前阵子在测试Strix Point与Lunar Lake等平台的CPU时,我偶然发现本代处理器在核间延迟这一指标上的一些变化。众所周知同步与互斥是现代复杂多线程软件高度依赖的原语之一,对其进行性能优化也是多线程编程的一大难点。多核处理器在硬件层面高效率地设计并实现同步,在工程上也是一个不小的挑战。
事实上,同步延迟这一概念不仅是对于CPU,其对于GPU也是一个重要的指标。在理想世界里,GPU可以以极高的吞吐并行处理大量毫不相关的数据。但现实是随着GPU规模的不断扩大,在一部分例如Gaming的领域的GPU应用已经出现了非常严重的并行度瓶颈,小规模数据的计算之间互相依赖导致不同层级的交互延迟成为瓶颈。
与CPU核心相对应,在GPU上处于类似层级的结构是SM (NVIDIA) / CU (OpenCL | AMD GCN)等等,一些厂商如Intel和Apple也将其直接称为GPU核心。而家用GPU的SM/CU核心数量远远超过普通家用CPU (144/96 vs 24),数据中心GPU更是如此(160/304 vs 32-128),这意味着为这些处理器核心的缓存一致性互联设计也会更加具有挑战性。
本文以我手边可用的一些硬件,搭配ROCm/HIP编程环境讲解如何使用类似测试CPU的手段来测量GPU的跨核心同步延迟,并提供一些大致的数据参考。
测试设计
编程模型选择
首先不得不提到为什么本文会选择ROCm/HIP环境和AMD GPU而非使用OpenCL、SYCL、Vulkan等通用API或者NVIDIA CUDA。
在CPU上进行同步延迟测试时,我们通常使用操作系统的affinity API将两个线程绑定在不同的核心上,在这两个线程上使用CAS等原子指令进行ping/pong延迟测试。除了macOS官方发行版本不提供affinity API之外,其它操作系统上很容易做到这件事。这是因为,操作系统将CPU(虚拟)核心的概念直接暴露给开发者,甚至进一步提供了更多元数据,比如大小核心、SMT、缓存结构等。
而与之不同的是,常见的GPU API在调度方面几乎完全是一个黑盒:开发者只提供一组数据和对应的shader / kernel用于表达算法逻辑,而开发者编写的代码应该跑在具体哪个GPU核心,一切都是由硬件、固件与驱动进行调度,开发者只需要也只能关注这些数据经过处理后的输出。因此常见的GPU编程模型都没有提供类似affinity的API,尤其是那些跨平台通用的API在制定过程中考虑到这一需求极为罕见,更不会将这个功能列入其中。
幸运的是,基于HSA的ROCm/HIP环境为我们提供了这样一个扩展API:hipExtStreamCreateWithCUMask,其底层是hsa_amd_queue_cu_set_mask这一扩展,落实到Linux环境下则是通过AMDKFD_IOC_SET_CU_MASK这个ioctl实现,最终在amdgpu驱动里通过update_mqd()调用update_cu_mask()函数通过MMIO实现通知GPU上的MES等IP block配置对应queue的affinity。
代码示例
有了理论可行的API之后,进行测试也就变得容易了。
首先调用API查询 CU / WGP 数量
hipDeviceProp_t devProp;
HIP_CHECK(hipGetDeviceProperties(&devProp, 0));
int numCores = devProp.multiProcessorCount;接下来为每一个 CU / WGP 分配一个 HIP Stream,将其mask配置为单个CU。
hipStream_t* streams = (hipStream_t*)malloc(sizeof(hipStream_t) * numCores);
for (int i = 0; i < numCores; i++) {
uint32_t* mask = (uint32_t*)malloc(sizeof(uint32_t) * (i / 32 + 1));
memset(mask, 0, sizeof(uint32_t) * (i / 32 + 1));
setMask(mask, i);
HIP_CHECK(hipExtStreamCreateWithCUMask(&streams[i], i / 32 + 1, mask));
free(mask);
}需要注意的是,每一个HIP Stream对应了一个GPU queue,因此其数量有上限,上面这段代码并非总是能成功运行。例如,在MI300X上这段代码会尝试创建304个HIP Stream,最终会报错out of memory而失败。但是对于Radeon来说则是绰绰有余。
有了这些准备之后,编写一个简单的device kernel,使用atomicCAS实现ping pong同步一定次数
__global__ void testSync(int32_t* readLoc, int32_t* writeLoc, uint64_t iterations) {
do {
while (atomicCAS(readLoc, 1, 0) != 0);
*writeLoc = 1;
iterations--;
} while (iterations > 0);
}在host代码中调用device kernel,等待其完成并使用start / stop event计算时间。
hipExtLaunchKernelGGL(testSync, 1, 1, 0, streams[i], start, stop, 0, deviceBuffer, deviceBuffer2, iter);
hipExtLaunchKernelGGL(testSync, 1, 1, 0, streams[j], 0, 0, 0, deviceBuffer2, deviceBuffer, iter);
HIP_CHECK(hipStreamSynchronize(streams[i]));
HIP_CHECK(hipStreamSynchronize(streams[j]));
HIP_CHECK(hipEventElapsedTime(&result[c], start, stop));实测数据
有了上面这些代码,我们就可以在一些GPU上测试CU之间的atomic延迟了。不过其中依然有很多变量,例如两个指针是否指向同一个cache line内,因此最终测试出来的结果也只是冰山一角。我们首先测试使用不同cache line的情况(两个指针的地址距离在128字节以上)
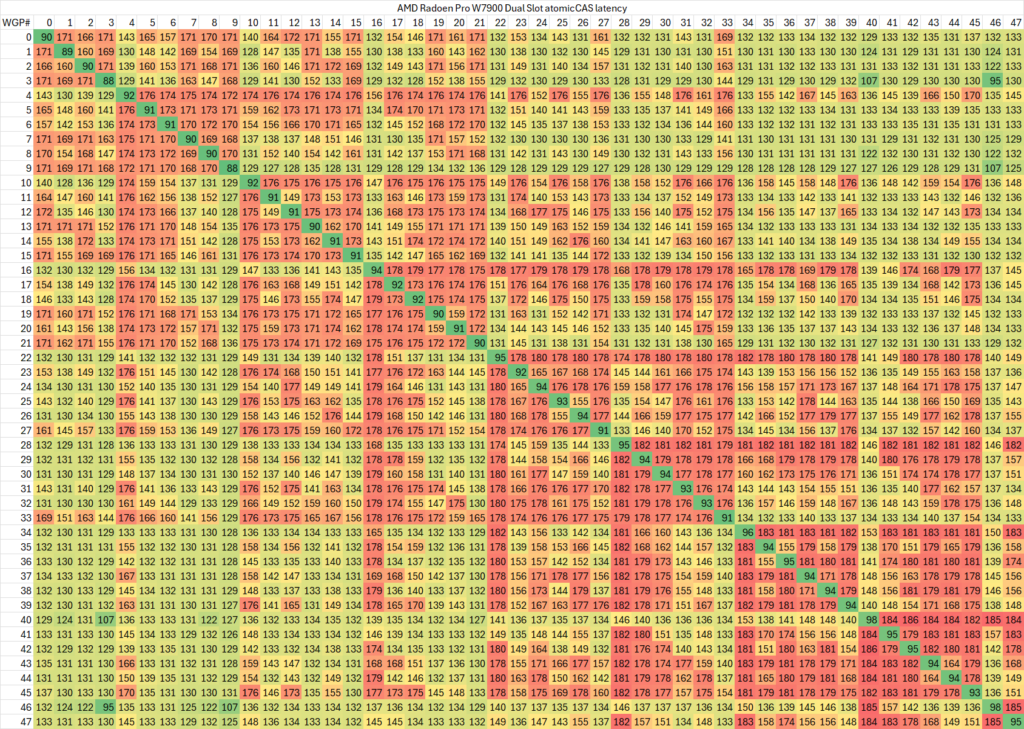
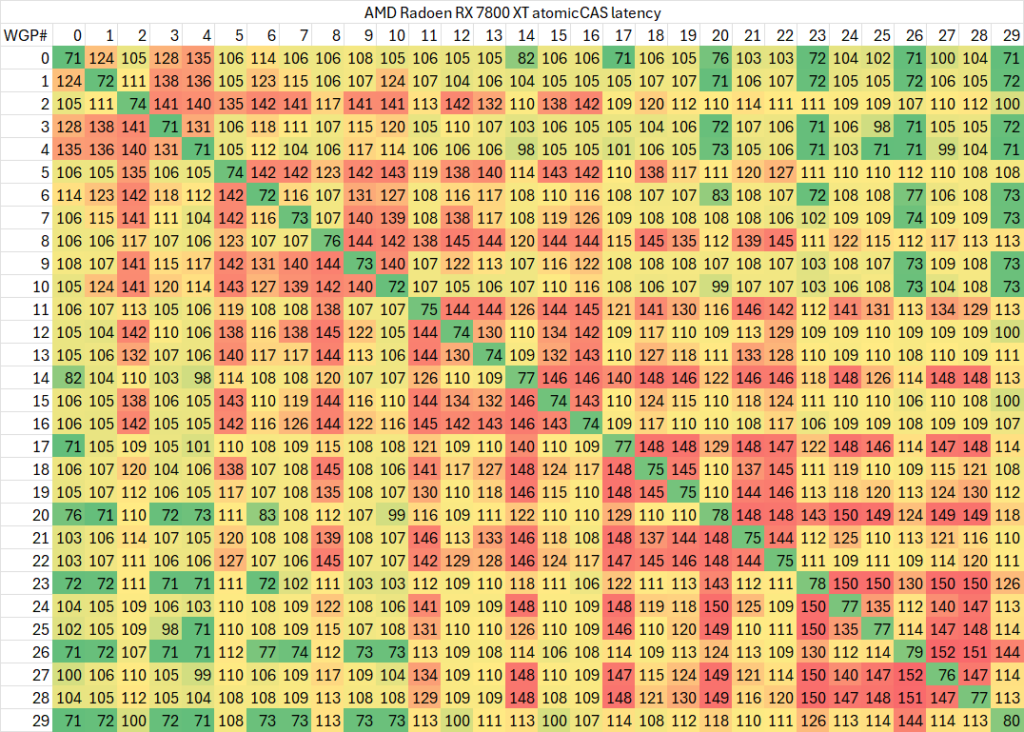
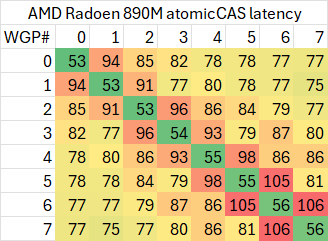
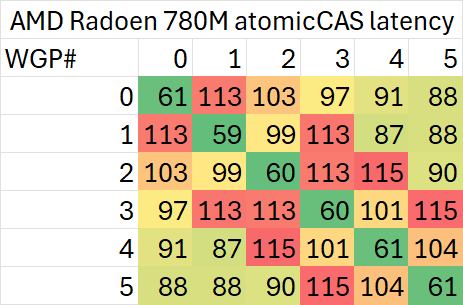
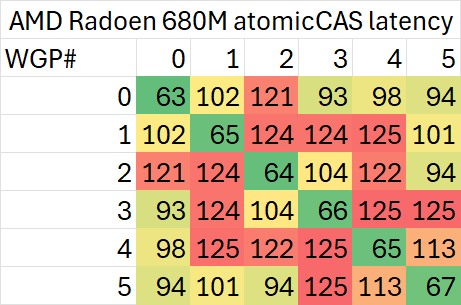
如果测试相同cache line内的延迟,则会略高一些
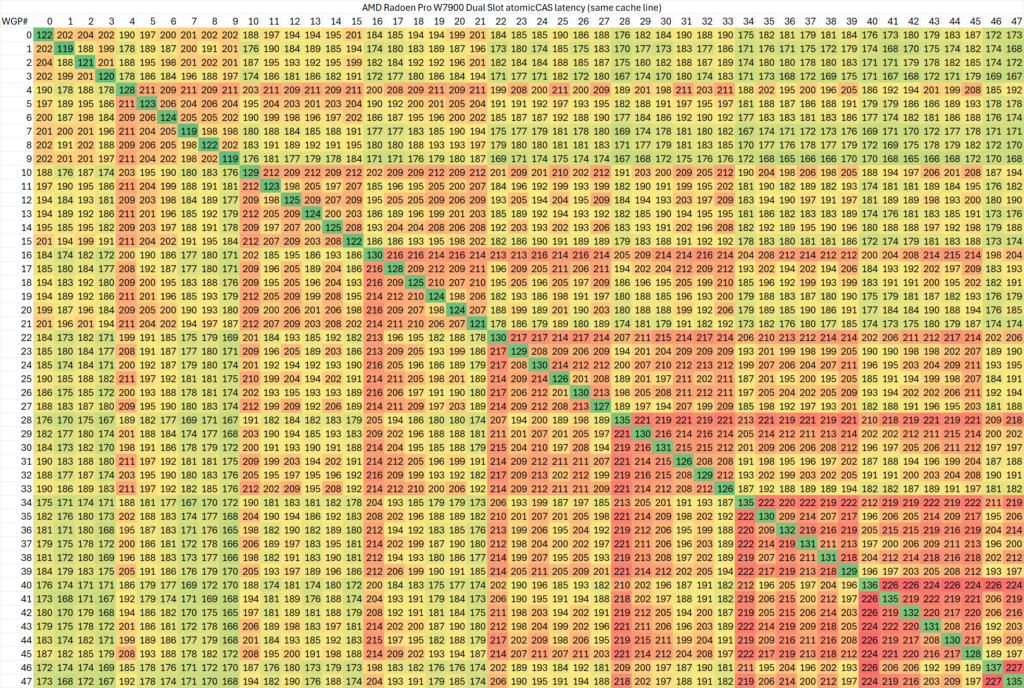
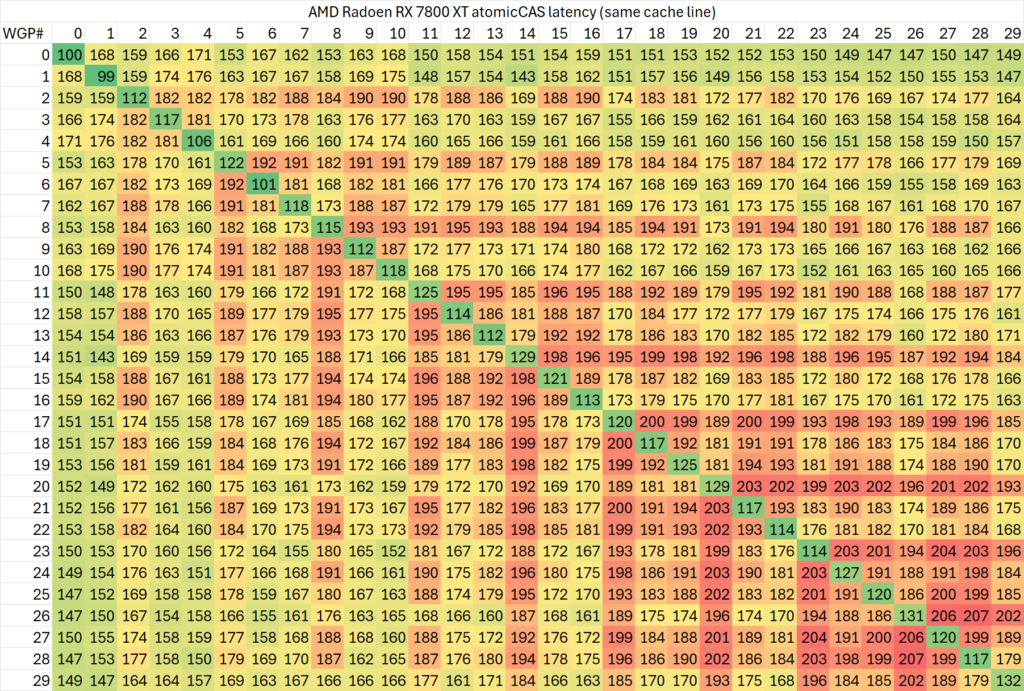
可以看出,同一个WGP内部的atomic同步延迟在50-120ns范围内,而跨WGP的延迟则可以最高达到200ns。
特定的WGP组合(例如相邻的WGP)之间会有较高的延迟,有的个别WGP与其余任意WGP同步的延迟都较高。考虑到ROCm CU mask API的实现,相邻编号的CU位于不同shader engine里交错编排,这一测试结果倒是比较符合预期。
总结
从上面这些测试结果,我们不难看出GPU的片上一致性网络的复杂性,其相比CPU更加没有规律可循。考虑到本文的测试依然比较片面,因此不作过多的分析,只当作抛砖引玉,等日后有了更多的硬件、更完善的测试代码之后再来进行对比。
NVIDIA GPU 可以看看这篇paper以及对应的软件。
https://www.cs.unc.edu/~jbakita/rtas23.pdf
http://rtsrv.cs.unc.edu/cgit/cgit.cgi/libsmctrl.git/about/