几个月前,我曾有机会测试Intel专为超轻薄笔记本打造的Lunar Lake处理器。尽管其独特的设计让它脱颖而出,但在绝对性能方面的弱势意味着它可能并不适合大多数用户的主流PC需求。
对于主流笔记本产品线来说,Intel推出了Arrow Lake H45作为Meteor Lake的继承者。本次,我将对Arrow Lake H45中的酷睿Ultra 7型号(255H)进行测试。
声明:本文仅为个人测试,测试使用的一切设备、工具等资产与本人所在公司/职位无关,也没有接受任何赞助。
由于Arrow Lake的CPU核心微架构与Lunar Lake基本相同,因此我们可以省略繁琐的微架构分析,直接关注缓存、内存、单线程和多线程性能以及能效等方面的表现。对于微架构的详细信息,请参阅我之前的Lunar Lake测试。
处理器规格
本次测试的Core Ultra 7 255H是满规格的处理器,与最高端的Core Ultra 9只有频率略有区别。按照以往的经验,H45产品线的i9体质会略好于i7,但不会有本质区别,其高出的频率大多是通过加压与更激进的TVB策略实现。因此测试i7级别的处理器可以较好地反映一代产品的实际性能。
本次测试的255H平台的具体规格:
- 6个Lion Cove大核心
- 单核5.1 GHz,全核最高4.8 GHz
- L1 缓存为每核心48 KB (数据) / 64 KB (指令)
- “L1.5” 缓存为每核心192 KB
- L2 缓存为每核心3 MB,比Lunar Lake大0.5 MB
- 8个Skymont小核心
- 单核、全核频率均为4.4 GHz
- L1 缓存为每核心32 KB (数据) / 64 KB (指令)
- L2 缓存为4核心共享4 MB
- L3 缓存为所有 Lion Cove / Skymont 核心共享
- 每个节点3 MB,总共24 MB
- 2个Crestmont LPE核心,规格与Meteor Lake相同
- 32 GB LPDDR5X-8533内存
- 8核心Xe LPG+核显
- 与Meteor Lake不同的是换用了更好的工艺,增加了XMX并且加强光线追踪性能
Arrow Lake H45与Meteor Lake相比,在核心频率设定上表现出了更为激进的特点。例如,155H型号仅有两个核心能够达到4.8 GHz的峰值频率,而其他大核心只能达到4.4 GHz。相比之下,255H的每个Lion Cove核心都能达到单核5.1 GHz的高频,并且全核频率也能够达到4.8 GHz,这与155H的单核频率相同。值得注意的是,小核之间的差异也非常显著,155H的小核全核频率仅为2.8 GHz,而Skymont的小核则能够实现单核和全核同频。
这种激进的频率设定使得Arrow Lake H45的功耗显著增加。分别对6个大核和8个小核进行单独测试时,每组核心都能够产生超过50W的功耗,而当两组核心同时工作时,峰值功耗甚至超过100W。幸运的是,测试所用的机型能够轻松应对100W的持续功耗,这使得我们能够完整地展现出Arrow Lake H45处理器的性能。
缓存与内存
Arrow Lake SoC继承了Meteor Lake的大多数设计特点,与Lunar Lake的近乎单芯片设计不同,Arrow Lake仍然分为CPU、GPU、SoC、IO等几个组成部分。相应地,其内存和缓存结构也与Meteor Lake十分相似。
在大核方面,Arrow Lake H45拥有3 MB的L2缓存容量,这比Lunar Lake增加了0.5 MB;同时,L3缓存容量也达到了24 MB,是Lunar Lake的两倍。然而,这种提升并不是没有成本的:Arrow Lake H45继承了Meteor Lake的ring频率较低问题,即使其核心运行于5.1 GHz,ring频率也仅仅只有3.9 GHz。相比之下,Lunar Lake在核心运行于4.8 GHz时,其ring频率可达4.4 GHz。
与Lunar Lake的Skymont LPE不同,Arrow Lake H45的8个Skymont核心都位于ring上,可以使用24 MB的L3缓存,这使得其性能得到了显著增强。
由于Arrow Lake H45没有类似Lunar Lake的MSC,它的Crestmont LPE核心可使用的缓存仅仅只有2 MB的L2,性能极其受限,与Lunar Lake的Skymont LPE不具备可比性。由于这个LPE核心完全继承自Meteor Lake且并未发生任何改变,本文不关注它。
这些设计差异使得Arrow Lake在性能与能效方面与Lunar Lake处于不同的平衡点,这也是本文的主要关注对象。
访存延迟
Meteor Lake在重新设计Fabric并引入chiplet多芯片封装之后,其内存延迟相比前代显著退步,一直被人诟病。较低的Ring频率也使其内存和缓存延迟进一步恶化。此外,Meteor Lake的研发过程也非常不顺利,经过多次重设计(respin)和数次延迟后,交付给OEM的样品仍然存在众多bug。
Arrow Lake的非核心部分(uncore)复用了Meteor Lake的设计,理论上继承了所有Meteor Lake的设计问题。然而,经过一年多的改进和打磨,其完成度理论上应该有所提高。以下,我们将通过一些经典的内存访问测试,对Arrow Lake、Lunar Lake、Meteor Lake和Strix Point进行对比。
大核
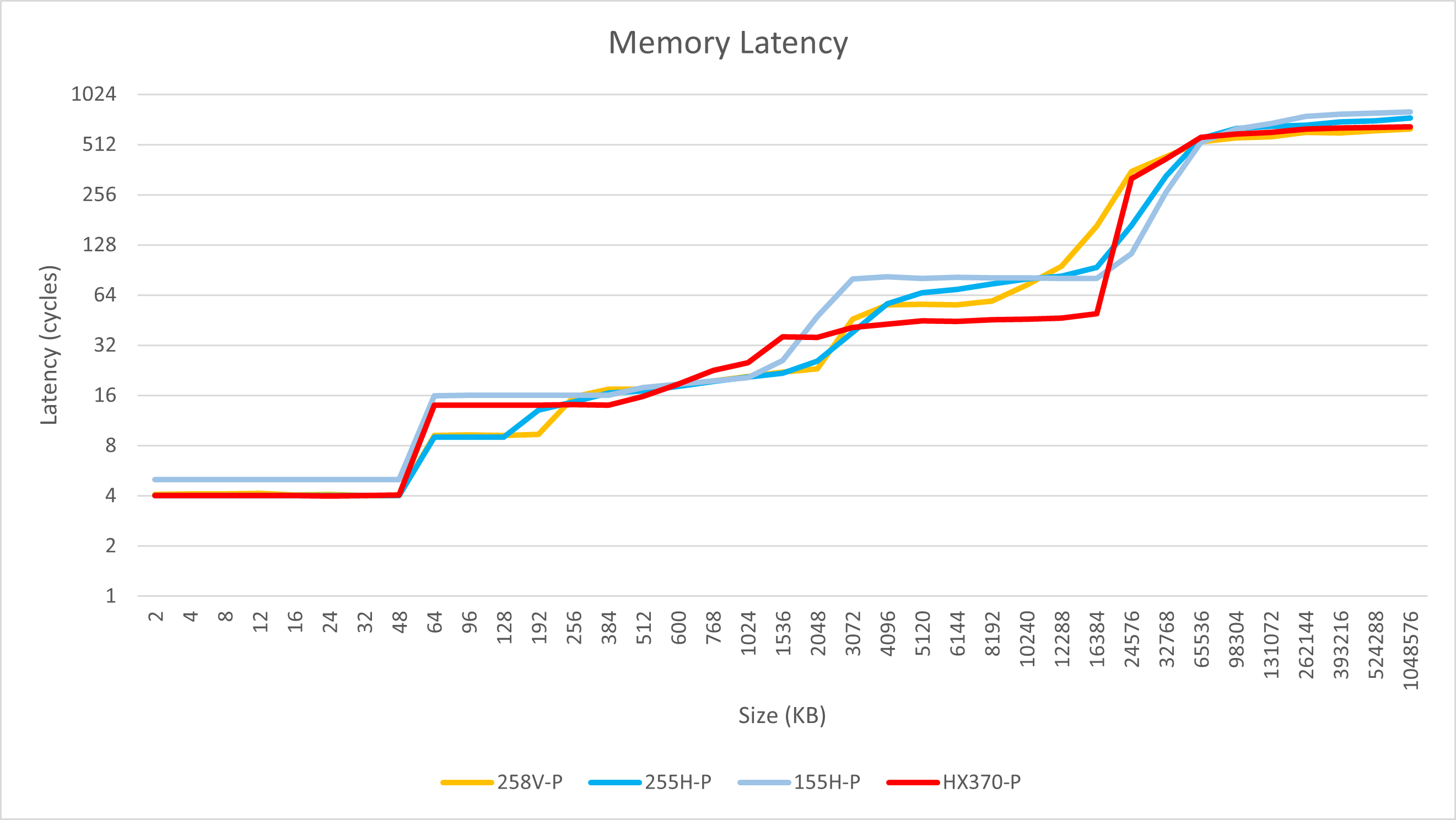
在进行访存测试时,我们发现Arrow Lake在L0、L1、L2层面的表现与Lunar Lake大同小异。但是,当到了L3层面时,其性能特征开始更加接近Meteor Lake。在8 MB这个测试点上,255H的延迟达到了75周期,接近155H的81周期,远远高于258V的59周期和HX 370的45周期。尽管255H拥有远大于HX 370的L3容量,但其访问L3的代价却比HX 370高出80%,这将大大抵消这一层缓存的命中率优势。这种现象在后面的SPEC整数测试成绩中也会有所体现。
然而,Arrow Lake / 255H在访存方面并非完全没有好消息。在同样使用LPDDR5x配置的情况下,255H显著降低了内存的延迟。在1GB测试条件下,255H的访存延迟为145ns,而155H则为167ns。尽管255H相比258V的131ns和HX 370的127ns仍然存在一定差距,但考虑到MCM设计的特点,这种差距是可以理解的,而非像Meteor Lake那样无法接受。
我认为,155H的内存延迟可能是由于早期BIOS不成熟,或SoC的errata导致的。
小核
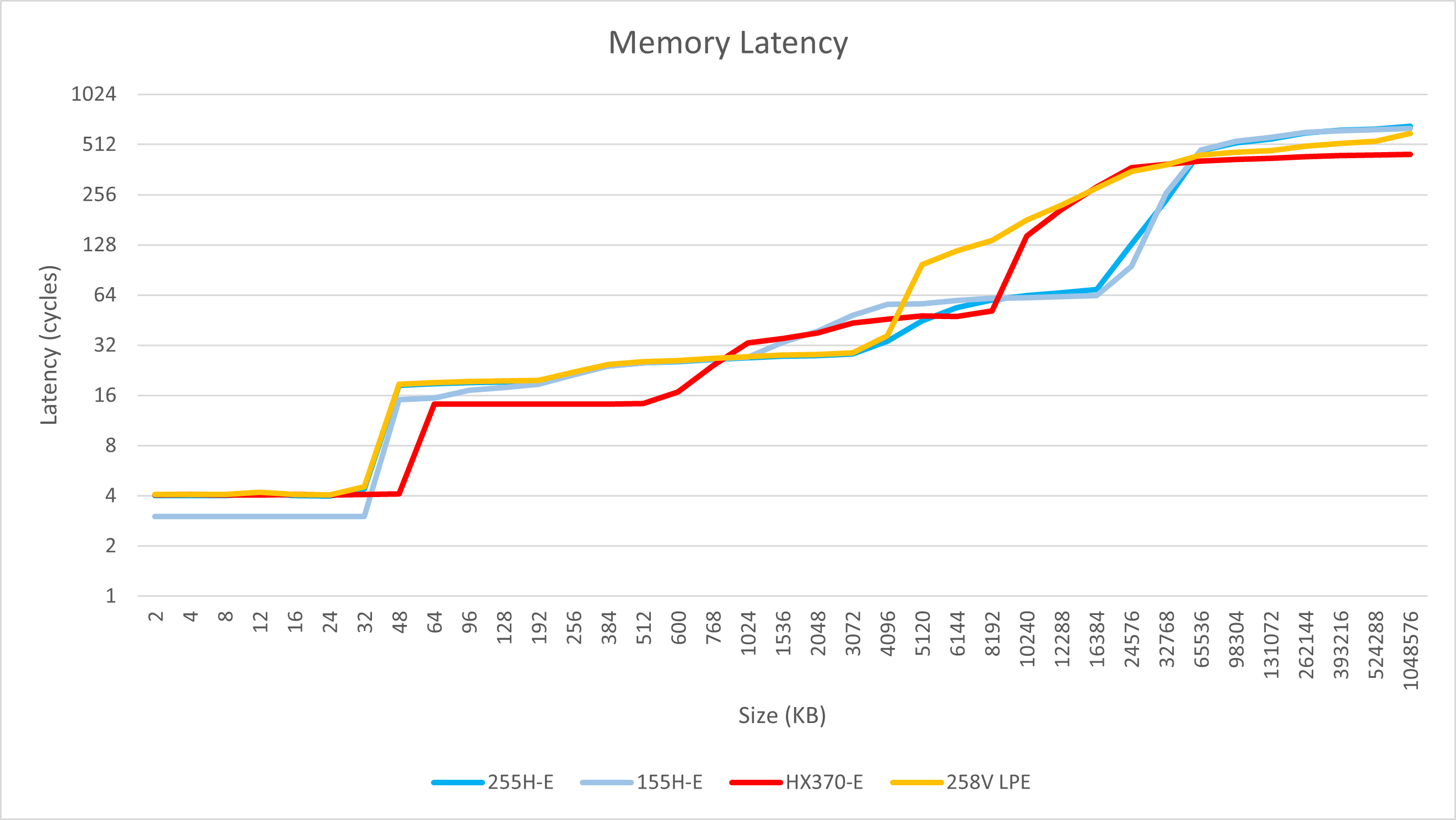
Arrow Lake的小核心在访存方面表现更像是在Lunar Lake的LPE核心基础上加上了L3缓存。255H的小核心在L1、L2范围内的延迟特性与258V完全相同,而在L3、内存方面则与155H相仿。
带宽
除了延迟之外,带宽也是决定访存性能的一个关键因素。随着现代CPU的普及和SIMD的广泛应用,许多应用程序的性能瓶颈开始出现在缓存、内存等的带宽上。
单线程
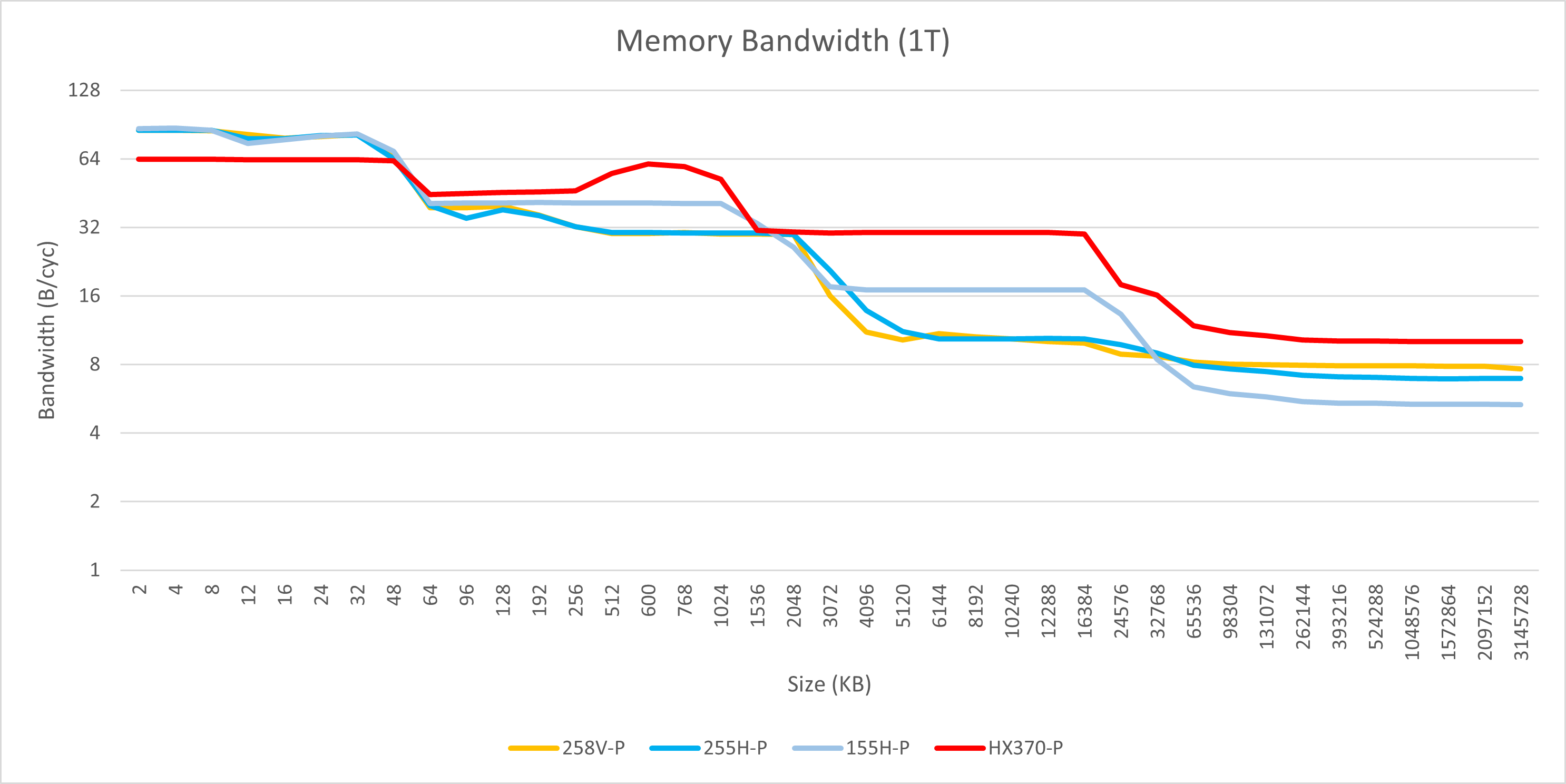
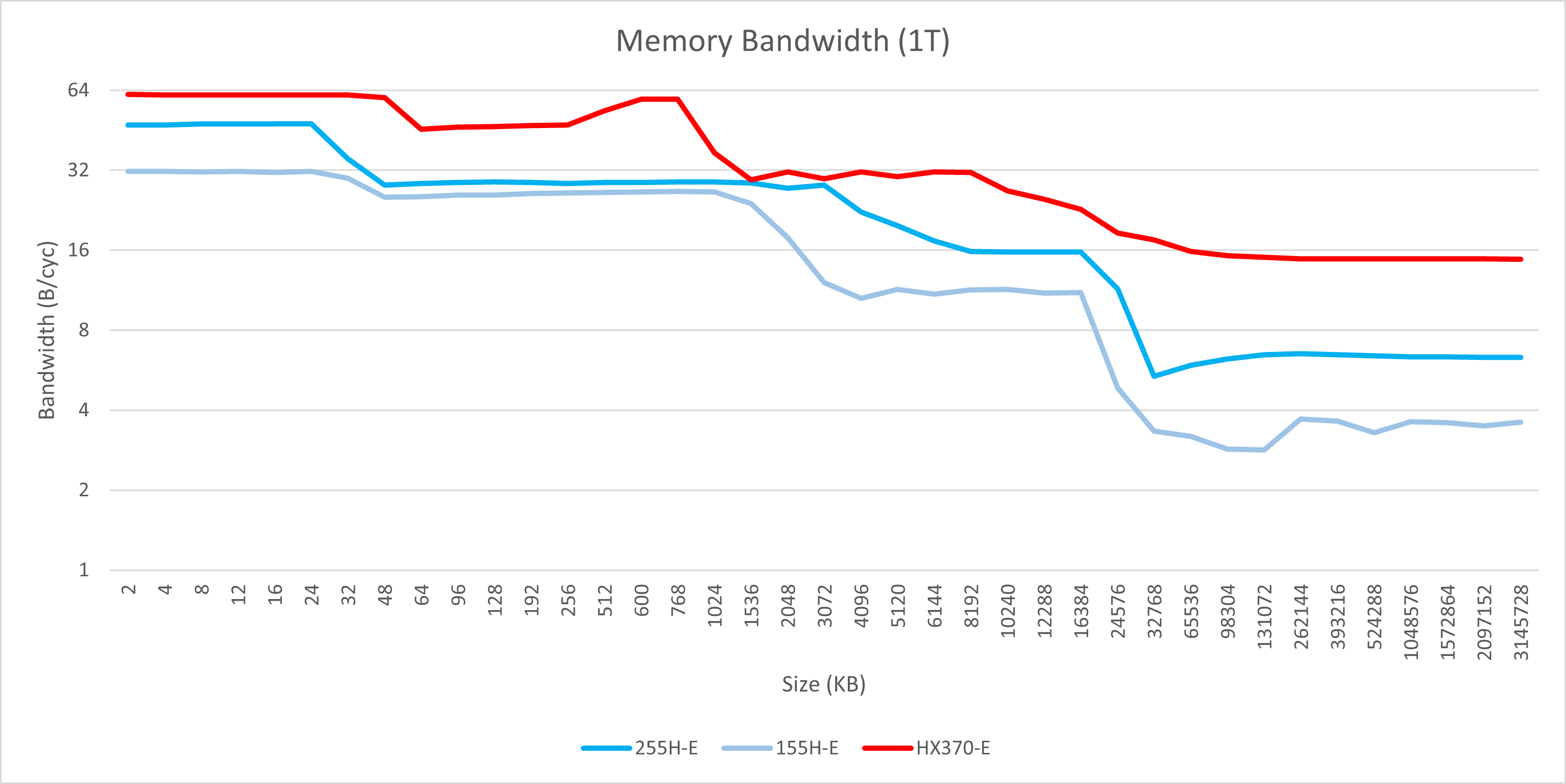
不幸的是,Arrow Lake的大核在这一方面并没有表现出相应的提升,反而与Meteor Lake相比有所下降。具体来说,L1的吞吐量维持在每周期96字节,但L2的带宽却从每周期48字节缩减至32字节,L3更是大幅缩水至每周期仅10字节。
相比之下,Arrow Lake的小核在带宽方面取得了显著的提升,其L3带宽甚至达到了每周期16字节,超越了大核的表现。
与AMD的HX 370进行对比后发现,Arrow Lake大核的优势主要体现在L1的带宽上,每周期可提供3*32字节的向量读取,而HX 370只能实现2*32字节。即使是在桌面端具备完整AVX-512指令集的处理器,也仅支持每周期2*64字节的向量读取,无法在每个周期内分别对三个不连续的地址进行读取。
Intel大核在L2、L3以及内存带宽方面的全面落败,也意味着在数据量较大、计算访存比较低的应用场景中,Arrow Lake可能难以展现出其优势。
不过,从另一个角度来看,Arrow Lake的大幅增加L2缓存容量,使其总容量超过了L3,这也意味着L3缓存的设计重点可能转向为降低轻度负载应用(如游戏)的延迟,而不是向多个核心提供高吞吐。同时新增的“L1.5”缓存也可以降低L2的压力,因此纸面参数和理论性能测试并不一定会影响实际性能。
多线程
这里我们分别针对Arrow Lake、Meteor Lake、Strix Point的全大核与大核+小核的组合进行多线程带宽测试。
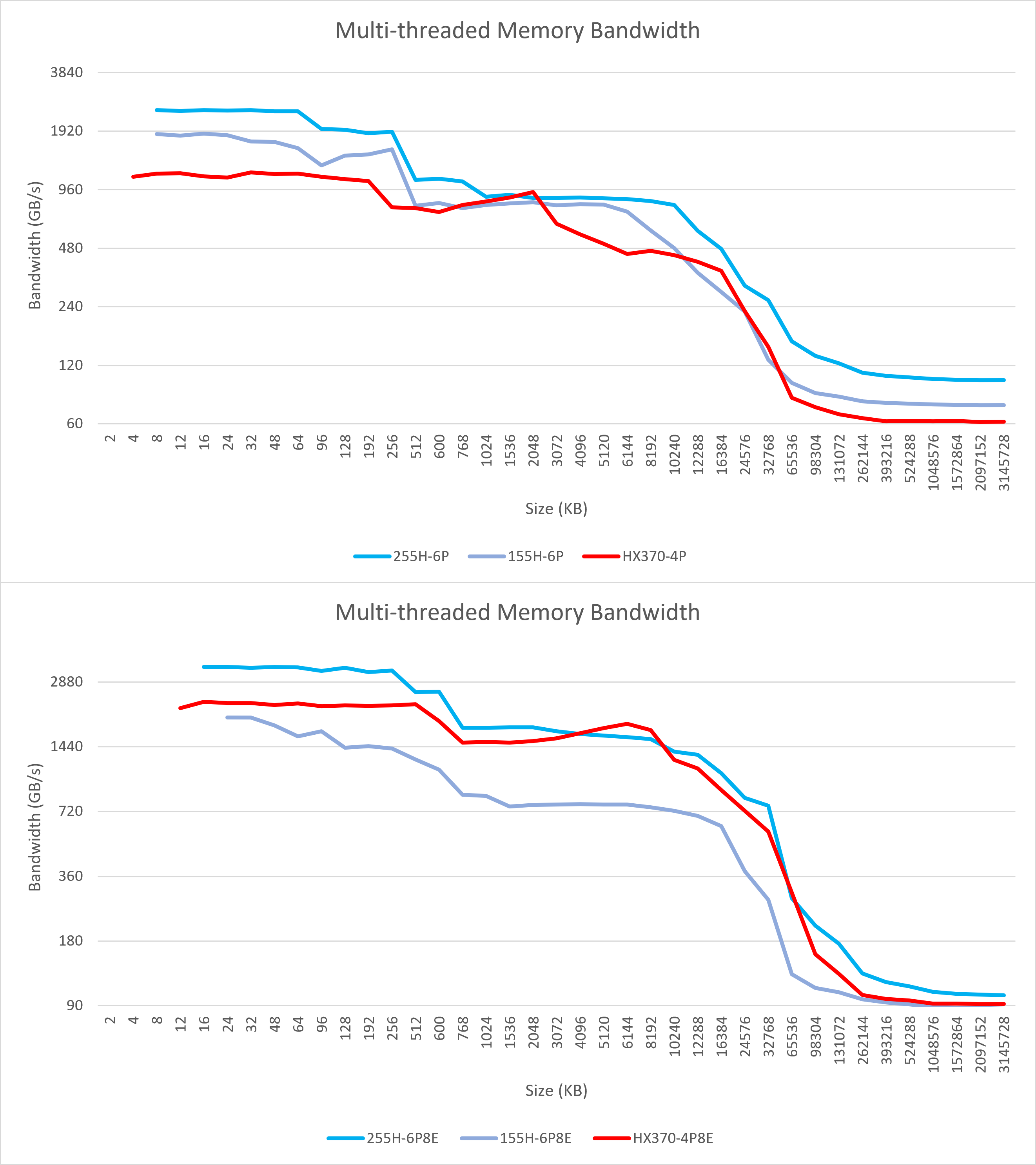
测试结果显示,由于255H的频率优势,再加上在多线程的带宽测试中绝大多数区域由L2而非L3覆盖,因此在单线程带宽测试中观察到的L2、L3带宽下降并不明显。255H整体上仍然实现了巨大的提升。
同步延迟
传统的Intel笔记本处理器通常采用单个环形总线结构,所有核心都连接在这个总线上。然而,Meteor Lake处理器首次引入了环形总线以外的LPE核心,这一设计也被应用于Arrow Lake和Lunar Lake处理器。
这种设计带来的好处是,当使用LPE核心运行后台负载时,可以避免唤醒大、小核的环形总线,从而降低待机功耗。但是,LPE核心位于环形总线之外,这也意味着维护缓存一致性的开销会增加,类似于AMD和Apple的多CCX/多cluster设计。
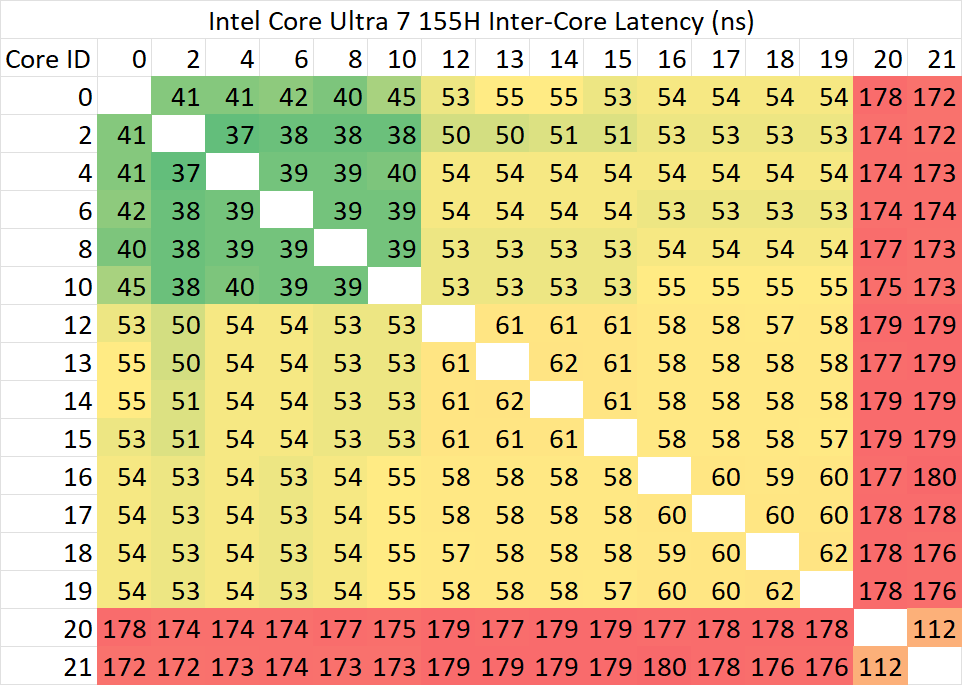

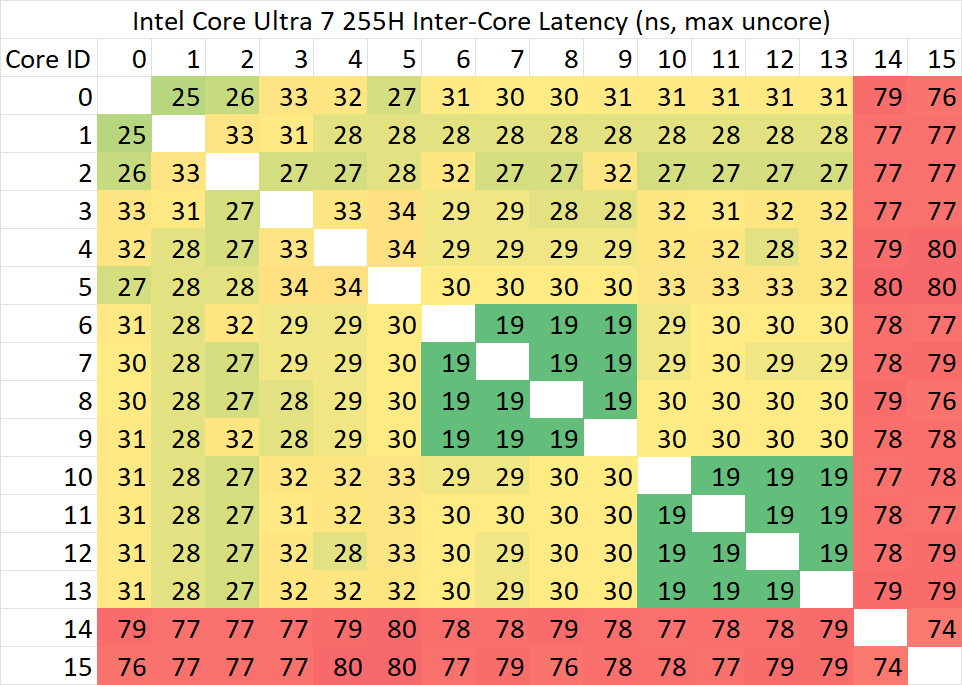
为了测试核心间的通讯延迟,我们使用了cmpxchg指令,可以发现Meteor Lake和Arrow Lake处理器在这一方面表现出高度的相似性。目前观察到的Arrow Lake处理器上的主要变化是,Skymont簇内具备了更快处理一致性请求的能力,因此同簇的小核之间的通讯延迟得到了显著降低。
但是,这一结果与前日参与Arrow Lake H45产品首发营销的某笔记本类数码媒体的测试结果存在较大差异。在他们的测试结果中,普通核心与LPE核心的通讯延迟仅仅只有不到80ns。经过进一步观察,我们发现,无论是Meteor Lake还是Arrow Lake测试出170ns+的延迟主要是因为SoC uncore处于节能状态。在量产版本的机器上,需要手动在后台运行一个内存负载才能将uncore频率带到较高水平。与此同时,我们合理怀疑Intel提供的工程机可能将D2D/SoC等锁定在最高频率,以提升测试性能。这一行为也将影响这些首发营销媒体的其它测试。
当我们使用上述方法提高uncore频率之后,可以看到255H的LPE核心同步频率达到了预期水平。当然,这一性能仅存在于理论,因为Meteor Lake和Arrow Lake处理器只要使用了环形总线上的核心,就不会使用LPE小核。
GPU
在测试CPU之外,我还进行了若干GPU内存访问测试。由于不同工具在不同GPU微架构上的表现略有差异,我使用了多种工具进行更全面的测试。
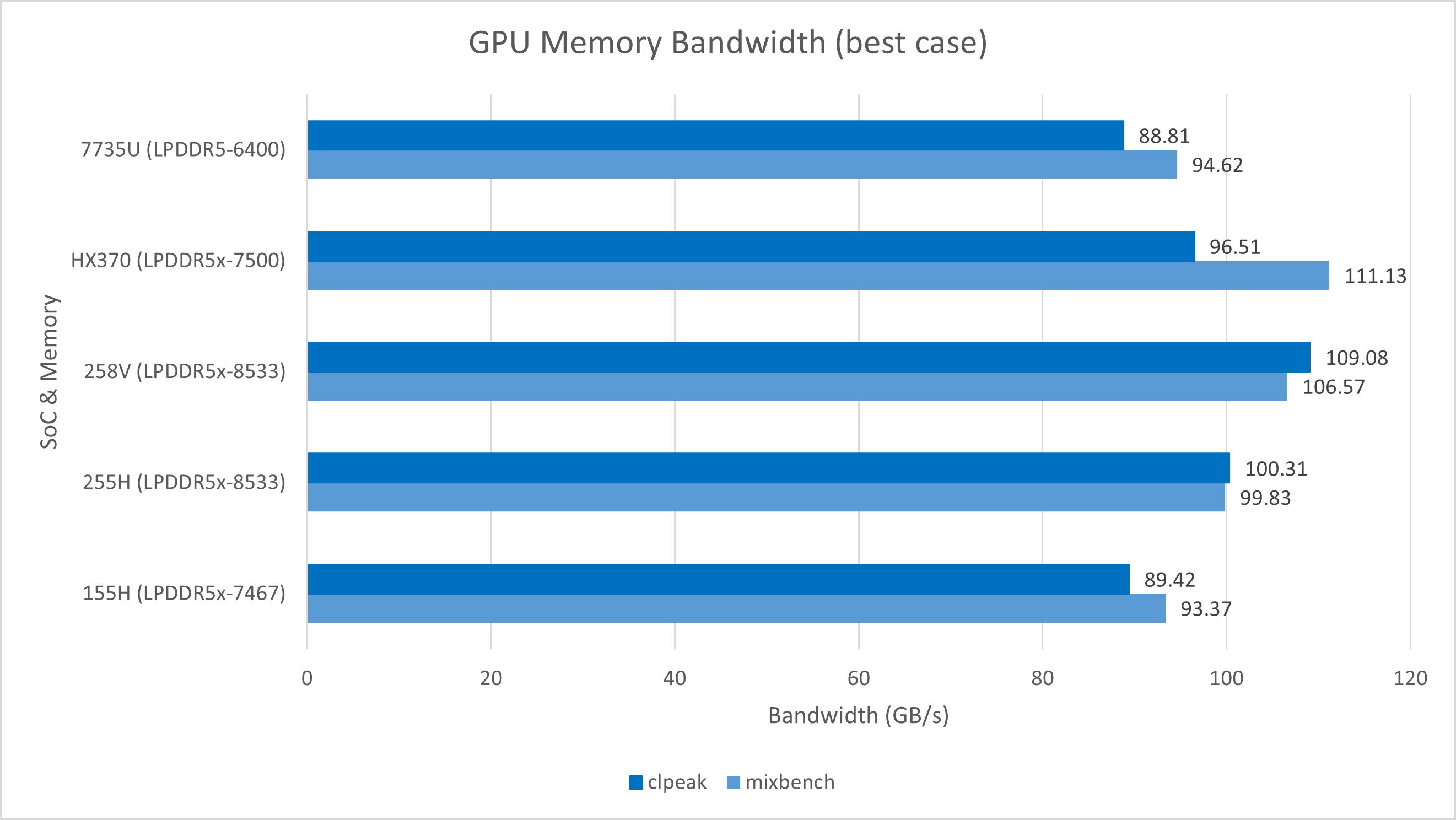
通过不同的工具,我们发现255H相较于155H提升了内存频率,因此带宽也相应提高。在clpeak和mixbench的带宽测试中,255H的带宽值介于155H和258V之间,约为100 GB/s。这一结果也略高于HX 370(LPDDR5x-7500)在OpenCL中的性能。
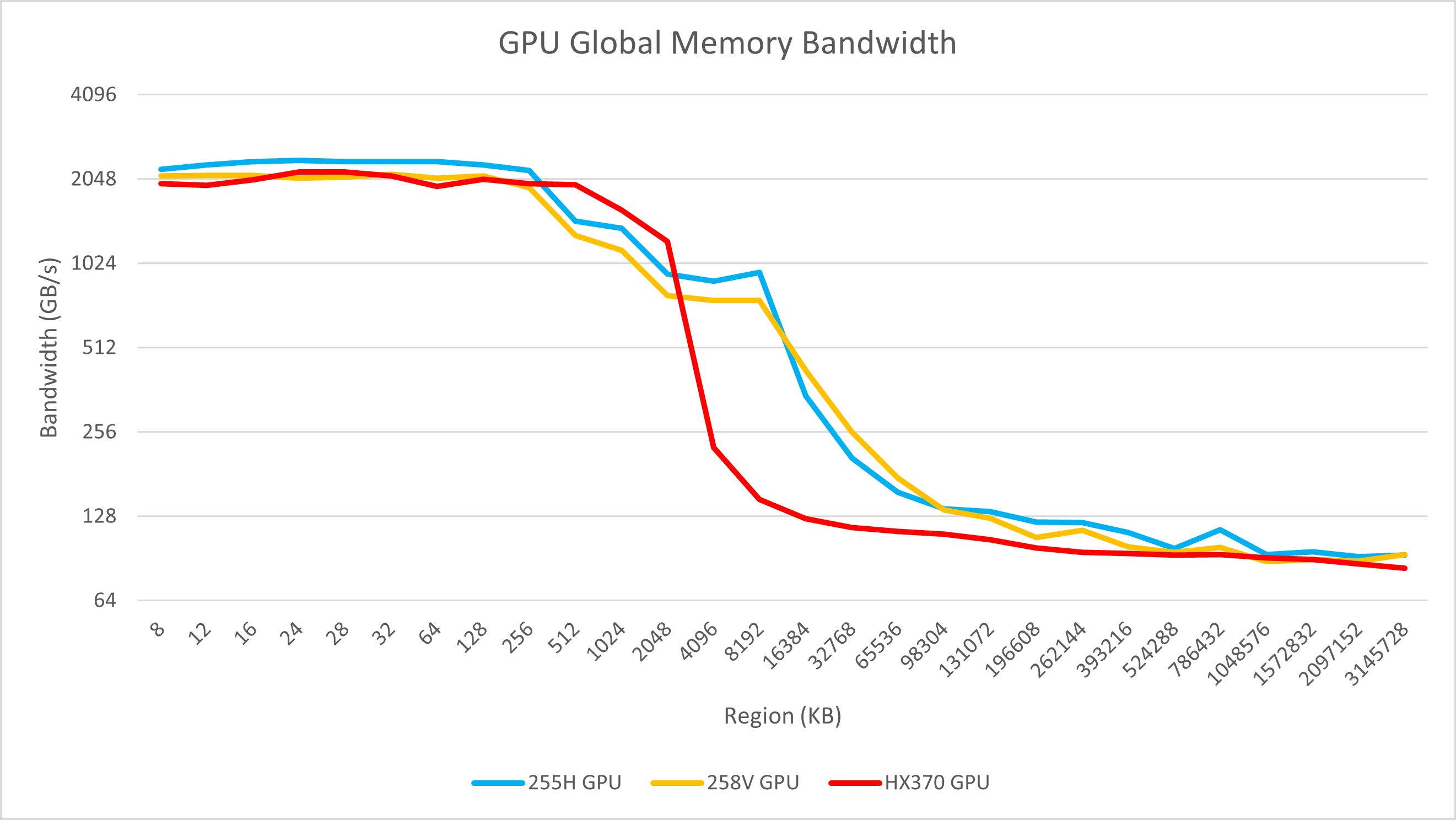
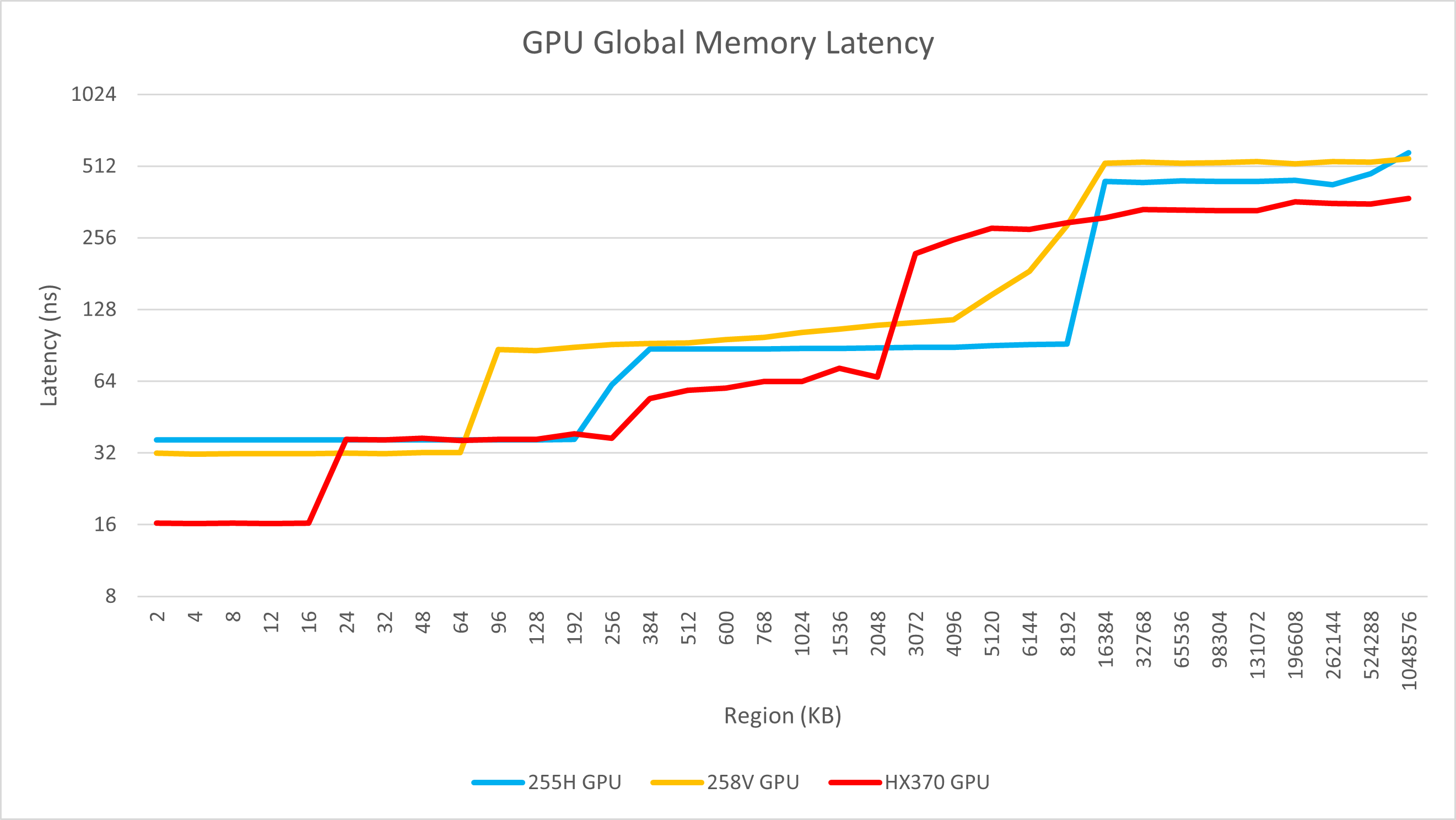
从GPU的延迟与带宽曲线中,我们可以看到255H与Intel其他核显一样,拥有显著超过竞争对手的缓存容量。其L2缓存高达8 MB,甚至超过了AMD独显中最大的L2缓存(7900 XTX的L2容量仅为6 MB)。这些数据表明,Arrow Lake的GPU具有比HX 370更优越的基础条件,付出了更高的成本。当然,本文并非以GPU测试为重心,因此这里不作更多详细的测试与分析。
性能
由于移动端处理器的功耗标准并不统一,本小节我们将重点关注单线程的表现,而多线程相关的测试将在能效测试中进行比较。
SPEC CPU 2017
尽管255H与258V的微架构相同,但它们在缓存和内存配置上的显著差异对SPEC CPU测试结果产生了显著影响。此前我在Lunar Lake测试中直接比较了258V和155H,但实际上由于缓存的差异,这种比较并不完全合理。255H相对于155H的性能提升更能代表Lion Cove和Skymont微架构的改进。
默频性能
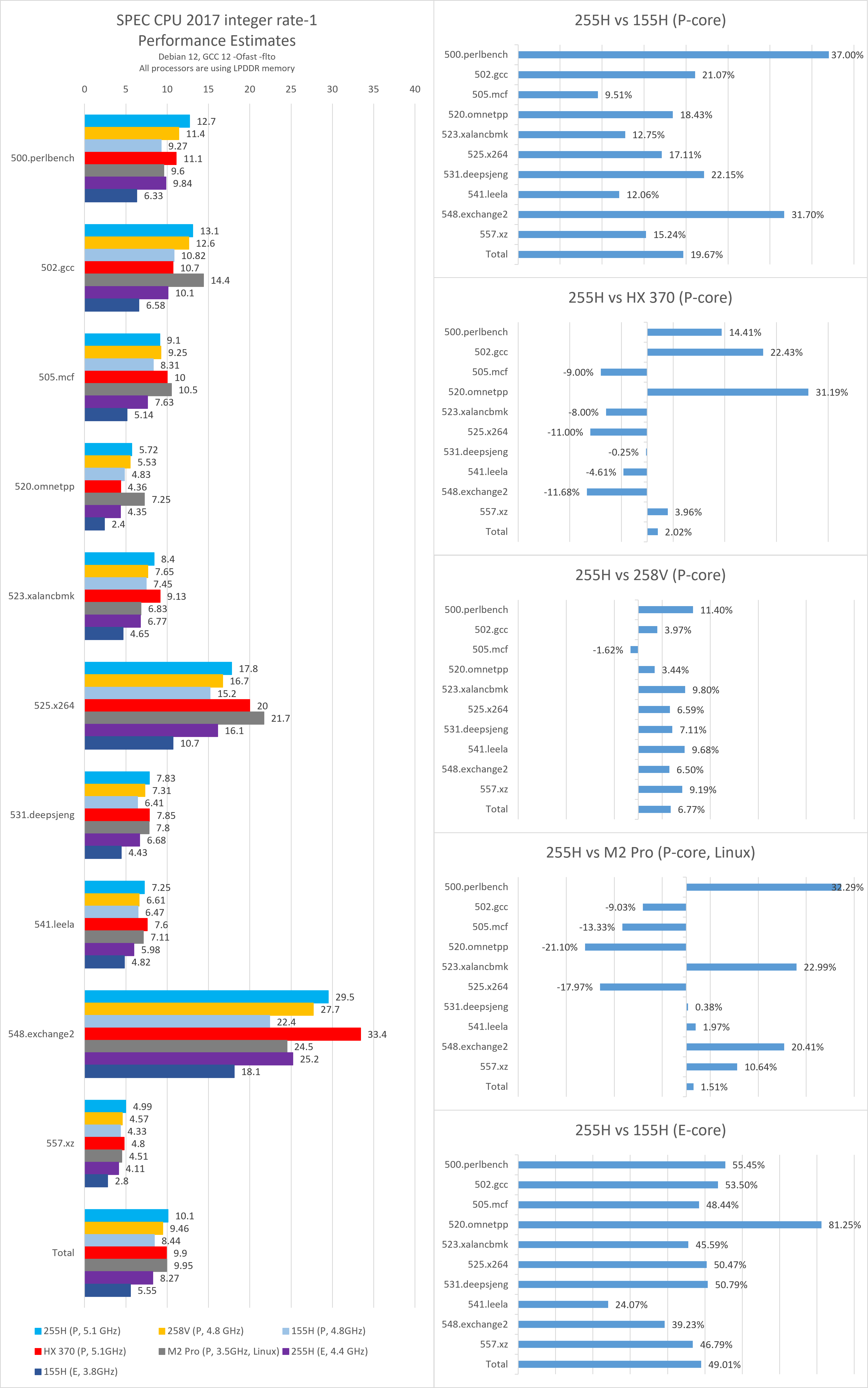
在默频测试中,
- 255H的Lion Cove大核相对于155H的Redwood Cove大核,性能提升了大约20%,其中频率提升了约6.25%。
- 与频率同为5.1 GHz的HX 370相比,255H整体性能略高约2%。
不过,考虑到HX 370仅拥有16 MB的L3缓存且实际测试过程中存在较明显的降频现象,这个性能优势并不算突出。 - 255H的Skymont小核在默频下,通过15%的频率提升,实现了近50%的性能提升,达到与155H的Redwood Cove大核相近的水平。
- 与258V相比,255H的Lion Cove大核理论上具有频率和缓存容量的优势,但由于较高的缓存和内存延迟,部分子项的表现受到影响。
同频性能 / IPC
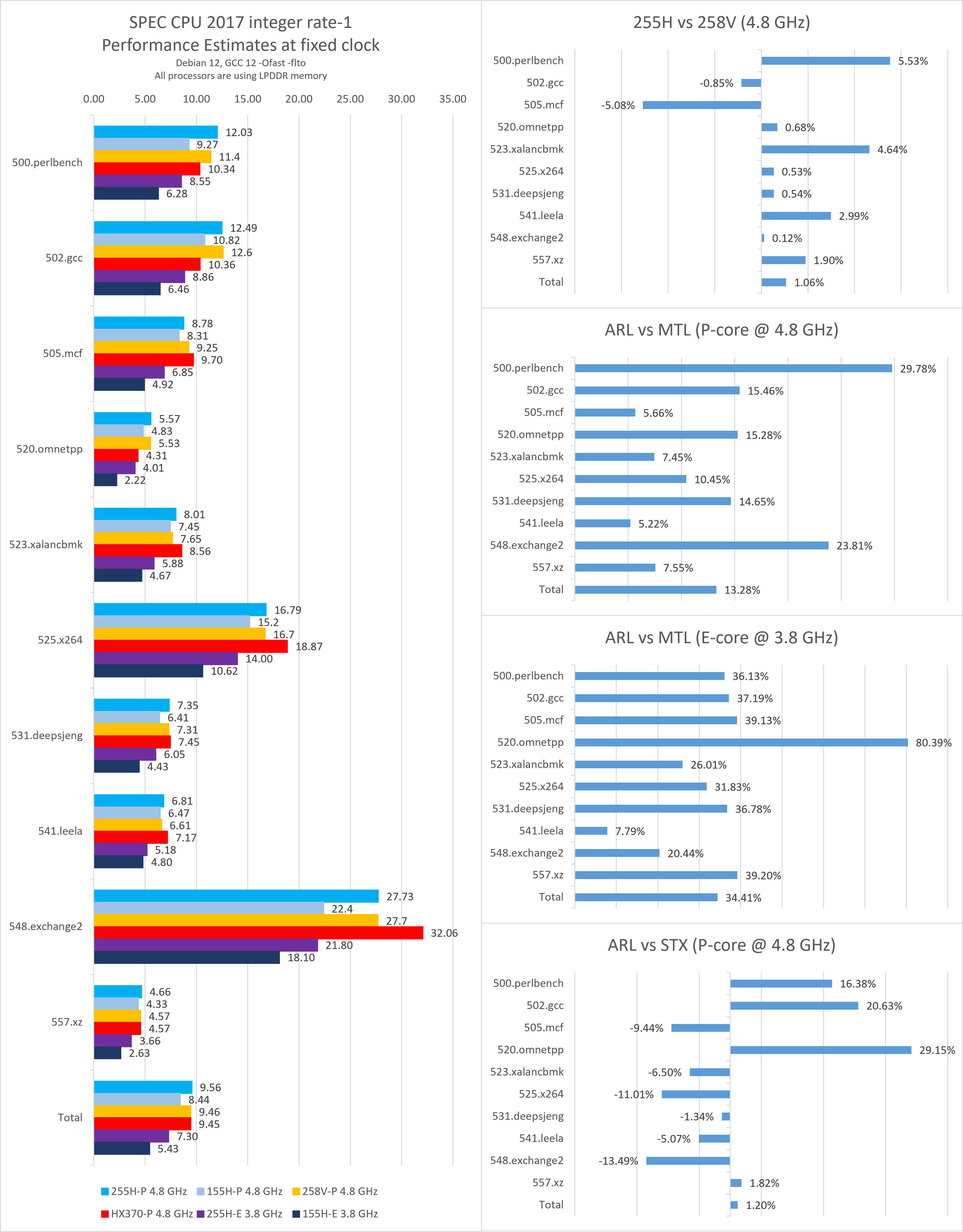
将所有大核设定为4.8 GHz,小核设定为3.8 GHz进行测试,以观察本代处理器的同频性能:
- 255H与258V在同频下的综合性能差异极小,但在具体子项上差异最高可达5%,其中gcc、mcf测试中255H表现不如258V。
- 255H与HX 370的综合性能差异缩小到1%左右,最大的优势来自于对缓存容量敏感的子项,如520.omnetpp。
- 255H的Skymont小核在同频下相比155H的Crestmont性能提升了34%。
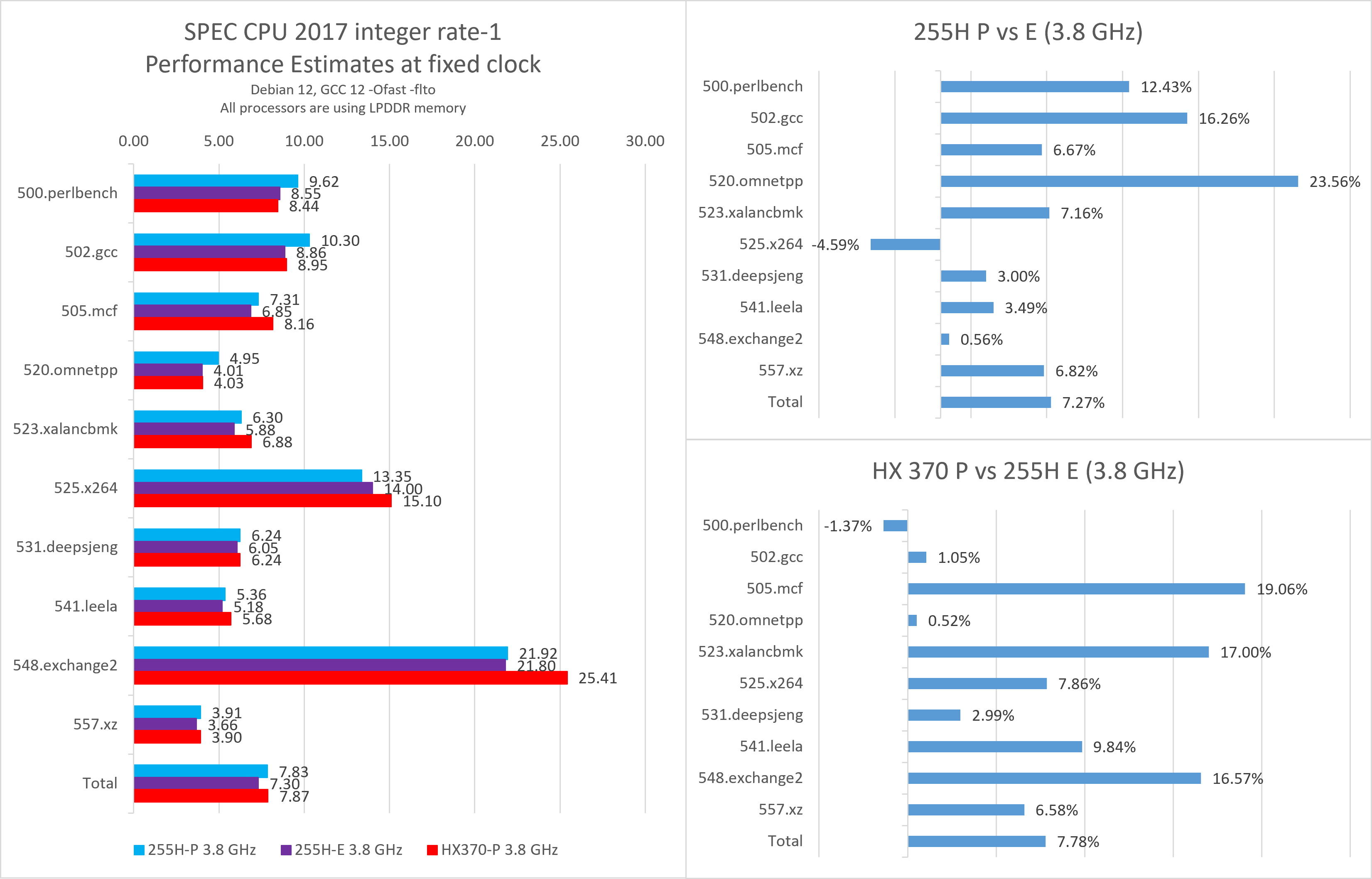
如果将255H和HX 370的大核与小核均设定为3.8 GHz,可以发现本代的大核相比Skymont小核的同频性能仅领先不到8%。
Geekbench
在Geekbench 5/6的单线程测试中,255H的综合表现与SPEC CPU测试结果类似,因此不作过多分析。
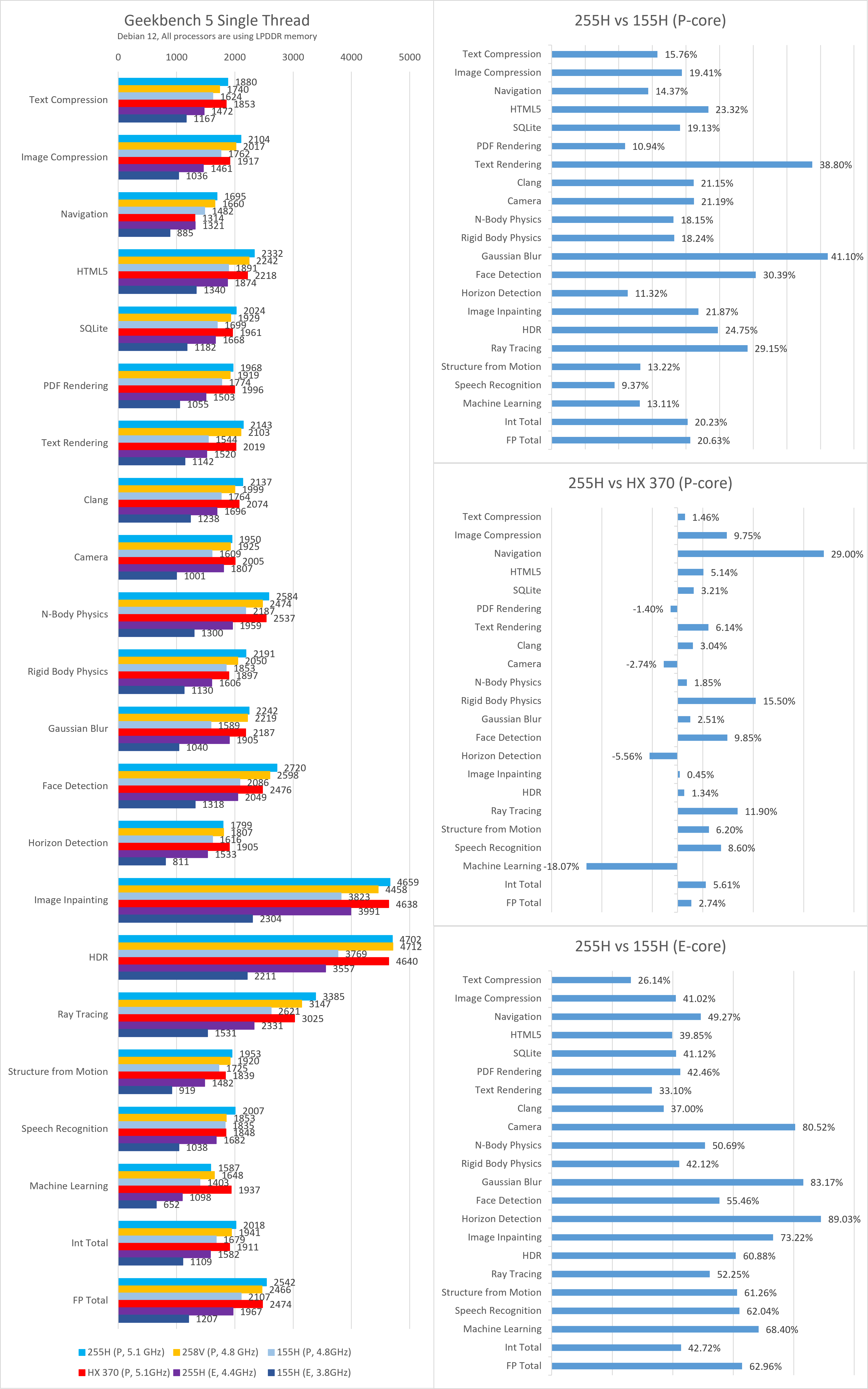
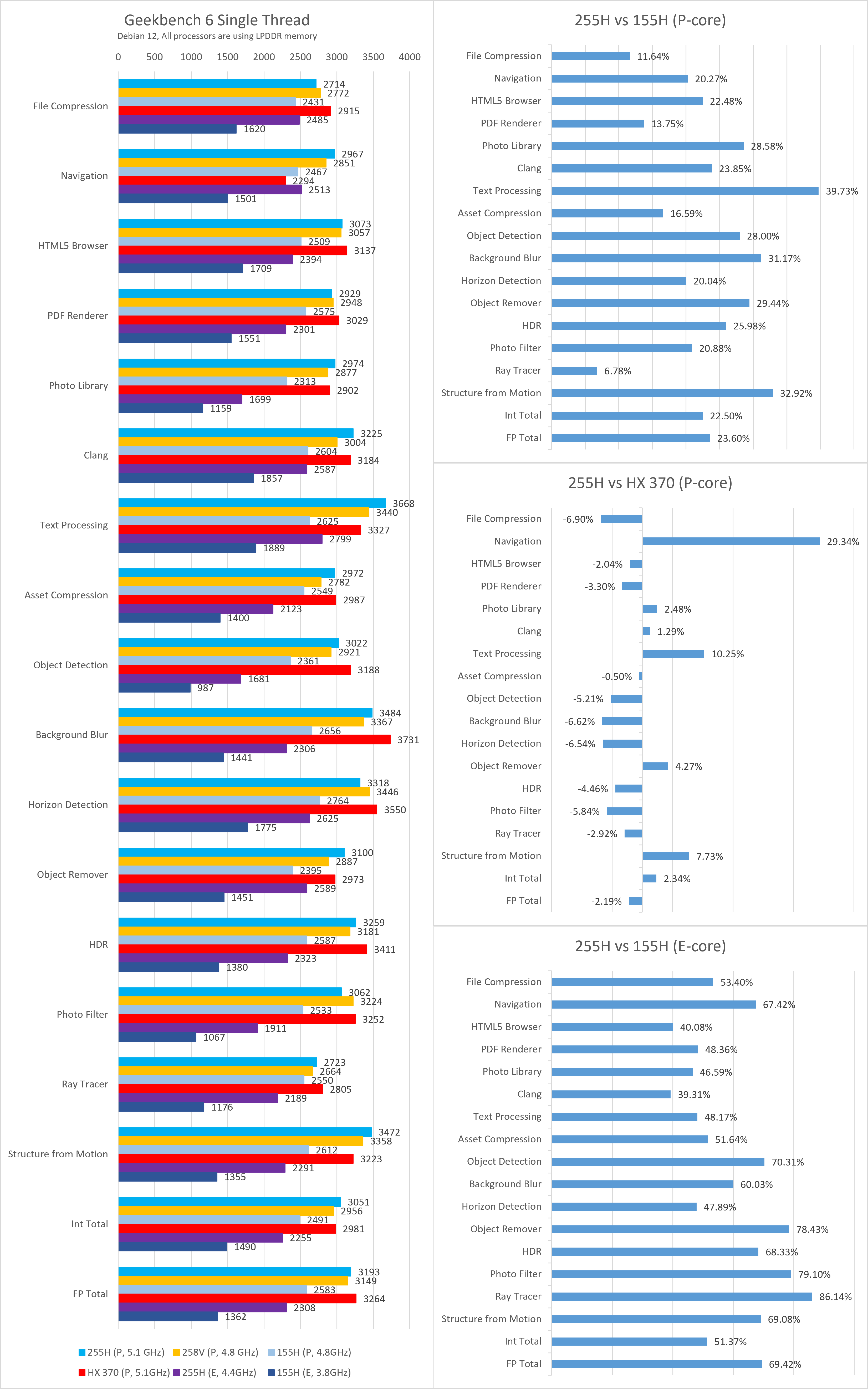
功耗与能效
与Lunar Lake类似,Arrow Lake是Intel首次在主流产品中使用台积电工艺制造CPU核心,采用了与Lunar Lake相同的台积电N3B工艺。鉴于台积电近年来在低功耗产品上积累的良好口碑,以及Lunar Lake在能效方面表现出色,Arrow Lake在能效方面也令人充满期待。
接下来,我们将从多个不同角度来评估Arrow Lake的大核心和小核心的能效表现,包括单线程、4-8线程以及全核心能效,与Lunar Lake和HX 370进行比较。
用于对比的HX 370机型的功耗限制仅为28W,即使使用RyzenAdj等工具也只能解锁到持续稳定在32W左右,因此本文并未展示HX 370的完整性能。散热更好的HX 370机型可以将CPU功耗提升到80W。
由于SoC package功耗会受到多种因素的影响,本文在绘制能效曲线时只对比核心功耗。
单线程
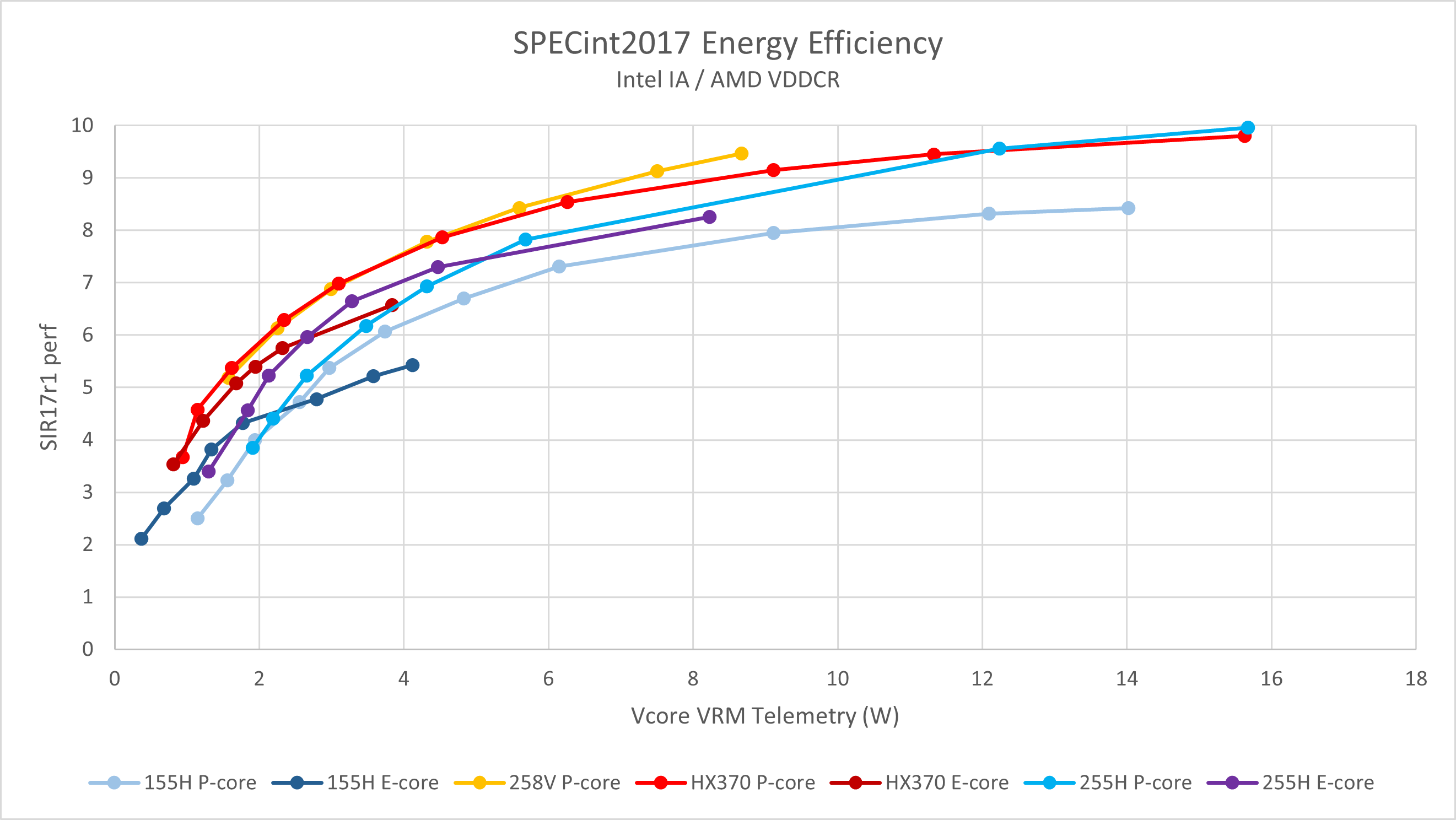
单线程能效表现是衡量日常使用体验的重要指标,也是Intel近年来与行业竞争对手差距最大的一项。Lunar Lake的大核心在这项测试中与HX 370基本持平,小核心在低功耗条件下更是远超竞品,这是其出色日常体验的基础。
然而,Arrow Lake的表现并不像Lunar Lake那样乐观。虽然255H Lion Cove大核心在高功耗段的单线程性能略胜一筹,小幅度超越了HX 370和258V,但其能效随着功耗的降低逐渐接近155H的Redwood Cove。Arrow Lake的Skymont核心与Lunar Lake的Skymont LPE相比能效差距明显,其在整个功耗范围内的能效表现相比Lion Cove均无明显优势,也逊色于HX 370和258V的大核心。显然,将Skymont核心挂载在环形总线上并设定4.4 GHz的最高加速频率虽然提升了性能,但也付出了显著的能效代价。
多线程
处理器的能效并非固定值,通常情况下,电压和频率越低,能效会越好。因此,更多的核心数通常意味着在能效曲线的特定范围内可以获得更高的能效比。为了公平对比不同微架构,我们提供了多组数据:一组4核心,另一组6-8核心。
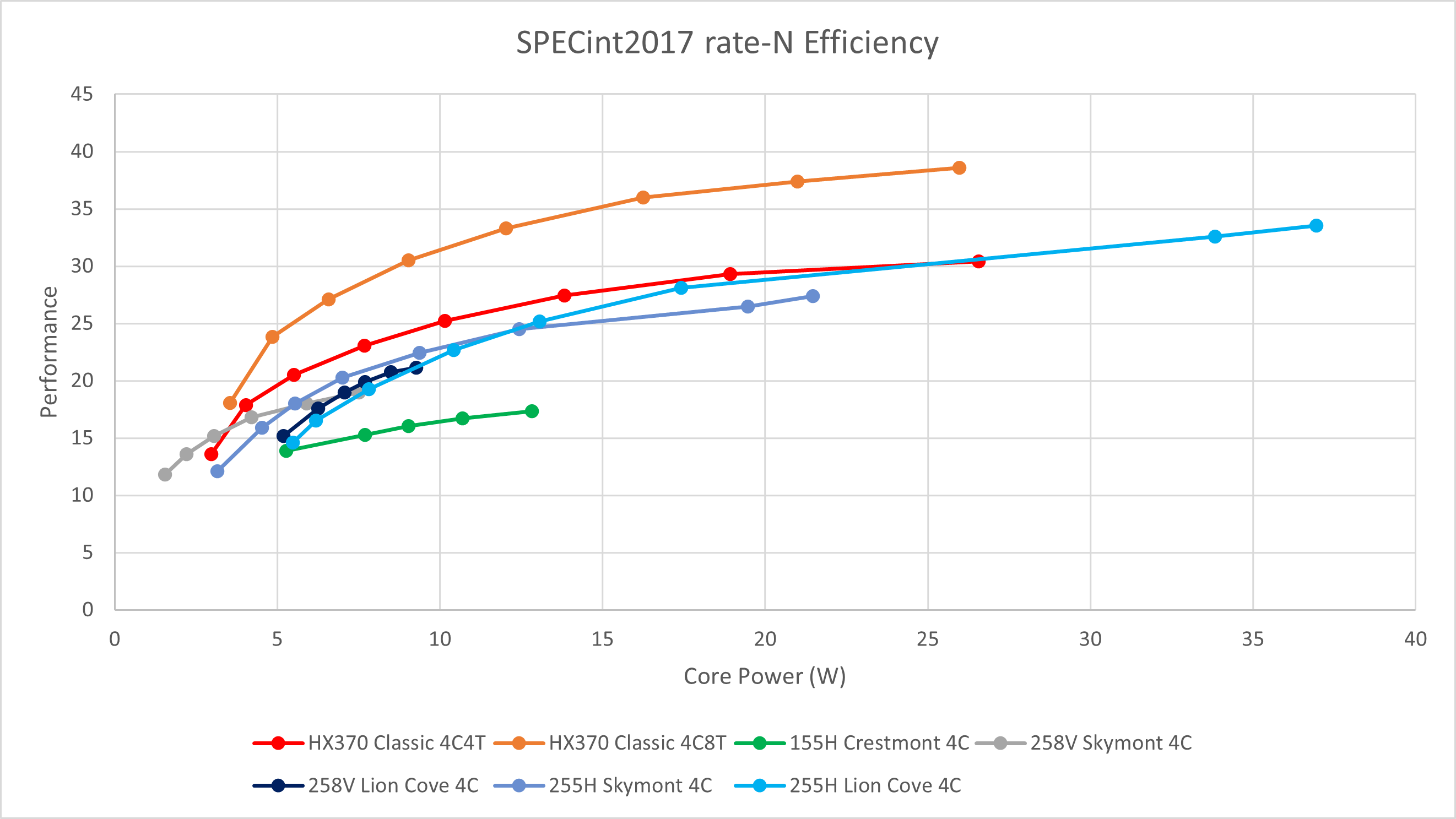
在4核心测试里,
- 255H的大、小核心各自维持了与单线程相似的趋势。
- 255H相比155H小核心的高功耗性能提升达到了45%左右,相比单核测试不再显得那么尴尬。当然,低功耗性能并无明显提升。
- Lunar Lake (258V)大核的低功耗能效优势缩小到忽略不计。
- 与Lunar Lake (258V)的Skymont LPE小核心相比,255H挂在ring上的Skymont小核心更像是“另一种大核心”,其能效曲线全程都并没有展现出显著更省电的趋势,当然也没有像Alder Lake / Raptor Lake那样在大部分情况下能效不如大核。
- 与4核4线程的HX 370测试配置相比,255H的大核使用4线程可以在高功耗段达成近似的性能。
但由于Lion Cove缺少SMT,因此在面对4核8线程的HX 370时会显得非常乏力,即使跑满频率,也会有大约15%的性能差距。 - 如果不考虑SMT,HX 370 4大核相比255H同样4大核的主要性能优势在于功耗不超过25W的场景。如果考虑SMT,则是全程大幅度领先。
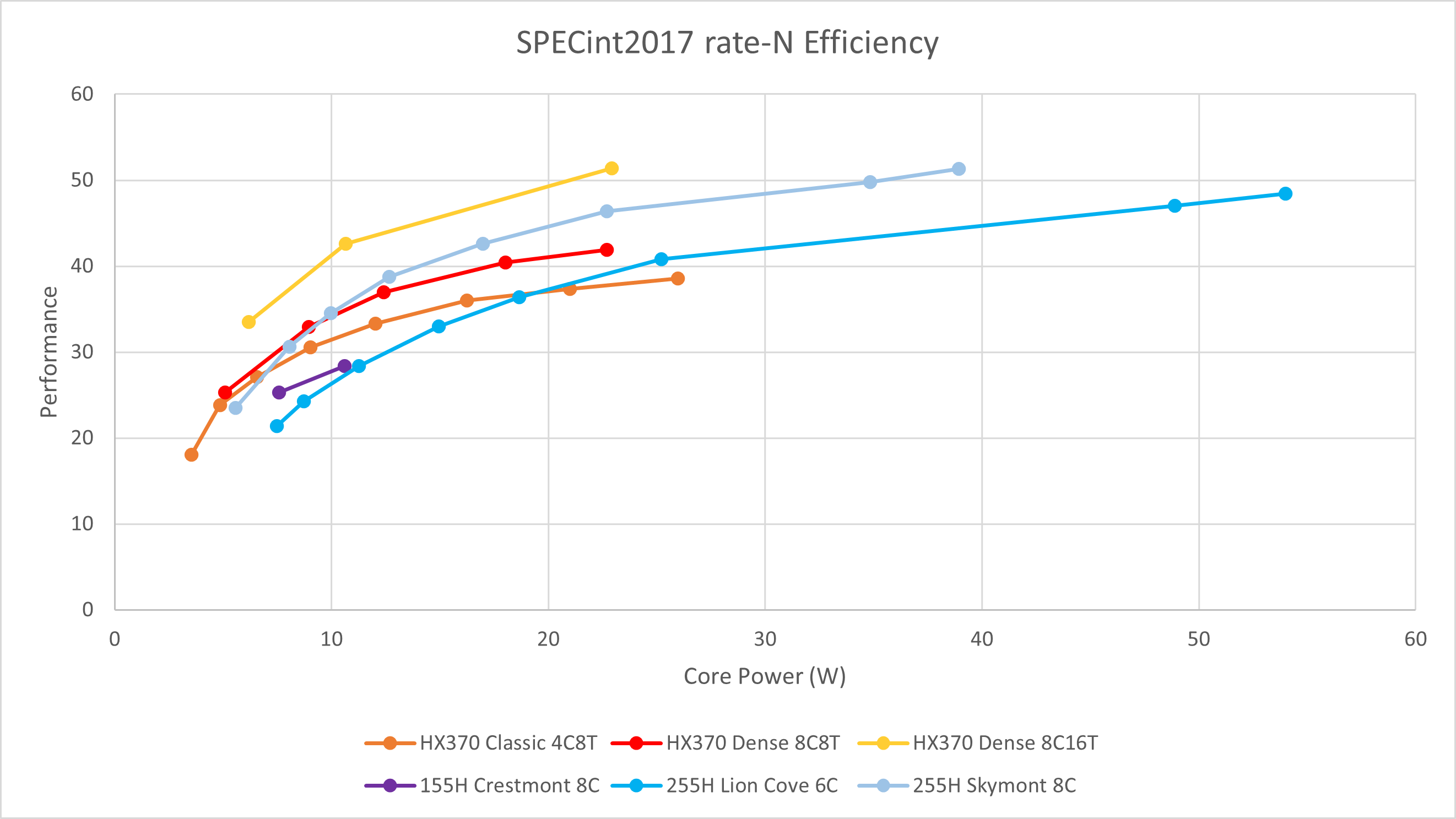
将目光放到6-8核心的测试,
- 255H 6大核的性能与能效不尽人意。尽管其占用了更大的面积,但是其能效全程被8小核超越,20W以内甚至会输给4核心的Zen 5 classic。
- 255H 8小核的高功耗性能、能效介于HX 370 8小核开关SMT之间,10W以下则被关闭SMT的HX 370 8小核超越。
- 255H 8小核在10W附近相比155H的提升约为20%左右,而Meteor Lake小核的频率限制使其无法进一步提升功耗,最终满功耗下的绝对被拉开将近70%的差距。
全核性能
以上能效曲线主要通过CPPC定频并记录RAPL功耗的方式制作。然而,对于大小核处理器,这种方法并不完全适用,因为大核和小核的频率并不相同(Meteor Lake的大核内部存在这一问题,因此未进行此项测试)。因此,全核心测试只能通过控制处理器PL的方式进行。
注意:此项测试中的HX 370 35W数据是通过RyzenAdj解除功耗限制的方式获取的,但实际上由于机型散热限制,功耗只能稳定在30-32W左右。
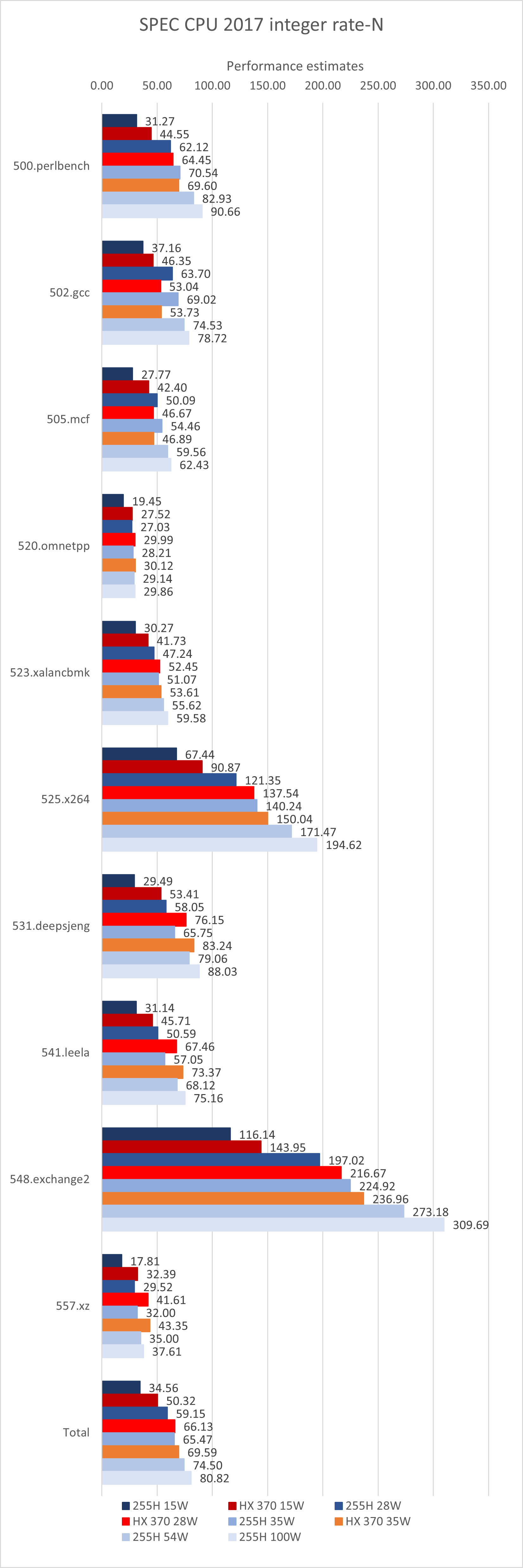
从全核心测试结果可以看出,Intel官方设定的20W最低功耗是合理的:6+8的规格在15W下性能明显下降。总体而言,255H的能效相对于HX 370略逊一筹,需要依赖较高的功耗才能达到相同的性能。
GPU LLM推理
尽管大多数用户选择使用类似ChatGPT的在线服务,最近两年PC本地运行LLM的营销也越来越多地进入我们的视野。因此,我在测试项目里也加入了一些GPU LLM性能测试。
测试环境
- (255H / HX 370) Debian 12 + 6.12.9 backports kernel
- (M4 Pro) macOS 15.1.1 + Metal
- (255H) Intel compute runtime 24.52.32224.5 + oneAPI toolkit 2025.0.1
- (HX 370) ROCm 6.3.1
- llama.cpp build: f0d4b29e (4585)
考虑到client平台许多LLM应用工具的实际情况,本次测试依然按照惯例使用上游版本的llama.cpp而非ipex-llm/vLLM/mlx-llm等硬件厂商推荐的方案,以方便对齐参数进行对比。
由于目前Intel平台没有可用的flash attention实现,本次所有参测平台均不开启flash attention,这样也正好省去了AMD平台手动patch flash attention kernel启用rocwmma的步骤。
llama-bench -m ./qwen2.5-14b-q4_k_m.gguf,./qwen2.5-14b-q4_0.gguf,./qwen2.5-14b-iq4xs.gguf,./qwen2.5-14b-q8_0.gguf,./qwen2.5-32b-iq4xs.gguf,./qwen2.5-32b-q4_0.gguf -n 64,128,256,512,1024,2048,4096 -p 64,128,256,512,1024,2048,4096 -mmp 0
在LLM测试里,255H核显的表现的既有亮点又有遗憾
- 输入处理 (prompt processing / prefill) 性能优秀,在超过256 token输入文本长度的场景下可以达到HX 370的两倍,甚至超越规格显著更大的M4 Pro。这一表现符合ARL这代核显新增XMX单元带来的吞吐优势。
- 文本生成 (text generation / decode) 性能很差,且无论是最新的SYCL还是运行于Mesa 24.3.1驱动的Vulkan后端均是如此。这一表现与255H的内存带宽完全不成比例,按照LPDDR5x-8533的实际测试带宽,它的表现理论上应该可以做到图中的两倍左右。
不难看出,Intel在LLM相关上游软件支持这方面依然有很大的改进空间。与ROCm/MUSA在项目里直接共用CUDA源码不同的是,SYCL独立于CUDA版本之外,且不像Apple平台本身是llama.cpp的一等公民。因此功能支持上存在很多的不足与滞后,目前很难与NVIDIA/AMD的解决方案竞争。
事实上,IPEX-LLM里的llama.cpp也是基于一个较旧的版本进行性能优化,因此并不能很快获得上游的新功能与改进,这也是我不喜欢测试这些专有方案的原因之一。
当然,在核显上运行此类测试总归还是有点娱乐的意思,不必太过于严肃看待这个测试结果。
总结
正如前文所述,许多人可能因为Lunar Lake的优秀低功耗表现,叠加Arrow Lake使用了同样的CPU核心和N3B工艺,从而对Arrow Lake的表现产生很多期待。然而现实却与之背道而驰,尽管Arrow Lake的性能和能效表现相比Meteor Lake进步巨大,但这依然是一个令人失望的处理器平台。
- 前代Redwood Cove相比Raptor Cove已经在性能上有着不小的倒退,Lion Cove的真实性能提升幅度是时隔2-3年却连10%的提升都做不到,还把SMT给砍了。
- Intel移动端的缓存容量普遍比AMD移动端APU要豪华的多,本代也不例外。
- 从Zen 3时期开始,移动端一直是Intel坐拥大L2 + 24 MB L3对阵AMD的小L2 + 16 MB L3。因此在SPEC这类对缓存容量较为敏感的测试里,Intel有着天然优势。
- 本代由于AMD的双CCX设计,对于单线程测试来说Intel依然享有这个规格优势,然而它带来的性能优势几乎被微架构差距抹平。
- 考虑到255H是一个N3B处理器而HX 370是N4P,本文实测的能效也很难让人满意。哪怕不考虑SMT等因素,Lion Cove的表现显然是高功耗优势不足,而低功耗完全惨败。
- 此前在Lunar Lake评测的文章里有读者评论认为N3B HP与N4P HD相比中低电压没有任何优势。
- 当时还可以借由Lunar Lake本身的低功耗设计(如功耗优化的MSC、MOP、PMIC等等)掩盖Intel微架构能效的问题使得其与AMD处理器的整体能效曲线贴近,但当Arrow Lake的Lion Cove中低功耗展示出如此惨烈的结果时又有多少理由可以用来解释呢?
- 更何况,为什么AMD用老一代HD工艺制造一个尺寸不那么大的核心,单线程绝对性能与能效都可以约等于持平Intel的N3B HP核心呢,这背后是多么大的微架构设计能力乃至整个半导体工程能力的差距?
- 上面3条是针对Arrow Lake的Lion Cove大核心,但Skymont小核心也并没有达到一个优秀的水准。
- 在8核心测试里,255H的Skymont凭借着N3B + 8 MB L2 + 24 MB L3,相比HX 370的Zen5c仅仅只有N4P + 8 MB L2 + 8 MB L3具有巨大的规格优势。
- 然而最终的多线程测试结果却展现出Intel多年以来引以为傲的小核心战略并没能成功击败AMD的dense core,哪怕拥有这么多得天独厚的条件。
我想,这样的测试结果充分暴露了Intel在微架构研发环节的颓势,已经到了TSMC先进工艺都救不回来的程度,正如本文标题所述。
halo上了新硅互联,差距可能更远了
极客湾测过,笔吧测过,金猪测过,你这Lion Cove ipc不如zen5全网仅此一家
首先,我不知道你有没有读过哪怕一遍文章,我测得的255H Lion Cove在5.1GHz默频和锁定4.8GHz这两个点上都比HX 370 Zen 5要强几个百分点,测得略低于Zen 5的是3.8 GHz这个点,而你提到的这些媒体都没有做多个频点的对比测试。事实上本文也没有把这几个点的差异拿来做什么文章,这点差异不过是误差级别而已。
其次,他们的测试条件本来就与我不同。比如笔吧用的Intel工程机+Windows+WSL+GCC 13的组合,而我文中提到过工程机测试潜在问题。此前我在WSL环境下测试过Zen 5发现性能折损比较大,因此为了准确对比都会在原生Linux下进行测试。
最后,如果你对我的测试有任何疑问,可以尝试用自己的机器复现并且把结果发出来反驳我,而不是在网上用着别人发的与我的测试环境完全不同的数据到处发无厘头的评论带节奏却拿不出任何有价值的内容,谢谢。
HX 370 的 Zen 5 和 9950/995x3D 的 Zen5 不一樣啊
大的是L3, FPU width, 小的似乎還有一些不過可能只能算 noise
赞同主包,无水平的喷子太多
英特尔特色
很好奇255h在linux下的单核频率如何。目前跑一下比较吃单核的应用又对能耗敏感,看上了零刻的hx370小主机和nuc 15 pro,但是现在没有255h的具体频率数据。这两个小主机伯仲之间很难取舍,尤其是hx370可以轻松pbo到四核5.35ghz再降压30,能耗比巨幅领先
255H的单线程频率不用太担心,我在正式开始测试之前单独记录过一轮SPEC的频率,基本上可以跑满标称的5.1 GHz
列举一些功耗压力比较大的子项
500:
{“counter-value” : “37843.486252”, “unit” : “msec”, “event” : “cpu-clock”, “event-runtime” : 37843760808, “pcnt-running” : 100.00, “metric-value” : “0.999432”, “metric-unit” : “CPUs utilized”}
{“counter-value” : “192565007572.000000”, “unit” : “”, “event” : “cycles”, “event-runtime” : 37843760808, “pcnt-running” : 100.00, “metric-value” : “5.088458”, “metric-unit” : “GHz”}
{“counter-value” : “31552.679863”, “unit” : “msec”, “event” : “cpu-clock”, “event-runtime” : 31552718323, “pcnt-running” : 100.00, “metric-value” : “0.999537”, “metric-unit” : “CPUs utilized”}
{“counter-value” : “160572386017.000000”, “unit” : “”, “event” : “cycles”, “event-runtime” : 31552718323, “pcnt-running” : 100.00, “metric-value” : “5.089025”, “metric-unit” : “GHz”}
{“counter-value” : “55075.873368”, “unit” : “msec”, “event” : “cpu-clock”, “event-runtime” : 55076028775, “pcnt-running” : 100.00, “metric-value” : “0.999753”, “metric-unit” : “CPUs utilized”}
{“counter-value” : “279715837140.000000”, “unit” : “”, “event” : “cycles”, “event-runtime” : 55076028775, “pcnt-running” : 100.00, “metric-value” : “5.078736”, “metric-unit” : “GHz”}
525:
{“counter-value” : “43576.607434”, “unit” : “msec”, “event” : “cpu-clock”, “event-runtime” : 43576907451, “pcnt-running” : 100.00, “metric-value” : “0.999344”, “metric-unit” : “CPUs utilized”}
{“counter-value” : “221619169033.000000”, “unit” : “”, “event” : “cycles”, “event-runtime” : 43576907451, “pcnt-running” : 100.00, “metric-value” : “5.085737”, “metric-unit” : “GHz”}
{“counter-value” : “40512.936339”, “unit” : “msec”, “event” : “cpu-clock”, “event-runtime” : 40513163610, “pcnt-running” : 100.00, “metric-value” : “0.999810”, “metric-unit” : “CPUs utilized”}
{“counter-value” : “206033235028.000000”, “unit” : “”, “event” : “cycles”, “event-runtime” : 40513163610, “pcnt-running” : 100.00, “metric-value” : “5.085616”, “metric-unit” : “GHz”}
{“counter-value” : “13870.875165”, “unit” : “msec”, “event” : “cpu-clock”, “event-runtime” : 13870927284, “pcnt-running” : 100.00, “metric-value” : “0.999844”, “metric-unit” : “CPUs utilized”}
{“counter-value” : “70492053431.000000”, “unit” : “”, “event” : “cycles”, “event-runtime” : 13870927284, “pcnt-running” : 100.00, “metric-value” : “5.082019”, “metric-unit” : “GHz”}
548:
{“counter-value” : “88941.038123”, “unit” : “msec”, “event” : “cpu-clock”, “event-runtime” : 88941221004, “pcnt-running” : 100.00, “metric-value” : “0.999770”, “metric-unit” : “CPUs utilized”}
{“counter-value” : “452257668038.000000”, “unit” : “”, “event” : “cycles”, “event-runtime” : 88941221004, “pcnt-running” : 100.00, “metric-value” : “5.084916”, “metric-unit” : “GHz”}
我看Kraken Point(AI 7 350)的R23多核能效曲线的低频段比Strix Point长,是不是可以说明Kraken Point机型续航会好于Strix Point?
很大概率是这样。350那种设计明显更适合日常使用,而且小核频率还高200MHz,可能从单核的角度看整个能效曲线都会比370好。
我考慮買225h主要用來做模型推論 看到你這篇有點疑義 你測試用sycl? 根據我使用dgpu a770經驗 比起genai ipexllm只有1/4的tps.
當然 225h 由於架構因素不可能差的和dgpu一樣 但是 我預估tps 也會是sycl 1.5到2倍. 你的llama.cpp方案 等同蘋果使用metal amd使用rocm方案,intel 使用閹割通用方案,這種測試是不公平的。但是,有你的測試,也讓我打消買225h 畢竟我主要還是拿來日常使用,實在拉胯
之前我在Mac的文章里有解释过这个选择的原因。各家都有比llama.cpp强不少的推理引擎,但客户端最广泛使用的工具(例如LM Studio等)和最常用的模型生态都是基于gguf/llama.cpp,因此在测试本地LLM时我会偏好于使用这些更加易用的工具而不是各家的私有方案或者vLLM/sglang这种环境配置比较麻烦的方案。尤其是像IPEX-LLM更新频率并不是很高,很多新模型并不一定能很及时支持。
除此之外,SYCL是Intel主推的第一方GPGPU compute API,与ROCm/CUDA/Metal地位相同,llama.cpp的SYCL后端也是Intel官方人员在维护(虽然最早做llama.cpp的Intel员工似乎已经跳槽去了NVIDIA)。因此这一个比较是整体比较公平的,并不存在偏袒某一家的情况,SYCL后端性能不佳也是Intel自己维护不利的锅。
谢谢你专业又详实的评测,这两年intel确实太拉夸了。不知道最新一代的amd cpu兼容性怎么样,尤其是跑专业软件会不会出现兼容性问题?我以前买过3900x,居然玩yuzu模拟器会小概率死机,这是我万万没想到的。我想买amd笔记本,但又怕踩坑,不知你在这方面有没有了解?
兼容性只能等实际的用户去慢慢踩坑了。专业软件最好还是找软件供应商的网站查询对应版本支持/推荐的硬件配置。
我的測試在
HP EliteBook 840 G10
13th Gen Intel(R) Core(TM) i7-1370P
模型 Qwen2.5-14B-Instruct-Q4_K_M.gguf
本文測試是
Intel® Core™ Ultra 7 Processor 255H
模型 Qwen2.5-14B-Instruct-Q4_K_M.gguf
iGPU 單純算力 差兩倍
i7-1370P FP32 gflops 2230
255H FP32 gflops 4460
Intel® Core™ Ultra 7 Processor 255H 支援XMX
理論上同算力 差距會更大 這還不考慮記憶體速度等額外影響
結果本文測試的 是 4.9 tokens/s
我的測試平均是 4 tokens/s
就算扣除記憶體速度
225H igpu 純算力是i7-1370P 2倍
也就是不加上 XMX 支持 再截頭去尾 本文 也應該要有 8 TPS
加上XMX 理論上 就算最悲觀 對 llm也提速2~3倍
也就是 225h 理論最悲觀 是 16 TPS左右
TPS 理論不可能是 4.9
除非這個CPU設計有嚴重瑕疵
否則 測試可能是有問題的.
=====我的程式 如下======
#openvino 2025.3.0.dev20250604
#openvino-genai 2025.3.0.0.dev20250604
import openvino_genai as ov_genai
model_path = “Qwen2.5-14B-Instruct-Q4_K_M.gguf”
device = “GPU”
pipe = ov_genai.LLMPipeline(model_path, device)
#tokenizer = pipe.get_tokenizer()
#tokenizer.set_chat_template(tokenizer.chat_template)
# 輸入與生成
prompt = “狗吃屎的原因?”
output = pipe.generate([prompt], max_length=1024)
# 顯示輸出
#print(output)
print(f”Generate duration: {output.perf_metrics.get_generate_duration().mean:.2f}ms”)
print(f’Throughput: {output.perf_metrics.get_throughput().mean:.2f} tokens/s’)
单线程Text Generation的性能主要受内存带宽影响,XMX算力基本只影响Prompt Processing。255H相比1370P在内存带宽这方面的提升并没有特别大,显然不能直接乘以算力的倍数。
補充一下, 我後來繼續測試 sycl的效能顯然比openvino低非常多, 但是 llama.cpp等流行軟體基本只支援sycl. 所以以一般”不編寫程式的”人來說sycl的確是第一選擇.
測試平台一樣是 HP EliteBook 840 G10 48G 雙通道. Intel Iris Xe Graphics
prompt: 給我 兩千字的 關於台北的 散文 ; -c 4096 -n 4096 情況下
llama.cpp(sycl 全部丟給 igpu) :3.30 tokens/s (十次平均)
openvino(僅igpu, 如之前程式 max_length 改4096) 4.50 tokens/s (十次平均)
性能差距 1.36 倍
而
=========intel ultra 225h=========
NPU Int8 tops 13
GPU TOPS(Int8)tops 74
RAM:LPDDR5X-8533
==i7-1370p (topcpu網站 數值)======
igpu 2.3 TFLOPS 換算 , 約 9.2 int8 TOPS
RAM: DDR5-5200 約前者的 60%
=============================
sycl 225h 4.9 tokens/s
sycl i7-1370p 3.30 tokens/s
約 4.9/3.3 = 1.5
根據 intel 公布的
Intel® Core™ Ultra 7 Processor 255H
baichuan2-13b-chat int4 TPS: 11.0619469
“假設”此測試為記憶體效能天花板
我們的測試 遠遠沒達到 記憶體瓶頸.
所以記憶體影響可以忽略不計
換言之 225h如果設計優良 沒有任何瑕疵
跑 Qwen2.5-14B-Instruct-Q4_K_M.gguf
在沒有瓶頸下
甚至有openvino 下 TPS可以同255h達到10
而另外以 125H
baichuan2-7b-chat INT4-MIXED 13.9275766
理論上 14b int4的模型應該可以 tps:7
225H作為125H後繼機型 理論上只會更高 我們就單以125h看
應該 openvino 下, 悲觀估計 TPS 7 , 樂觀估計TPS:10
換言之以你我的測試結果
llama.cpp用 sycl 比起openvino 效能
在igpu 下 的確是非常的低下 差距約 1.4倍
結論:
1. llama.cpp(sycl)實現上無法展現225h的效能, 效能差距甚至差距openvino 40%
2. 就算llama.cpp(sycl)可以完全發揮 225H全力, 也頂多接近 HX 370, 但是現在顯然不如.
3. 225h本就算完全發揮 14B模型 TPS頂多10 達不到實用水準
4.堪用的 只有m4, 不論AMD, INTEL都不該拿來跑本地大模型 應該要乖乖買dgpu