x-8533 256bit 64 GB内存
- 1 TB闪存
- NVIDIA RTX A6000
- NVIDIA RTX 6000 Ada
- AMD Radeon Pro W7900 Dual Slot
注意:由于M4 Pro与其它这些专业独显并不处于同一性能区间(专业独显的显存带宽大约是它的3倍),因此真正进行对比时更多是用它来推测拟合M4 Max乃至Ultra的性能特性,评价Apple GPU这一体系在PC独显面前的整体竞争力,而非仅仅局限于M4 Pro这一个芯片的表现。
为了方便跨硬件平台获得更多数据进行对比,本文依然使用llama.cpp进行测试,基于相同commit/版本进行。AMD平台会打补丁为flash attention启用WMMA(采用与NVIDIA GPU的nvcuda::wmma相同的代码路径)以充分利用RDNA3的矩阵单元。
Apple MLX、NVIDIA TensorRT-LLM、AMD主推的vLLM等均可在相似的条件下获得显著更好的性能,但由于测试环境、运行参数、生成内容的差异较大,公平的测试与对比会变得比较麻烦。除了因为跨平台对比数据方便之外,llama.cpp本身也是众多流行的客户端LLM工具普遍选择的后端,因此具备一定的实际意义。
模型方面,则是选取iq4_xs量化的llama 3.1 70B。相比于q4_0,iq4_xs体积更小,生成质量更好,代价是对GPU计算的负载更高。根据llama.cpp的项目说明内容,iq4_xs在Apple GPU上有较为严重的性能问题,但经过我的实测,在M3、M4等新GPU架构的平台上,其推理性能相比于q4_0只有非常轻微的损失(5%),因此本次主要使用它来进行对比。
文本生成的性能是目前主要的关注点,我们使用llama-bench测试生成不同长度的文本。
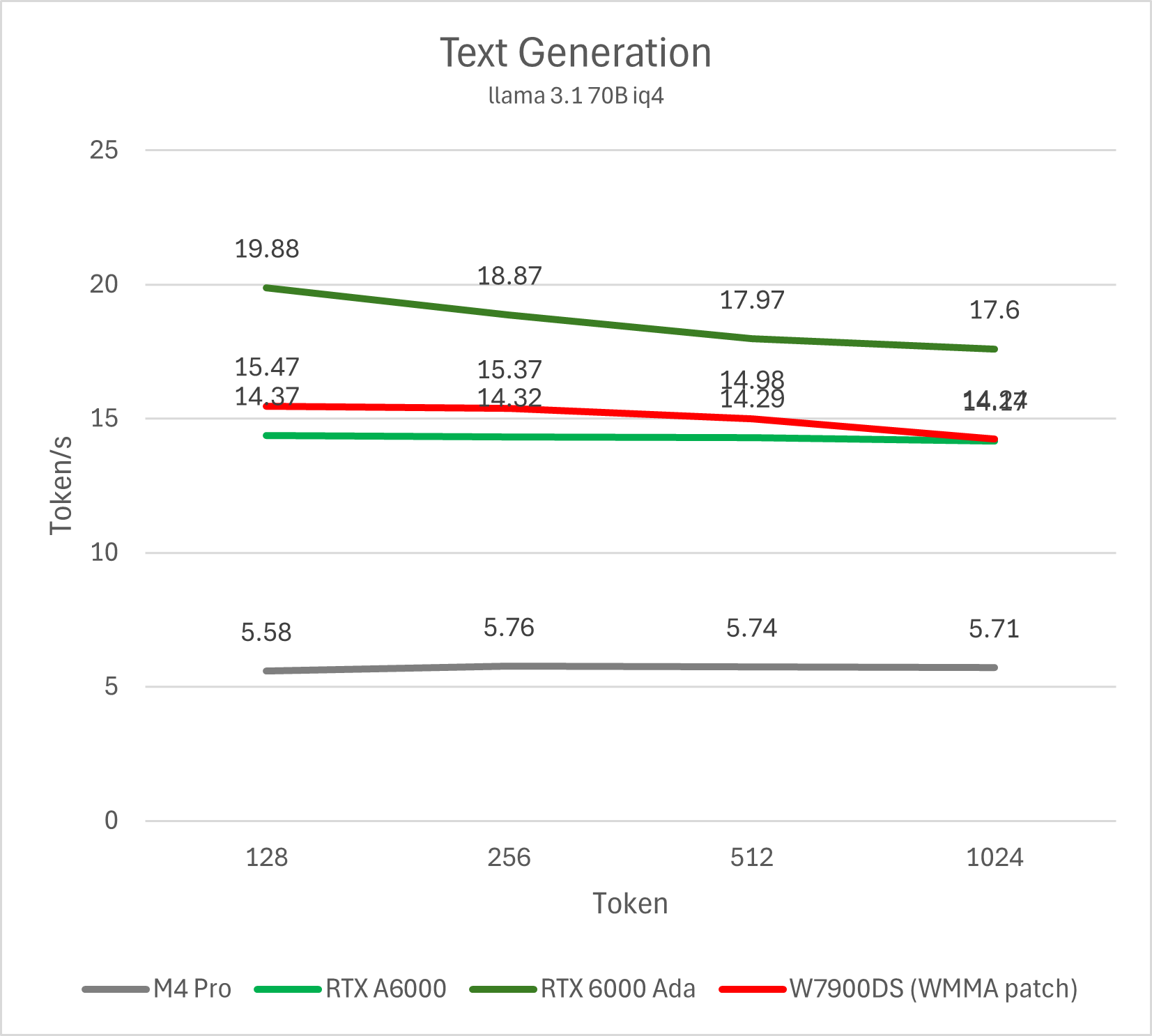
测试命令 llama-bench -m ~/models/llama3.1-70b-iq4.gguf -ngl 999 -fa 1 -n 128,256,512,1024 -p 0
在这里,虽然M4 Pro的性能不及旗舰级专业卡这样的重量级选手,但其完全可以充分发挥273 GB/s的带宽,获得不逊于竞品的推理效率。此外,上述4个同为≥ 48 GB显存容量的方案里,从正规渠道购买M4 Pro的价格不到2万人民币,W7900DS大约2.5-3万,RTX A6000的价格3万多,RTX 6000 Ada更是高达5万。作为能运行70B LLM的方案,Mac的门槛可以算是非常低了。
可以预期的是M4 Max乃至Ultra会有更加优秀的性能表现(2-4倍范围内),甚至有机会超越相当一部分顶级的独立显卡。参考M2时期Mac Studio的定价,M4 Max/Ultra搭配64 GB内存的价格预期分别为略高于两万和略高于三万元人民币,作为理论性能达到2-4倍的方案,相比同为64 GB内存的Mac Mini来说甚至还会更具有性价比。
这也是数码媒体最近这段时间针对M4的评测展示的主要数据。但是数码媒体很少有真正展示全部数据和背后诸多细节的。大多数都是展示好看的数据,或者观众们想看到的数据。接下来,我们进入本文的正题:讨论Apple GPU当前运行LLM的几个主要问题。
GPU Matrix吞吐
显存的容量和带宽是LLM的主要关注点,但LLM并非任何情况下都是显存为王,Matrix吞吐也并非完全没有价值。这主要体现在prompt processing (prefill)性能、高并发性能以及推测解码三个方面。
Prompt processing 性能
Prompt processing (prefill)是处理用户输入的阶段,也就是用户输入的内容越长,这一阶段所需要的时间越久。如果你使用LLM主要是用于长文总结,内容翻译等输入内容较长的应用场景,那么prefill性能才是最需要关注的。此外,在较长的对话中,如果没有开启prompt caching,则每次都需要将此前完整的对话上下文作为prompt输入处理(好在llama.cpp的server只需要简单patch就可以默认启用caching)。
此前在W7900的文章中我提到过AMD GPU在这方面性能不佳的问题,那么Apple GPU在这个场景下的表现如何呢?
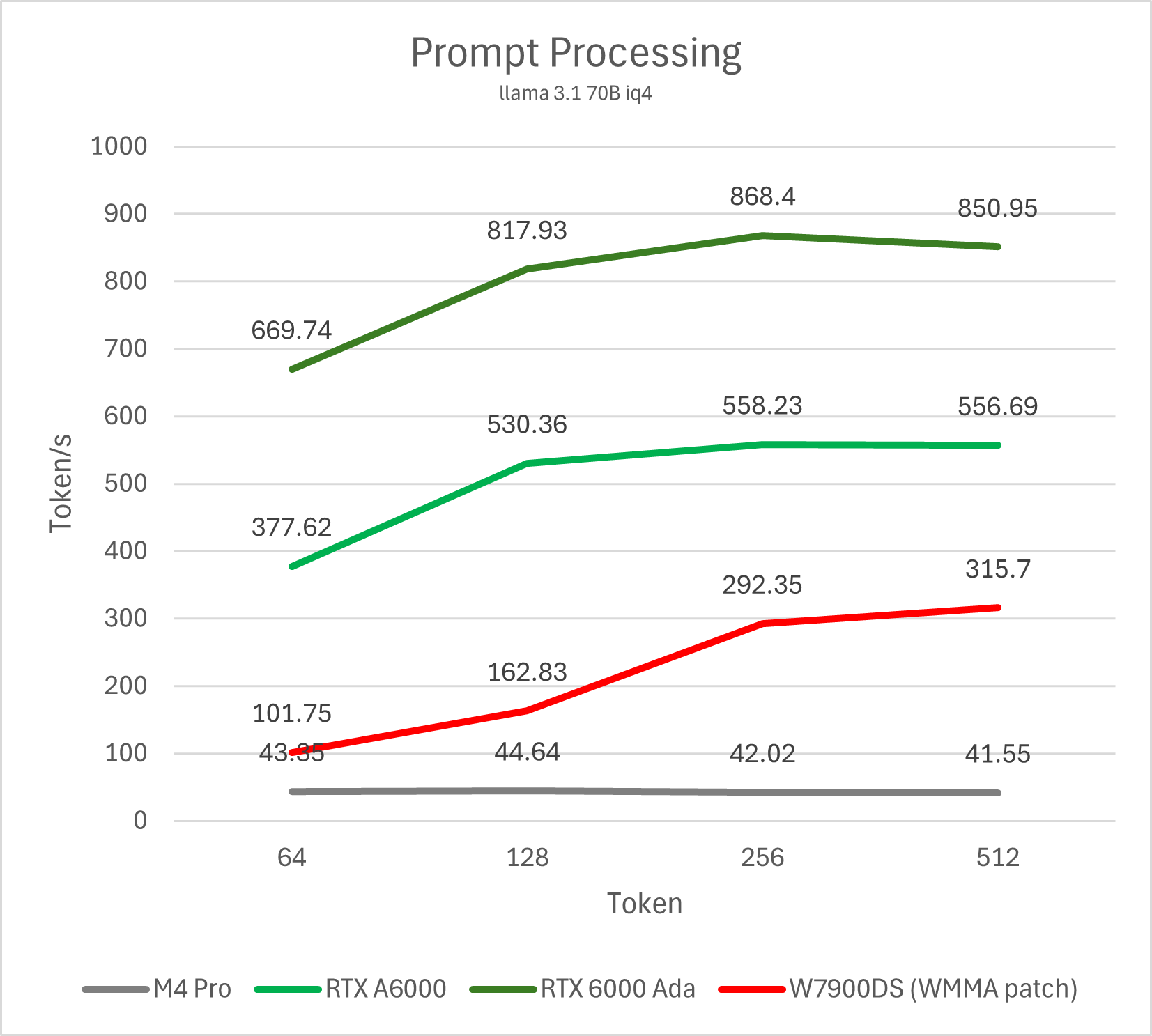
测试命令 llama-bench -m ~/models/llama3.1-70b-iq4.gguf -ngl 999 -fa 1 -n 0 -p 64,128,256,512
经过测试我们可以发现,Apple Silicon在这方面的性能非常惨淡,即便我们按照4倍规模带来4倍性能的理想预期计算M4 Ultra的性能(~160 token/s),它也只能达到W7900的一半,RTX A6000的三分之一,RTX 6000 Ada的五分之一。
这个性能数字并不难理解,长期以来Apple在AI方面的策略更多偏向NPU而非GPU,其GPU并没有NVIDIA那样成熟的Matrix/Tensor单元来大幅度提升矩阵计算性能,因此核心数相同的情况下矩阵运算吞吐存在数倍的纸面参数差距。另一方面,Apple Silicon在这项测试里的能效表现也相对平庸,仅仅GPU核心就需要消耗30W左右的功耗,而竞品普遍是10倍甚至20倍以上性能却仅仅只有300W的整卡功耗。
高并发性能
前面的两项测试更多的是针对单人使用的场景,但LLM在实际使用中并非只有这么简单,事实上可以非常高效率的批量处理,或将一个API endpoint共享给局域网里的其他人使用。
Prefill的总性能通常不会随着batch size上升而提升,因此我们的测试以decode/text generation性能为主。
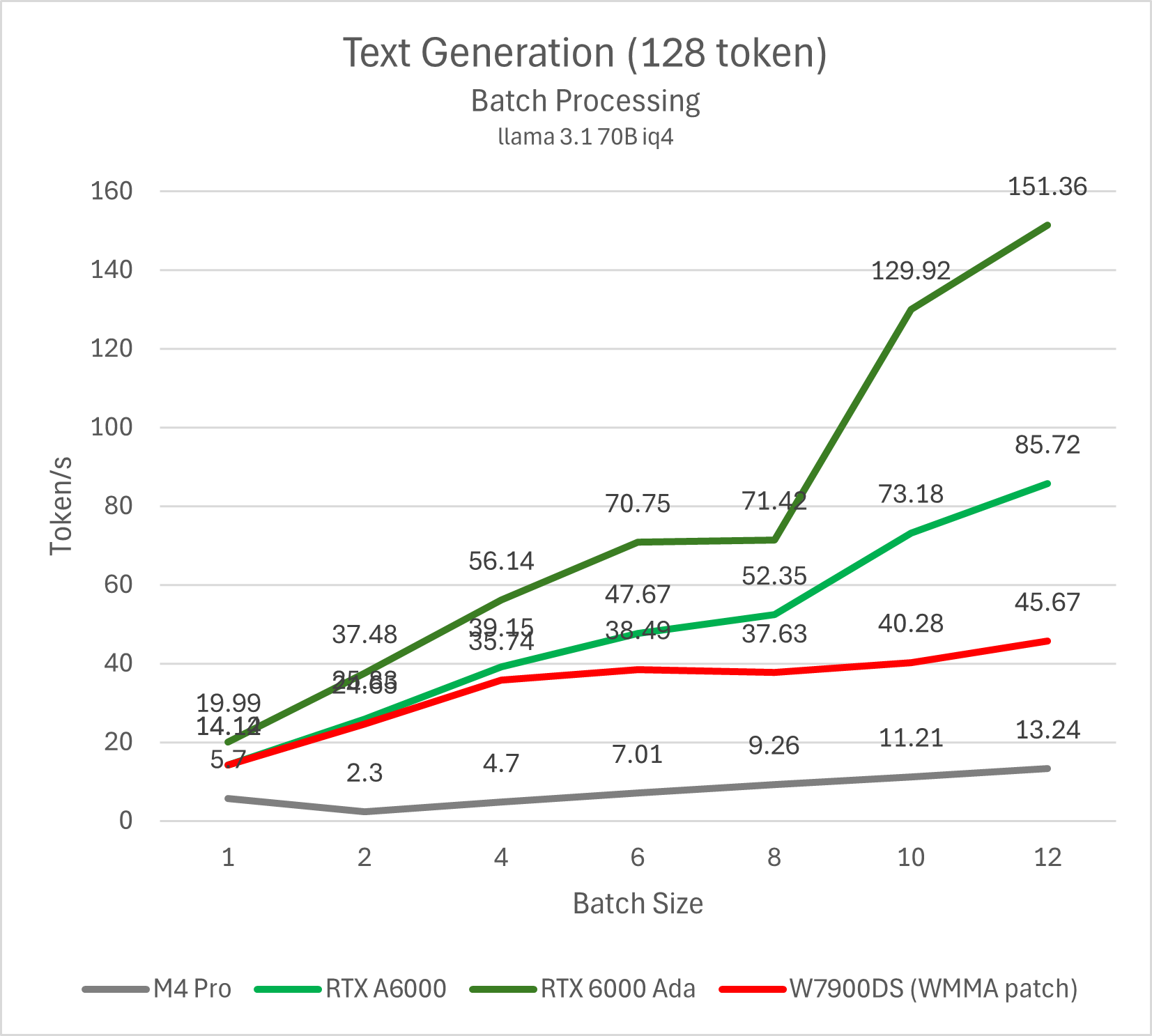
测试命令 llama-batched-bench -ngl 999 -m ~/models/llama3.1-70b-iq4.gguf -fa -npl 1,2,4,6,8,10,12 -npp 512 -ntg 128 -c 16384
可以看出,NVIDIA GPU在并发超过10之后依然有非常显著的性能提升,且单个用户的性能未发生明显下降;AMD则可以将总性能上升的趋势维持到4并发左右,不过在此范围内的单用户性能也会出现显著下降;Apple GPU在并发数为2-4的情况下不仅得不到任何明显的性能提升,反而连总性能都会下降。哪怕将并发数量提高到12,相比竞品也是毫无优势可言。
产生这样一个结果的原因也是显而易见的,在decode阶段,单个请求的性能与带宽相关,但高并发的性能瓶颈则重新回到了Matrix吞吐。事实上,如果我们比较各个GPU在最高并发下的性能差异,则可发现它们的比例非常接近GPU的matrix理论吞吐比例。
推测解码 (speculative decoding)
如果你说前面的prompt processing性能影响场景比较少,而高并发性能对本地单用户场景来说可能感知不强,那么我们把单用户、text generation性能放在第一位,推测解码是对这个场景而言提升最大的技术。它本质上是在用算力换带宽,使用一个较小的draft model推理预测一个较大的target model的输出。
llama.cpp去年新增了这一功能,虽然目前尚未被整合到benchmark等程序里,但提供了一个较为方便的命令行工具作为sample。我们使用以下命令运行llama 3.1 70B q4_0量化模型,使用llama 3.1 8B q4_0模型作为它的draft model,并挑选推测准确率相近的两组数据进行比较:
llama-speculative -m ~/models/llama3.1-70b-q4_0.gguf -md ~/models/llama3.1-8b-q4_0.gguf -p "Tell me some details of the United States history, starting from its independence." -e -ngl 999 -ngld 999 -t 16 -n 512 --draft 8 --sampling-seq k,m,t -fa -ctk q8_0 -ctv q8_0
Apple M4 Pro
encoded 16 tokens in 1.042 seconds, speed: 15.360 t/s
decoded 520 tokens in 73.608 seconds, speed: 7.064 t/s
accept: 77.604%
Radeon Pro W7900 Dual Slot
encoded 16 tokens in 0.166 seconds, speed: 96.202 t/s
decoded 517 tokens in 19.943 seconds, speed: 25.924 t/s
accept: 78.345%
作为对比,使用 llama-cli 与相同70B q4_0模型、参数进行测试,M4 Pro与W7900的decode性能分别为6.01 t/s与15.29 t/s,也就是二者通过推测解码分别获得17%和80%的提升。由于NVIDIA GPU的Matrix吞吐更强,其在相近的条件下理论上获得的提升更大(由于个人时间限制没有实际测试)。
除了性能之外,Apple平台还有一些其它的问题进一步削弱它的实际竞争力。
容量与带宽不匹配
如果说游戏显卡的显存容量与带宽不匹配是因为显存太小,那么Mac则是正好相反。它的内存容量过大,以至于如果是专门为了LLM而选购,每款SKU的最高配置并没有什么价值。
例如,本文测试的Mac Mini M4 Pro顶配可以选择64 GB内存,但是实际上运行37 GB的70B q4模型的性能就已经较为缓慢,5-6 token/s的性能使用体验不佳。因此,实际更适合选择的是每256bit位宽至多配置32 GB内存运行30B左右的模型。当然,如果是打算运行MoE模型,这个问题则会好不少,虽然目前好用且刚好适合这个容量的开源MoE模型并不多,对Apple Silicon平台的支持也不够成熟。
对于普通用户而言,同一台机器后台还要运行大量其它软件和游戏等,也可以认为没有太大顾虑。
扩展性缺失
很多人喜欢拿游戏显卡显存小、专业卡显存贵来论证Mac提供相对便宜的大容量显存是多么有利于LLM,但事实上这种说法忽略了LLM支持多卡推理且对互联要求不高的事实。
目前京东在售的RTX 3090涡轮卡的价格大约在6500元左右,两个3090涡轮卡再加上一个支持PCIe拆分的主板,全套配下来整机还没有一台64 GB内存+1TB硬盘的Mac Mini贵(考虑到Mac Mini需要一部分内存来跑系统等等),却有48 GB显存、每张卡3倍于M4 Pro的带宽和超过M4 Pro 10倍的算力可用。依照目前M2 Ultra + 128 GB内存的售价,未来M4 Ultra + 128 GB内存也大概率会超过4卡RTX 3090全平台的价格。
除此之外需要考虑的是,在PC平台搭建这样的LLM系统,可以先从单GPU开始评估较小的模型是否能满足自己的需求,如果不够则继续再加几张卡解决。根据此前在W7900文章里针对A/N卡的多卡测试,加卡还能带来一些性能提升。但购买Mac则是一锤子买卖,想要扩展内存只能将旧机器卖了重新再买一台,或者想办法折腾RPC后端这类并不是太可靠、性能也比较一般的多机分布式推理方案。
总结
综上所述,虽然Apple Silicon表面上从纯粹、原始的单用户LLM decode吞吐来看可以与独显方案一战,但深入体验后则会发现背后更多的是表现平平的数字,以及在多个方面相当大的取舍。不可否认的是,如果是将M4 Pro/Max作为笔记本处理器评价,则有着实至名归的“最强LLM笔记本”称号,这是Apple Silicon目前的独家特色,没有任何竞品。但在这之外,如果你希望在固定地点搭建LLM PC、服务器,并且对空间限制不敏感,其实很难再找到Apple Silicon的亮点。
当然,这并不是说Apple GPU未来的版本不能通过加入更高吞吐的matrix单元解决这些问题并成为非常优秀的LLM推理方案,但未来是未来,至少本代硬件目前的性能平庸之处难以被忽视。
展望未来,Apple有自己的MLX框架,有算力足够强的NPU和带宽足够高的CPU/GPU,未来如果结合NPU与GPU来做端侧异构推测解码,是否能完美翻身,走出一条自己的特色路线呢?在我看来硬件理论基础已经具备,但软件和模型支持显然还有待完善。
因为对手是a6000,如果是4090的话跑都跑不了,这才是统一内存的关键
游戏卡可以买便宜显卡上多卡推理,性能和价格都比专业卡要强不少。2*24G 384bit也算是一个平衡容量和性能的甜点了。
我用 M1 macbook air 运行 LLM 的体验,和博主的类似。
我发现它的 prefill 性能非常糟糕,以至于如果我们真的跑当前很多开源模型所支持的 100k 上下文的推理,光 prefill 就得花十几甚至几十分钟,已经没有实用价值了。
真的严肃的 LLM 内部或者对外的商业应用,还是得用 Nvidia 或者 AMD 的显卡。
结论写得好!有理有据,而且推演了主要的使用场景。
很多媒体测试的时候只有decode输出速度,实际上prefill性能决定了ttft首token出来的时间,decode涉及到并发表现如何,都是更重要的。本地模型经常被用来代码补全,Apple这个prefill只有40多token在这个场景下就完全不可用了。
啊,确定M4 Pro + 64G也不能顺畅地跑70b了么😭
可以跑,用MLX能做到q4量化速度勉强可用的程度。只不过专门买来跑LLM的性价比是不存在的,更适合已经对Mac有需求,有其他用途的情况下顺便跑一跑,尤其是笔记本。
单片3090也跑不了吧?70b
一台64G Mac Mini的价格足够买3张3090了,LLM可以多卡甚至多机跑。
这个问题在我组多卡平台的时候也遇到了,闲鱼上p40 24g因为大显存价格比去年翻了一番,实际上溢价严重,llm考虑单位显存的算力。
m4Pro 14B IQ4大概是什么个速度 PP跟TG
llama-bench -m ~/models/qwen2.5-14b-iq4.gguf -ngl 999 -fa 1 -t 10 -mmp 0| model | test | t/s |
| ------------------------------ | ----: | -------------: |
| qwen2 ?B IQ4_XS - 4.25 bpw | pp512 | 232.53 ± 0.12 |
| qwen2 ?B IQ4_XS - 4.25 bpw | tg128 | 25.04 ± 0.07 |
build: af148c93 (4077)
这个级别的模型非常可用
感谢博主的测试研究,打消了我采购 Mac Mini M4 Pro 64G 高配的念头。前面下了预订,取消了。因为确实没什么用,光有内存(显存),算力严重不够。
我也是
感谢楼主,我差点就下单了,想想,还是在我的台式机上多插两张3090更划算,除了不能带走以外,真的没有对比性。
感谢您的评测
不过统一内存做好了使用起来体验很舒服的,比如LNL应该就是第一个真正的UMA产品。
保持分配的自动选项后,测试可以直接跑 llama 14B大模型,此时显存完全自动分配了。
包括在blender的cycle里,用ONEAPI也可以自动分配16G的显存。
目前还不知道新的Halo是否有类似特性,不知道博主能否届时一同测试?
有尝试过直接通过SSH访问,而关掉桌面服务吗?我测试后发现prompt eval rate的速度会有较大的提升
所有测试均在图形界面未登入用户的状态下使用ssh远程登录进行,不过我没有注意完全关闭图形登录界面
– 实际更适合选择的是每256bit位宽至多配置32 GB内存运行30B左右的模型
这句话怎么理解呢?是否说从综合性能参数和角度看,目前m4 pro 64g的组合,跑70b不流畅,跑32b,性能还有冗余。如果是m4 pro 48g(因为m4 pro没有32g的组合,32g的组合只有m4,不pro,且内存带宽120GB/s),尽管跑70b属于不可用,但跑32b是一个流畅的选择,对么?
那如上分析,硬件上再退一步,反正70b都跑不好,那就跑32b(配合本地搭建个知识库运用),是否丐版m4 + 32g(内存带宽120GB/s,只有m4 pro的一半不到)也可以应对了呢。
256bit LPDDR5x-8533内存的带宽是273 GB/s,运行32B 4bit模型(占用低于 20 GB)可以稳定运行在大于 10 token/s 的速度上。如果换用普通M4运行32B,或者M4 Pro运行70B,速度则会减半到明显低于小于10 token/s,属于生成速度明显比一般的在线服务慢了。
当然,> 10 token/s属于我自己的标准,不同人和不同场景对低速LLM的接受度不一样,所以可以根据接受的LLM吐字速度、内存/显存带宽和模型大小进行一个大致的估算(基本成比例),再决定买什么硬件。
谢谢回复。
我现在是mac intel,i7 16G+GPU8G,14b模型5 token/s,回答可以接受,但确实没有什么流畅度,特别是看了你的prompt processing这个环节,我理解是预读,实际运用中,这个环节还挺重要的,不然一直看着跑圈圈,一个字都没有。看了一些对比评测,mac的运算和统一内存确实在这块prompt processing就比N卡差点了。
https://lmstudio.ai/blog/lmstudio-v0.3.10
前段时间lm studio的文章做了一个对比测试,苹果如果使用mlx做speculative decoding似乎速度提升效果还是不错的,可能是之前llama.cpp优化的问题?
参数上需要更多的调优,主要是draft模型选取问题以及投机解码token数量开太高了。
不过llama.cpp的投机解码在A/N卡上的表现也很差,跟我最近用vLLM测试的性能在极端情况下可以差一两倍,所以最后的结论依然变化不大。
感谢博主,当时差点就上当了